Impala安装部署(超详细!)
Impala安装部署
温馨提示:建议安装之前先给集群快照。(安装Impala时,Impala会重新安装hadoop等组件,可能导致集群混乱)
1.安装前提
集群提前安装好hadoop,hive。
hive安装包scp在所有需要安装impala的节点上,因为impala需要引用hive的依赖包。
hadoop框架需要支持C程序访问接口,查看下图,如果有该路径下有这么文件,就证明支持C接口。
2.下载安装包、依赖包
由于impala没有提供tar包进行安装,只提供了rpm包。因此在安装impala的时候,需要使用rpm包来进行安装。rpm包只有cloudera公司提供了,所以去cloudera公司网站进行下载rpm包即可。
但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,也可以将所有的rpm包下载下来,制作成我们本地yum源来进行安装。这里就选择制作本地的yum源来进行安装。
所以首先需要下载到所有的rpm包,下载地址如下
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
3.虚拟机新增磁盘(可选)
由于下载的cdh5.14.0-centos6.tar.gz包非常大,大概5个G,解压之后也最少需要5个G的空间。而我们的虚拟机磁盘有限,可能会不够用了,所以可以为虚拟机挂载一块新的磁盘,专门用于存储的cdh5.14.0-centos6.tar.gz包。
4.配置本地yum源信息
安装Apache Server服务器
yum -y install httpd
service httpd start
chkconfig httpd on
配置本地yum源的文件
cd /etc/yum.repos.d
vim localimp.repo
[localimp]
name=localimp
baseurl=http://局域网yum源的IP/解压后的压缩包名(我的是cdh)
gpgcheck=0 (说明:是否检查 0=不检查)
enabled=1 (说明:是否启用 1=启用)
创建apache httpd的读取链接
ln -s /cloudera_data/cdh/5.14.0 /var/www/html/cdh5.14.0
确保linux的Selinux关闭
永久关闭:
[root@localhost ~]# vim /etc/selinux/config
SELINUX=enforcing 改为 SELINUX=disabled
重启服务reboot
通过浏览器访问本地yum源,如果出现下述页面则成功。
http://局域网yum源的IP/cdh5.14.0/
将本地yum源配置的repo文件发放到所有需要安装impala的节点。
cd /etc/yum.repos.d/
scp 刚才编辑过的repo文件 从节点1:$PWD
scp 刚才编辑过的repo文件 从节点2:$PWD
5.安装Impala
主节点安装
yum install -y impala impala-server impala-state-store impala-catalog impala-shell
从节点安装
yum install -y impala-server
下载nc
yum -y install nc
6.修改Hadoop、Hive配置
需要在3台机器整个集群上进行操作,都需要修改。hadoop、hive是否正常服务并且配置好,是决定impala是否启动成功并使用的前提。
6.1 修改hive配置
可在主节点机器上进行配置,然后scp给其他2台机器。
vim /export/servers/hive/conf/hive-site.xml(我的hive解压目录是在/export/servers下)
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node-1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
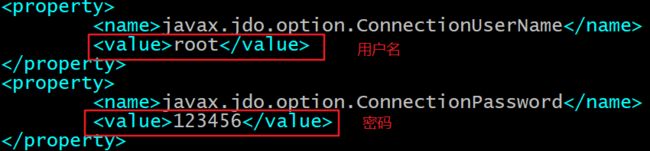
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
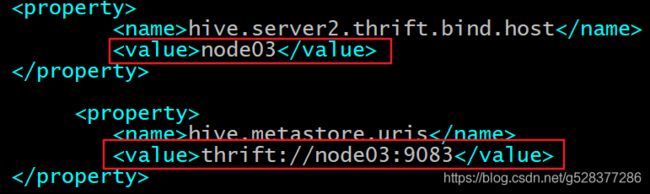
<!-- 绑定运行hiveServer2的主机host,默认localhost -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node-1</value>
</property>
<!-- 指定hive metastore服务请求的uri地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node-1:9083</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
</configuration>

将hive安装包cp给其他两个机器。
cd /export/servers/
scp -r hive/ node02:$PWD
scp -r hive/ node03:$PWD
6.2 修改hadoop配置
所有节点创建下述文件夹
mkdir -p /var/run/hdfs-sockets
修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
vim /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
dfs.client.read.shortcircuit 打开DFSClient本地读取数据的控制,
dfs.domain.socket.path是Datanode和DFSClient之间沟通的Socket的本地路径。
把更新hadoop的配置文件,scp给其他机器。
cd /export/servers/hadoop-2.7.5/etc/hadoop
scp -r hdfs-site.xml node-2:$PWD
scp -r hdfs-site.xml node-3:$PWD
注意:root用户不需要下面操作,普通用户需要这一步操作。
给这个文件夹赋予权限,如果用的是普通用户hadoop,那就直接赋予普通用户的权限,例如:
chown -R hadoop:hadoop /var/run/hdfs-sockets/
因为这里直接用的root用户,所以不需要赋权限了。
6.3 复制hadoop、hive配置文件
impala的配置目录为**/etc/impala/conf**,这个路径下面需要拷贝core-site.xml,hdfs-site.xml以及hive-site.xml。
cp -r /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
cp -r /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
cp -r /export/servers/hive/conf/hive-site.xml /etc/impala/conf/hive-site.xml
将conf这个目录远程拷贝到其它所有节点
7. 修改impala配置
7.1 修改impala默认配置
所有节点更改impala默认配置文件
vim /etc/default/impala
IMPALA_CATALOG_SERVICE_HOST=node03
IMPALA_STATE_STORE_HOST=node03
7.2 添加mysql驱动
通过配置**/etc/default/impala**中可以发现已经指定了mysql驱动的位置名字。
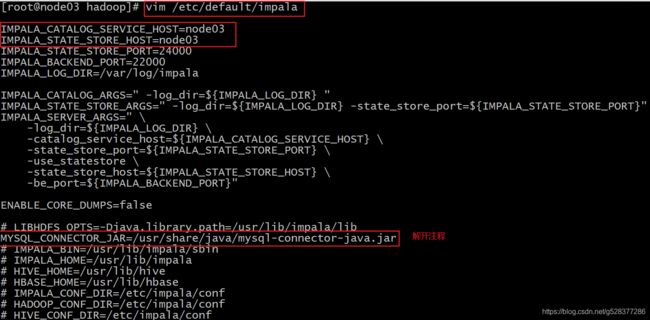
使用软链接指向该路径即可(3台机器都需要执行)
ln -s /export/servers/hive/lib/mysql-connector-java-5.1.32.jar /usr/share/java/mysql-connector-java.jar
7.3 修改bigtop配置
修改bigtop的java_home路径(3台机器)
vim /etc/default/bigtop-utils
export JAVA_HOME=${JAVA_HOME}
重启hadoop、hive
在主节点上执行下述命令分别启动hive metastore服务和hadoop。
cd /export/servers/hive
nohup bin/hive --service metastore & (&:在后台执行)
nohup bin/hive --service hiveserver2 &
cd /export/servers/hadoop-2.7.5/
sbin/stop-dfs.sh | sbin/start-dfs.sh
8. 启动、关闭impala服务
主节点启动以下三个服务进程
service impala-state-store start
service impala-catalog start
service impala-server start
从节点启动impala-server
service impala-server start
查看impala进程是否存在
ps -ef | grep impala
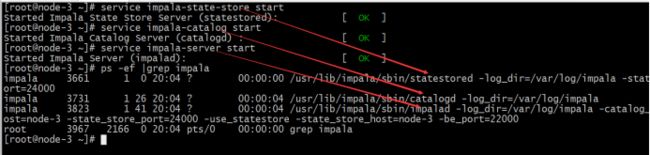
启动之后所有关于impala的日志默认都在**/var/log/impala**
如果需要关闭impala服务 把命令中的start该成stop即可。注意如果关闭之后进程依然驻留,可以采取下述方式删除。正常情况下是随着关闭消失的。
解决方式:
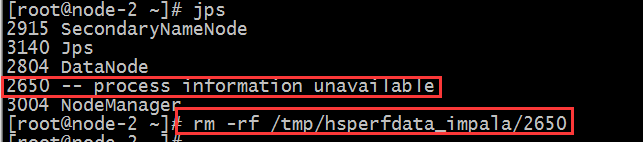
8.1 impala web ui
访问impalad的管理界面http://node-3:25000/
访问statestored的管理界面http://node-3:25010/
impala-shell命令参数
主节点输入impala-shell进入shell窗口
![]()
当看到主机名和端口号时,安装部署就完成了!