14课时 Pandas 如何处理丢失数据。
很多消失数据。用np.nan。
.dropna(axis=0,how=‘any’) #how={‘any’,‘all’} axis=0是丢掉行。How =any是只要有任何一个为nan就丢掉整行了。后面的all 是整个行的所有列都为nan才丢失这个行,默认是how=any。 Axis=1是丢掉列。.dropna(axis=0,how=‘all’)
注:.dropna 这里没有n。
并且最后要打印 print(-.dropna函数)
Print(np.any(df.isnull()==True)#就可以很快的查看是否丢失了数据,最后会返回时否为true,会。
15课时 Pandas导入导出数据
1 如何调用已经存储好的数据表格类
2 excel一般用csv

3 data=pd.read_csv(‘名.csv’)
Print(data) #默认加行索引,今后可以用这个索引和column来调用数据 要用data=来命
data.to_pickle(‘studen.picklet’) #存储 运行此行命令即可。

4 jupyter 工作路径的查看
在cmd中,输入“ipython notebook”或“jupyter notebook”打开notebook,此时cmd的当前路径即为notebook的工作路径。
另外,可通过设置config文件的方法来设置固定的工作路径
16课时 Pandasconcat 合并
合并多个dataframe 可以横向纵行,即可columns的命不一样
用pandas 和numpy
#concatenating
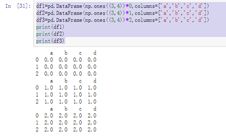
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3=pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
print(df1)
print(df2)
print(df3)
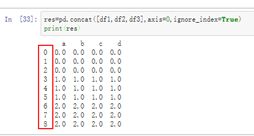
res=pd.concat([df1,df2,df3],axis=0,ignore_index=True) #pd中 记住 axis的代表,合并函数,axis=0 代表行都合并成多行,在行上进行合并,axis=1代表在列上面进行合并, ignore 可以让前面的index重新顺序,而非之前的index。
print(res)
# join,[‘inner’,’outer’]
默认是outer 就是说列上面没有的写为空
而inner是合并的时候,只合并列里面都有列,行保持不变累加。
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['e','b','c','d'])
res=pd.concat([df1,df2],join='inner',ignore_index=True)
print(res)

#join_axes
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
res=pd.concat([df1,df2],axis=1,join_axes=[df1.index])
print(res)