模型ks_一种基于XGB+LR评分模型的工程化方法
按照惯例,在写一篇自嗨的文章之前,总要酝酿一下前戏,哦不,是前言,是为下:众所周知,传统金融领域在制作信用卡评分模型时,最常用的是logistic,简单直观且比较容易做业务上的特征解释。自互联网金融兴起后,构建评分模型的特征变量呈现几何级数增长,包括金融属性相关的强变量(如人行征信报告,黑名单,共债等),以及非金融属性相关的弱变量(如客群特征,互联网消费行为等),因此单纯靠只具备线性特征的logistic模型,已经无法提升预测准确性,机器学习算法便应运而生,其中比较典型的包括两类:一类是以bagging为代表的机器学习算法,randomforest是其中代表;另外一类以boosting为代表,包括adboost;GBDT和XGBoosting,就预测精度和使用广泛性而言,XGBoosting最具有代表性,本文即以XGBoosting(下简称XGB)实现评分模型制作。主要步骤包括:
1. XGB模型训练
2. XGB模型验证
3. XGB模型文件格式化
4. XGB输出概率工程化
4. XGB输出概率的校正
5. 在线部署流程
废话不多,直接上代码。
1. XGB模型训练
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn import datasets
from pandas import DataFrame
from scipy import stats
from sklearn.linear_model import LogisticRegression
import statsmodels.formula.api as smf
np.random.seed(2)
n=100
df = pd.DataFrame({'x1':np.random.randn(n),
'x2': np.random.randn(n),
'x3': np.random.randn(n),
'label': np.random.randint(0,2,n)})
X = DataFrame(df[['x1','x2','x3']])
y = DataFrame(df['label'])
yt = len(df[df['label']==1])
print (float(yt/n))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
dtrain=xgb.DMatrix(X_train,label=y_train)
dtest=xgb.DMatrix(X_test)
params={'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth':4,
'lambda':10,
'subsample':1,
'colsample_bytree':1,
'min_child_weight':2,
'eta': 0.025,
'seed':0,
'nthread':8,
'silent':1}
watchlist = [(dtrain,'train')]
bst=xgb.train(params,dtrain,num_boost_round=10,evals=watchlist) #此处round设置为10只是为了说明后面的模型文件,一般最好设置为100左右
yprob=bst.predict(dtrain)
yprob = DataFrame(yprob)
yprob.columns = ['yprob']
y_train_new = DataFrame(y_train.reset_index())
KS_com_train = pd.concat([y_train_new,yprob],axis=1)
prob1 = KS_com_train['yprob'][KS_com_train['label']==1]
prob2 = KS_com_train['yprob'][KS_com_train['label']==0]
KS_train = stats.ks_2samp(prob1,prob2)
代码简要说明:先随机产生一个数据集,包括三个特征变量和一个标签变量,然后初始化XGB参数(注意,以上代码参数可以通过for循环,得到最优化参数解,最优指标可以用测试集KS或AUC最大值作为指标),最后计算训练集KS为0.48.
2. 模型验证
yprob_test=bst.predict(dtest)
yprob_test = DataFrame(yprob_test)
yprob_test.columns = ['yprob']
y_test_new = DataFrame(y_test.reset_index())
KS_com_test = pd.concat([y_test_new,yprob_test],axis=1)
prob1 = KS_com_test['yprob'][KS_com_test['label']==1]
prob2 = KS_com_test['yprob'][KS_com_test['label']==0]
KS_test = stats.ks_2samp(prob1,prob2)
得到KS=0.30,测试集KS值尚可。
3. XGB模型文件格式化
接下来,我们把模型预测结果输出为txt文件,代码非常简单:
model_txt = bst.dump_model("E:Pythonmodel_XGB.txt")
Boost0部分结果如下显示:
booster[0]:
0:[x2<-0.263008118] yes=1,no=2,missing=1
1:[x1<0.545256197] yes=3,no=4,missing=3
3:leaf=0.00873015914
4:leaf=-0
2:[x3<-0.309181809] yes=5,no=6,missing=5
5:[x2<0.497682899] yes=7,no=8,missing=7
7:leaf=-0.0100000007
8:leaf=-0.00094339624
6:[x1<-0.378380954] yes=9,no=10,missing=9
9:leaf=0.00600000005
10:[x2<0.949472785] yes=11,no=12,missing=11
11:leaf=-0.00416666688
12:leaf=0.00208333344
对应的图形如下:

看上去比较复杂,比如,对于第一个测试数据(print (X_test)),x1=-0.637655, x2=0.751965 x3=1.132746,根据上面的tree图,落入到leaf=0.00600000005中去。如何知道所有20个测试样本在boost=10的条件下,落入到哪个leaf呢? 可以通过如下简单代码观察一下:
ypred_leaf = bst.predict(dtest, pred_leaf=True)
结果如下:

例如:对于第一个测试样本,上图一共 5个9和5个11,第一个9对应的是模型文件boost0的9:leaf=0.00597001053,同样,第六个11对应boost5的11:leaf=0.00585176004,第一个测试样本对应的总的分值:booster0--booster4的9:leaf=0.00597001053加上booster5--booster9的11:leaf=0.00585176004,加总得到:0.00597001053*5+0.00585176004*5=0.059109。另外一方面,我们预测测试数据的“概率”:
ypred=bst.predict(dtest)
print (ypred)
得到第一个测试数据的值=0.5146635,那么由leaf加总得到的分值0.059109和“概率”0.5146635是什么关系呢?答案很简单:在使用xgboost模型最开始, 模型初始化的时候, 我们就设置了'objective': 'binary:logistic', 因此使用函数将累加的值转换为实际的打分:
f(x) = 1/(1+exp(-x))
即:0.5146635=1/(1+exp(-0.059109))
至此,我们已经完全知道XGB输出的tree图,predict概率和leaf加总分值之间的关系。
4. XGB输出概率工程化
但是,由于以上所有代码都是在离线状态下训练完成的,因此要想把最后的tree图转成可以上线实时部署,需要有一个转换,类似的方式如下:
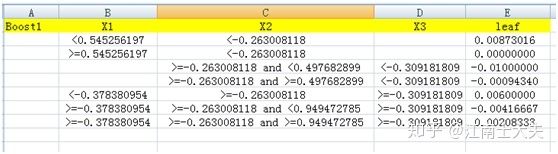
即:对于每一个boost(该演示模型一共10个boost),我们可以通过人肉的方式,清理出每个boost的tree图对应的特征条件以及相应的leaf分值,然后把所有满足特征的leaf分值加总求和,就可以得到一个“概率”。
上面excel显然是风控部门需要维护的核心算法文件,但是如果特征变量数太多,比如超过10个,那么维护成本将会成倍增加,笔者通过比较各种维护成本所对应的方式,发现SQL是比较快捷简单,这里摘录一个大神的代码(非本人所创):
xgb_json = bst.get_dump(dump_format='json')
with codecs.open("E:Pythonmodel_XGB_json.json", 'w', encoding="utf-8") as f:
for single_json in xgb_json:
single_json = single_json.replace('n',' ').replace('r', ' ')
f.write(single_json + 'n')
## 解析单棵数
def parse_xgb_tree_2sql(xgb_tree_json, mid_sqls, tree_num, depth=0):
indent = " " * (depth+1) ## 用于对齐sql语句
if 'leaf' in xgb_tree_json.keys():
leaf_value = xgb_tree_json['leaf']
if(len(mid_sqls)>=1 and 'else' in mid_sqls[-1]):
cur_sql = indent + str(leaf_value) + ' '
else:
cur_sql = indent + str(leaf_value)
mid_sqls.append(cur_sql)
return
feat = xgb_tree_json['split']
value = str(xgb_tree_json['split_condition'])
left_tree = xgb_tree_json['yes']
right_tree = xgb_tree_json['no']
missing = xgb_tree_json['missing']
if missing == left_tree:
cur_sql = '(' + feat + ' is null' + ' or ' + feat + ' < ' + value + ')'
mid_sqls.append( "{}case when {} thenn".format(indent, cur_sql) )
parse_xgb_tree_2sql(xgb_tree_json['children'][0], mid_sqls, tree_num, depth+1)
cur_sql = '(' + feat + ' >= ' + value + ') '
mid_sqls.append( "n{}elsen".format(indent) )
parse_xgb_tree_2sql(xgb_tree_json['children'][1], mid_sqls, tree_num, depth+1)
mid_sqls.append("n{}end".format(indent))
elif missing == right_tree:
cur_sql = '(' + feat + ' is null' + ' or ' + feat + ' >= ' + value + ')'
mid_sqls.append( "{}case when {} thenn".format(indent, cur_sql) )
parse_xgb_tree_2sql(xgb_tree_json['children'][1], mid_sqls, tree_num, depth+1)
cur_sql = '(' + feat + ' < ' + value + ') '
mid_sqls.append( "n{}elsen".format(indent) )
parse_xgb_tree_2sql(xgb_tree_json['children'][0], mid_sqls, tree_num, depth+1)
mid_sqls.append("n{}end".format(indent))
else:
print ("something wrong.")
## 解析模型文件
def parse_xgb_trees(xgb_trees_josn):
tree_sqls = []
idx = 0
for single_tree in xgb_trees_josn:
mid_sqls = []
parse_xgb_tree_2sql(json.loads(single_tree), mid_sqls, idx, 0)
tree_sql = ''
for t_sql in mid_sqls:
tree_sql = tree_sql + t_sql
tree_sql = tree_sql + ' as ' + 'tree_' + str(idx) + '_score,'
idx += 1
tree_sqls.append(tree_sql + 'n')
tree_sqls[-1]=tree_sqls[-1][:-2]
return tree_sqls
if __name__ == '__main__':
with open("E:Pythonmodel_XGB_json.json", 'r') as f_read:
xgb_json = f_read.readlines()
tree_sqls = parse_xgb_trees(xgb_json)
final_sqls = ''
for item_sql in tree_sqls:
final_sqls = final_sqls + item_sql
with codecs.open("E:Pythonmodel_XGB_json.sql", 'w', encoding="utf-8") as f:
for item_sql in tree_sqls:
f.write(item_sql + 'n')
print (final_sqls)
以上代码本人亲测有效,结果会输出一个SQL语句。
4. XGB输出概率的校正
细心的读者会发现,刚才本人一直用带有引号的“概率”来表达XGB输出,实际上,通过加总leaf分值得到的“概率”并非真实概率,在所有机器学习算法中,只有logistic的概率是真实概率,这是有各模型算法本身原理决定的,无论是bagging还是boosting,本质上都是一个加法模型,只有logistic才是真正的“概率模型”,因此,如果要想把XGB的输出概率转成真实的概率,还需要一道手续,就是通过logistic模型进行二次转换。
由于XGB的输出概率是leaf分值加总后通过函数f(x) = 1/(1+exp(-x))转换得到,因此我们只需要知道每个测试样本的leaf分值加总值即可。而leaf分值加总又是可以通过SQL语句得到,因此对于每个测试样本,只需要执行SQL语句即可。假定执行结果如下:
[0.5146635 0.5 0.52178705 0.49506977 0.5 0.5
0.52178705 0.49770555 0.49770555 0.49663216 0.51173383 0.51173383
0.5 0.52178705 0.5146635 0.49506977 0.51173383 0.49506977
0.49770555 0.52178705]
上面list中每个值是leaf通过SQL语句加总分值得到,然后我们只需要运行简单的logistic代码:
modelLR=LogisticRegression(solver='liblinear')
modelLR = modelLR.fit(X,y)
b=modelLR.coef_
a=modelLR.intercept_
其中:X为XGB输出的leaf加总分值,y为测试数据集的label。
最终得到的真实概率如下:
prob = 1/(1+exp(-X)) = 1/(1+exp(-(a+b*X)))
有了这个prob,接下来就可以建立评分模型了,建立方法网上很多材料,简要介绍如下:

假定根据基准分为600,PDO=20,先验概率=1:60,计算得:
A=481.89
B=28.85
Score=A-B*log(P/(1-P))
5. 在线部署流程
总结如下:
step1:训练模型,得到模型文件和可执行的SQL语句;
step2:清洗预测数据的特征变量,得到和训练模型一模一样的特征集;
step3:决策引擎部署SQL对应的特征变量策略;
step4:对预测数据实时线上通过决策引擎打分