大数据技术(一):Hadoop 环境搭建
一、了解Hadoop
关于Hadoop的官方说明是:Apache Hadoop 是一款支持 数据密集型 分布式 应用程序并以 Apache 2.0 许可协议发布的 开源软体框架。拆开来说,其中包含学习 Hadoop 必须要理解的三个知识点:
(1)Hadoop是一个框架;
(2)可以用来处理大规模数据;
(3)Hadoop被部署在集群上。
二、Hadoop
传统意义上,我们常说的Hadoop是包含了 Common,HDFS,YARMN 和 MapReduce 的一个整体框架。其实在学习以后我们要了解的是整个 Hadoop 生态圈。整个生态圈的发展都是围绕 Hadoop 进行的,生态圈包含的组件如下图。
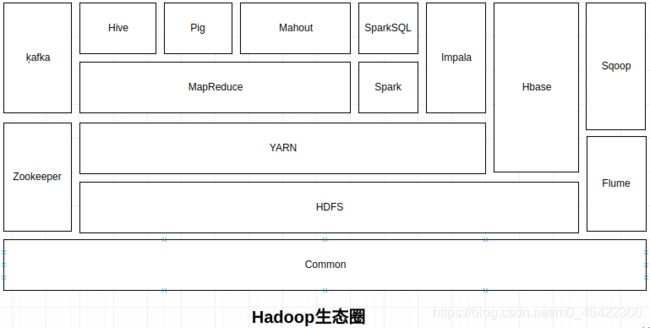
下面简单介绍一下生态圈中各个组件的相关用途。
1)Hadoop Common
Hadoop Common 是Hadoop 体系最底层的一个模块,为 Hadoop的各个子项目提供工具,如:系统配置工具、远程过程调用RPC、序列化机制、日志操作等。
2)HDFS
HDFS 全称是 Hadoop分布式文件系统 ,是指被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
3)YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
4)MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
5)Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。总而言之,Spark 比 Hadoop 2.x 快。因为 Hadoop 3.x 将优化一些设计,谁更快还不知道。
6)HBase
HBase是一个开源的、分布式的、面向列的非关系型分布式数据库(NoSQL),它是一个适合于非结构化数据存储的数据库。
7)Hive
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
8)Pig
Pig 与Hive 类似,也是一种对大型数据集进行分析和评估的工作,使用的语言是 Pig Latin。Pig 可以将Pig Latin 脚本转换为 MapReduce ,这个语言比较灵活,但是学习成本比较高。
9)Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。Impala 的计算不是基于MapReduce的,相对而言计算速度比Hive快一点。
10)Mahout
Mahout 是一个机器学习和数据挖掘库,提供多种经典算法的实现,并具有良好的扩展性。
11)Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
12)Sqoop
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导入到Hadoop的HDFS中并存储在Hive和HBase表格中,也可以将HDFS的数据导入到关系型数据库中。Sqoop配合Ooozie能够帮助你调度和自动运行导入导出任务。
13)Kafka
Kafka 是一种高吞吐量的分布式发布订阅消息系统。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
14)Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。Hadoop生态圈中多个组件的 HA (高可用)模式都必须借助 ZooKeeper 来搭建。
Hadoop 生态圈的内容很多,有些人觉得学起来很累,其实不然,只要弄清楚各个组件的作用,在数据处理过程中扮演的角色,最好是凭自己的理解画一个架构图,这样学习起来会很快。

二、准备环境
学习搭建某工具环境的时候,一般都是在自己的电脑的虚拟环境中进行,因此使用各种虚拟化工具是必须要求的技能。因为这个过程会出现许多问题,我们能在处理这些问题时积攒许多宝贵的经验。这就是我在接受有挑战的工作任务时,不会退缩的主要原因。也是我为什么经常加班的原因。。。
1) 准备 CentOS 7 虚拟机
安装环境虚拟化环境,可以参考文章《使用 VirtualBox 安装 CentOS7 系统》,来搭建自己的虚拟化环境。
大部分初学者一般使用的都是VM虚拟机,相对而言VirtualBox是轻量级的平台,功能简单更容易上手使用,推荐大家尝试使用。
2) 安装 JDK1.8
- 检查是否安装openJDK,并卸载;
rpm -qa|grep java

//卸载命令
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
//或者使用以下命令一次性卸载
rpm -e --nodeps ‘rpm -qa | grep java’
- 获取 JDK1.8 linux 环境安装包:官方下载,CSDN下载;
- 上传JDK安装包到虚拟机的 opt 目录;
- 使用解压命令解压到当前位置;
tar -zxvf jdk-8u201-linux-x64.tar.gz
- 配置环境变量:
//编辑环境变量配置文件:
vim /etc/profile
//添加以下内容:
#JDK1.8
export JAVA_HOME=/opt/jdk1.8.0_201
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
- 刷新环境变量:
source /etc/profile
- 测试安装结果
java -version
- 结果如下,安装成功!
[root@hadoop00 opt]# java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
3) 复制虚拟机两台(全分布环境使用)
(1)选择安装好的Linux虚拟机进行复制。
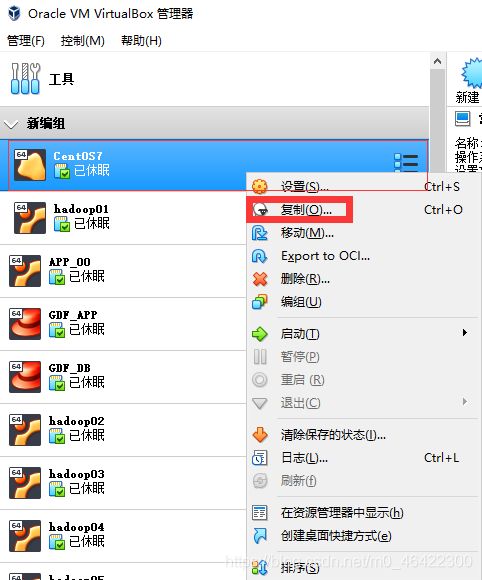
(2)修改复制后的虚拟机名称(复制的虚拟机分别命名为hadoop01、hadoop02),并重置MAC。

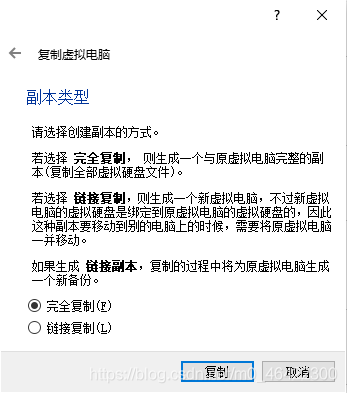
(3)完全复制
4) 设置主机名
//设置主机名为hadoop00
hostnamectl set-hostname hadoop00
//重启虚拟机
reboot
5) 配置静态IP
//打开文件,修改或添加以下内容,文件名会随网卡名变化,可以通过ifconfig命令查看
[root@hadoop00 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
------------
BOOTPROTO=static //静态IP
ONBOOT=yes //开机启用
IPADDR=192.168.56.160 //配置IP
6) 配置Hosts文件
//修改配置文件
vi /etc/hosts
//根据你自己的IP设置,添加以下内容
192.168.56.160 hadoop00
192.168.56.161 hadoop01
192.168.56.162 hadoop02
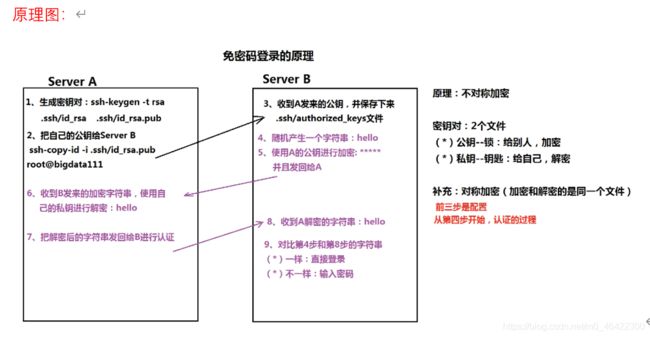
7) 配置SSH无密码连接
1. 生成密钥对:
ssh-keygen -t rsa
2. 复制公钥给对应服务器:
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop00(需要输密码确认)
3. 收到公钥并保存在新文件中(查看authorized_keys)
4. 使用 ssh 命令检查是否实现免密码登录。
ssh hadoop00 //回车直接进入系统
8) 获取Hadoop安装包
获取 Hadoop 安装包:大数据技术系列_Hadoop_2.7.3_安装包,每次设置 0 积分都会被系统改掉,可以去官网下载。
三、安装Hadoop
1)本地模式
1、解压完成以后直接运行
//准备测试文件
vim /opt/demo.input //打开后直接输入一些单词,然后保存退出
//进入hadoop安装目录
cd /opt/hadoop-2.7.3
//执行demo
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /opt/demo.input output1
//查看输出文件
ll output1
2)伪分布式安装
1、修改Hadoop 配置文件,配置文件位置:/opt/hadoop-2.7.3/etc/hadoop
1)hdfs-site.xml
dfs.replication
1
dfs.permissions
false
2)core-site.xml
fs.defaultFS
hdfs://hadoop00:9000
hadoop.tmp.dir
/root/tools/hadoop-2.7.3/tmp
- mapred-site.xml
mapreduce.framework.name
yarn
- yarn-site.xml
yarn.resourcemanager.hostname
hadoop00
yarn.nodemanager.aux-services
mapreduce_shuffle
2、格式化HDFS
格式化命令:hdfs namenode -format
3、启动Hadoop并验证
启动命令:start-all.sh
//控制台输出:
[root@hadoop00 ~]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [hadoop00]
hadoop00: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-namenode-hadoop00.out
localhost: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop00.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-hadoop00.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-resourcemanager-hadoop00.out
localhost: starting nodemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop00.out
//使用JPS命令查看相关进程,完整的伪分布模式运行起来以后有五个相关进程
[root@hadoop00 ~]# jps
3796 NodeManager
3210 NameNode
4091 Jps
3532 SecondaryNameNode
3341 DataNode
3693 ResourceManager
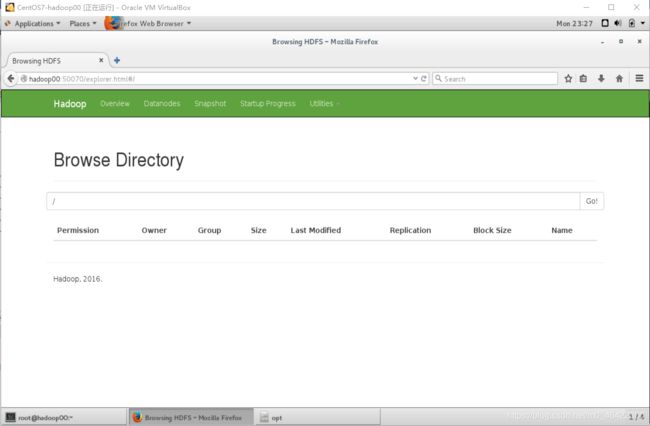
4、Hadoop可视化界面:http://hadoop00:50070,,可以在 Utilties =》Browse the file system中查看文件系统,并下载。
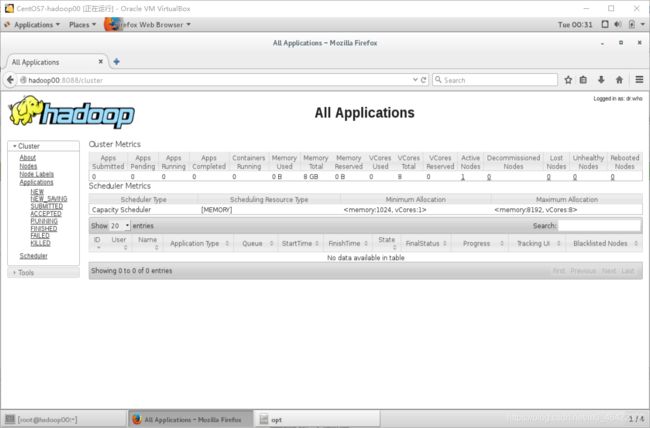
5、Yarn管理界面:http://hadoop00:8088
3)全分布式安装
1、参照环境准备第三条完全复制两台虚拟机,注意一定要重置MAC地址;
//虚拟机规划配置:主机名、IP、功能说明
hadoop00 192.168.56.160 主节点
hadoop01 192.168.56.161 从节点1
hadoop02 192.168.56.162 从节点2
2、两天新虚拟机修改主机名、IP、配置hosts、免密登陆;
//分别修改主机名,重启生效
hostnamectl set-hostname hadoop01
hostnamectl set-hostname hadoop02
//分别配置静态IP,重启网卡生效
IPADDR=192.168.56.161
IPADDR=192.168.56.162
//分别配置 hosts 文件,文件底部添加
192.168.56.160 hadoop00
192.168.56.161 hadoop01
192.168.56.162 hadoop02
//免密登陆
//第一步:生成密钥对(新生成的服务器都需要执行):
ssh-keygen -t rsa
//第二步:复制公钥给对应服务器(每台服务器都需要执行,需要输入密码确认):
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop00
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop01
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop02
//第三步:分别使用 ssh 命令检查是否实现免密码登录。
ssh hadoop00
ssh hadoop01
ssh hadoop02
3、停用hadoop00上的Hadoop伪分布式服务,重新将安装包解压到一个新的目录中;
tar -zxf /opt/hadoop-2.7.3.tar.gz -C /opt/new
4、大部分配置都与伪分布模式一样,可以直接用修改好的文件替换过来,需要注意以下不一样的配置内容。
//hdfs-site.xml文件中副本冗余设置为3
dfs.replication
3
//slaves文件中添加新的节点,完整配置如下:
hadoop00
hadoop01
hadoop02
5、格式化NameNode
hdfs namenode -format
6、将配置好的Hadoop安装包复制到其他两个节点
scp -r hadoop-2.7.3/ root@hadoop01:/opt/new
scp -r hadoop-2.7.3/ root@hadoop02:/opt/new
7、在主节点(hadoop00)启动hadoop,启动命令:start-all.sh
8、验证安装结果:访问http://hadoop00:50070,查看节点信息。
4)Hadoop 的 HA(高可用)
虚机有点问题,搞好了再补充这块内容。
四、Hadoop 基础
1)HDFS 基础知识
1.HDFS架构说明
HDFS的架构设计图:
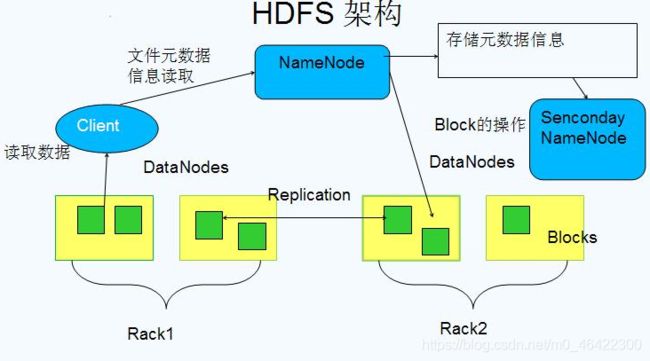 Namenode: 整个集群中只有一个namenode。它是整个系统的“总管”,负责管理HDFS的目录树和相关的文件元数据信息。
Namenode: 整个集群中只有一个namenode。它是整个系统的“总管”,负责管理HDFS的目录树和相关的文件元数据信息。
这些信息是以“fsimage”(HDFS元数据镜像文件)和"editlog"(HDFS文件改动日志)两个文件形式存放在本地磁盘,当HDFS重启时重新构造出来的。此外Namenode还负责监控各个Datanode的健康状态,一旦发现某个Datanode宕掉,则将该Datanode移出HDFS并重新备份其上面的数据。
Secondary NameNode: 最重要的任务不是为 NameNode 元数据进行热备份,而是定期合并 fsimage 和 edits 日志,并传输给 NameNode。这里需要注意的是,为了减小 NameNode 压力,NameNode 自己并不会合并 fsimage 和 edits,并将文件存储到磁盘上,而是交由 Secondary NameNode 完成。
DataNode: 一般而言,每个Slave节点上安装一个 DataNode,它负责实际的数据存储,并将数据信息定期汇报给 NameNode。DataNode 以固定大小的 block 为基本单位组织文件内容,默认情况下block 大小为 128MB。
当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个 block,分别存储到不同的DataNode;同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认是3,该参数可配置)不同的 DataNode 上。这种文件切割后存储的过程是对用户透明的。
2.HDFS 文件上传过程和机架感知
(1)HDFS 文件上传过程
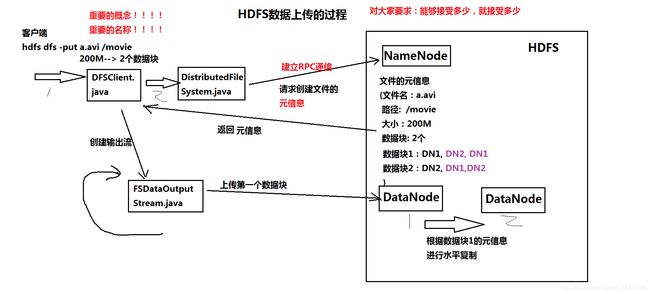
详细过程:
- 客户端向namenode通信,请求上传文件,namenode检查目标文件是否已存在,父目录是否存在,该客户端是否有上传权限。
- namenode返回是否可以上传。
- 客户端会先对文件进行逻辑切块,比如一个blok块128m,文件有300m就会被切分成3个块,一个128M、一个128M、一个44M请求第一个block该传输到哪些datanode服务器上。
- namenode返回datanode列表。
- 为上传文件做准备。构建pipline,将同一个块的所有存储节点构成一个数据流通道。
- 开始真正上传文件。上传文件过程中,边上传边切块。以packet(64kb)为单位上传,先上传到第一个datenode01的缓存中,缓存中每当接收一个packet就向本地磁盘写入,并传递给下一个结点。当第一个块上传完成后关闭通道。
- 开始上传第二个块,所有块上传完成后namenode向客户端返回结果。 所有块上传完成后,客户端告知namenode数据上传成功。
- namenode更新元数据。
(2)机架感知
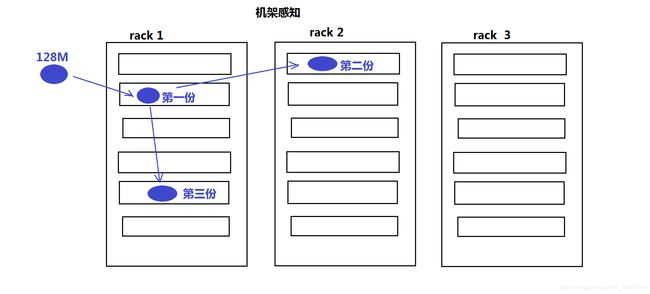 默认副本放置策略:
默认副本放置策略:
在默认情况下副本数量是3个,所有的DN都是在同一个机架下,此时写block时,三个DN机器的选择是完全随机的。
写数据:HDFS是将不同的副本放置在不同的机架上,可以防止整个机架失效时数据的丢失,并且允许读数据的时候充分利用多个机架的带宽。这种策略设置可以将副本均匀地分配到集群中,有利于组织失效情况下的均衡负载。但是,因为这种策略的一个写操作需要传输数据块到多个机架,增加了写操作的成本。
读数据:在读数据时,为了减少整体的带宽和降低整体带宽延时,HDFS会尽量读取距离客户端最近的副本。如果程序和副本在同一个机架上优先读取该副本。如果跨多个数据中心,那么HDFS也将首先读取本地数据中心的副本。
配置机架后的副本放置策略:
配置机架感知后,HDFS在选择三个DN时,就会进行相应的判断:
- 如果上传本机不是一个DN,而是一个客户端,那么就从所有slave机器中随机选择一台DN作为第一个块的写入机器(DN1)。而此时如果上传机器本身就是一个DN,那么就将该DN本身作为第一个块写入机器。
- 随后在DN1所属的机架外的另外的机架上,随机的选择一台,作为第二个block的写入DN机器(DN2)
- 在写第三个block前,先判断前两个DN是否在同一个机架上,如果是在同一个机架,那么就尝试在另外一个机架上选择第三个DN作为写入机器(DN3)。而如果DN1和DN2没有在同一个机架上,则在DN2所在的机架上选择一台DN作为DN3。(hadoop fsck xx -files -blocks -locations -racks )
- 得到三个DN的列表后,从NN返回该列表到DFSClient之前,会在NN端首先根据该写入客户端跟DN列表中每个DN之间的距离由近到远进行一个排序,客户端根据这个顺序由近到远的进行数据块的写入。
- 根据距离排好序的DN节点列表返回给DFSClient后,DFSClient便会创建Block OutputStream,并向这次block写入pipeline中的第一个节点(最近的节点)开始写入block数据
- 写完第一个block后,依次按照DN列表中的次远的node进行写入,直到最后一个block写入成功,DFSClinet返回成功,该block写入操作结束。
为什么要设置机架感知:
- 开启机架感知,NN可以知道DN所处的网络位置;
- 根据网络拓扑图可以计算出rackid,通过rackid信息可以计算出任意两台DN之间的距离;
- 在HDFS写入block时,会根据距离,调整副本放置策略;
- 写入策略会将副本写入到不同的机架上,防止某一机架挂掉,副本丢失的情况。同时可以降低在读取时候的网络I/O。但是会增加写操作的成本。
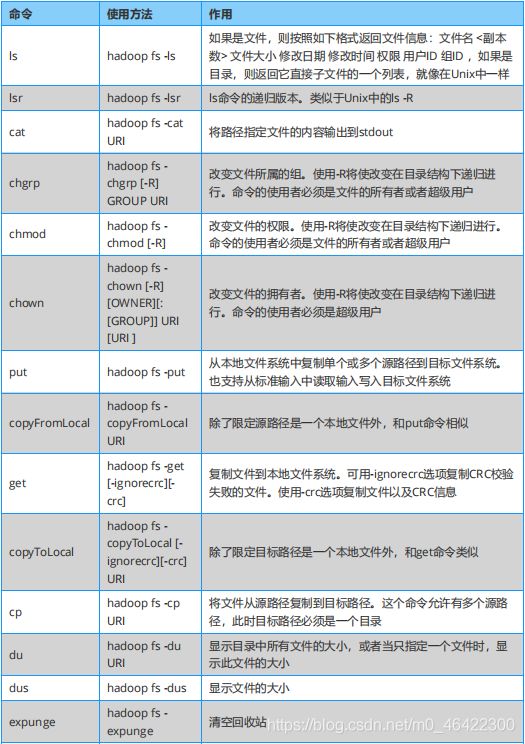
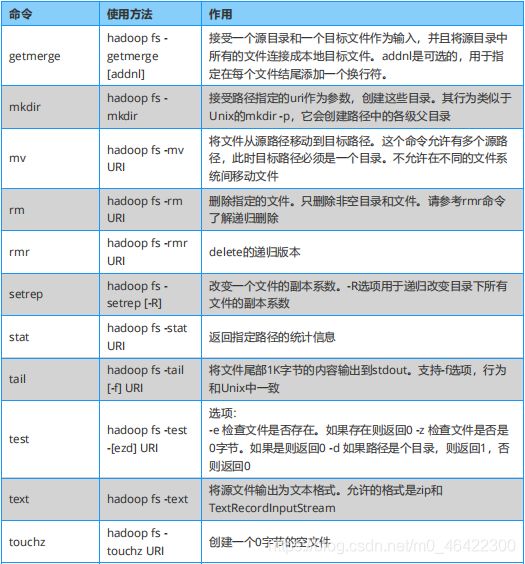
3.命令操作HDFS
hdfs的操作比较简单,这里提供一个速查表给大家,按需使用可以了。
4.Java 调用 HDFS API
这里直接发一个 Java 调用 HDFS API 的实例 。
package com.hadoop.dome;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HDFSDemo {
static Configuration conf;
static FileSystem fs;
static{
conf = new Configuration();
try {
fs = FileSystem.get(new URI("hdfs://192.168.56.200:9000"), conf);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (URISyntaxException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//创建文件夹
public static void mkdir(String name){
boolean flag = false;
try {
if (!fs.exists(new Path(name+"1"))) {
flag = fs.mkdirs(new Path(name));
}
System.out.println(flag);
if(flag){
System.out.println("文件夹创建成功");
}else{
System.out.println("文件夹创建失败");
}
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
//创建文件
public static void createFile(String file, String text){
FSDataOutputStream outputStream = null;
byte[] arg0 = text.getBytes();
try {
outputStream = fs.create(new Path(file));
outputStream.write(arg0, 0, arg0.length);
outputStream.close();
System.out.println("文件创建成功");
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
//对文件重命名
public static void rename(String oldName, String newName){
boolean flag;
try {
flag = fs.rename(new Path(oldName), new Path(newName));
if(flag){
System.out.println("文件重命名成功");
}
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
//判断文件是否存在
public static void existFile(String file){
boolean flag;
try {
flag = fs.exists(new Path(file));
if(flag){
System.out.println("存在");
}else
{
System.out.println("不存在");
}
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
//删除文件
public static void deleteFile(String file){
boolean flag;
try {
flag = fs.deleteOnExit(new Path(file));
if(flag){
System.out.println("成功删除");
}
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
public static void close(){
try {
fs.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//上传文件
public static void uploadFile(String src, String dst){
try {
fs.copyFromLocalFile(false, new Path(src), new Path(dst));
System.out.println("文件上传成功");
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
//下载文件
public static void downFile(String src, String dst){
try {
fs.copyToLocalFile(new Path(src), new Path(dst));
System.out.println("文件下载成功");
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
//读取文件
public static String readFile(String file){
String str = "";
FSDataInputStream inputStream = null;
byte[] arg0 = new byte[1024];
try {
inputStream = fs.open(new Path(file));
inputStream.read(arg0);
str = new String(arg0);
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
return str;
}
//返回指定文件夹的文件列表
public static void listName(String dir){
try {
FileStatus files[] = fs.listStatus(new Path(dir));
for(FileStatus file : files){
System.out.println(file.getPath().getName() + "\t" + file.getLen());
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
close();
}
}
public static void main(String[] args) throws IOException {
// HDFSDemo hdfs = new HDFSDemo();
// HDFSDemo.mkdir("/test/20200701");
HDFSDemo.createFile("/test/file.txt", "这是一个测试文件。。");
// HDFSDemo.createFile(args[0], args[1]);
// HDFSDemo.rename("/test/test2", "/test/test1");
// HDFSDemo.existFile("/test/3.txt");
// HDFSDemo.deleteFile("/test/5.txt");
// HDFSDemo.downFile(args[0], args[1]);
// String str = HDFSDemo.readFile("/test/3.txt");
// System.out.println(str);
// HDFSDemo.listName("/test");
}
}
5.HDFS 高级特性
(1)回收站
1、回收站默认是关闭的,需要在 core-site.xml 中配置回收站
<property>
<name>dfs.trash.interval</name>
<value>1440</value> // 注:1440 代表一天 (1440分钟)
</property>
2、开启回收站后,执行hdfs dfs -rm -R /folder 操作前后,控制台打印日志的对比。
开启前:Deleted /folder
开启后:Moved "hdfs://192.168.**.**:9000/folder" to trash " hdfs://192.168.**.**:9000/user/root/.Trash/Current"
相当于做了一次“剪切”操作,所以要找回删除的文件,直接做一次 hdfs dfs -cp ** 操作即可
同样的,oracle数据库也有回收站,当一个表被删除后,进入回收站,可以通过 flashback(闪回)恢复表。
(2)配额(Quota)
1、名称配额:限定hdfs目录下存放文件/目录的个数。
命令(都是hdfs dfsadmin 命令):
-setQuota <quota> dirName1 dirName2 dirName3 文件夹实际能够存放的文件/文件夹数量为quota-1 个
-clrQuota dirName1 dirName2 dirName3
举例(以/myQuota1文件夹为例):
hdfs dfsadmin -setQuota 3 /myquota1 设置/myquota1文件夹下最大的文件/文件夹数量为3-1=2个
hdfs dfsadmin -clrQuota /myquota1
2、空间配额:限定hdfs目录下,文件的大小。
命令:
-setSpaceQuota <quota> [-storageType storagetype] dirName1 dirName2 dirName3
-clrSpaceQuota [-storageType storagetype] dirName1 dirName2 dirName3
举例(以/myquota2为例):
hdfs dfsadmin -setSpaceQuota 2M /myquota2 设置/myquota2文件夹存储的文件,大小不超过2M
注意:数据块上传时,即使文件本身小于2M,该数据块实际在hdfs上占用的空间也为128M,上传会失败。因此在设定文件夹空间配额时,不要小于128M。
hdfs dfsadmin -clrSpaceQuota /myquota2
(3)快照
//快照相当于一种备份机制,在HDFS中默认式关闭的。
1、应用场景:
防止用户错误操作
备份
试验/测试
灾难恢复
2、命令:
管理命令:
-allowsnapshot
-disallowsnapshot
操作命令:
-createshapshot
举例:
打开快照功能(以/folder文件夹为例)
hdfs dfsadmin -allowsnapshot /folder
创建快照
hdfs dfs -createsnapshot /folder folder_20180503_01 第一份快照
hdfs dfs -createsnapshot /folder foldert_20180503_02 第二份快照
查看快照
hdfs -lssnapshottableDir
对比快照
hdfs -snapshotdiff /folder folder_20180503_01 folder_20180503_02
恢复快照
hdfs dfs -cp /folder/.snapshot/folder_20180503_01/data.txt /folder (补充知识:快照会在元文件夹下,以隐藏目录的方式存在(如folder/.snapshot/folder_20180503_01))
2)YARN 架构图
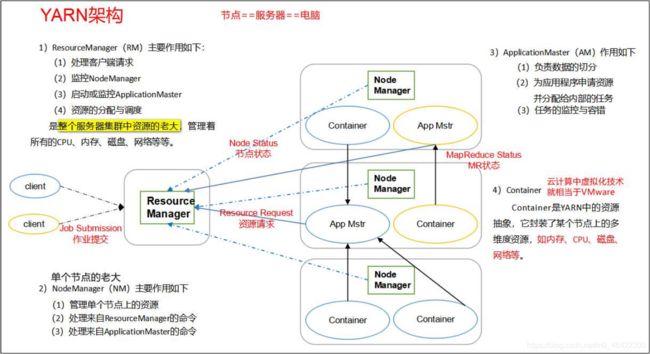 YARN 是很重要的一部分,将会单独讲解,这里放一张 YARN 的架构图先简单了解一下 YARN 的构成部分及作用。
YARN 是很重要的一部分,将会单独讲解,这里放一张 YARN 的架构图先简单了解一下 YARN 的构成部分及作用。
3)认识 MapReduce
这里我们用一些实例介绍一下 MapReduce 的基础知识和用法,了解 MapReduce 的实现思路就行了。
MapReduce 代表一种分而治之的编程思想,就像数钱一样,以前是一个人数一堆钱,而 MapReduce 是先把钱分成多堆,然后多个人去数,最后合并每个人数的结果。

一般来说,MapReduce 的过程分为这么几个阶段:
-
1、split阶段:
此阶段,每个输入文件被分片输入到map。如一个文件有200M,默认会被分成2片,因为每片的默认最大值和每块的默认值128M相同。如果输入为大量的小文件,则会造成过多的map数,导致效率下降,可采用压缩输入格式CombineFileInputFormat。 -
2、map阶段:
此阶段,执行map任务。map数由分片决定,若要增加map数,可增大mapred.map.tasks,若减少map数,可增大mapred.min.split.size。 -
3、shuffle阶段:
此阶段,将map的输出经过“整理”后给到reduce,也称为“混洗”。分为map端操作和reduce端操作。在map端,map的输出先写入缓存,当每次缓存快满时,由缓存“溢写”至磁盘,每次溢写都先进行“分区”,并对每个分区的数据进行“排序”和“合并”(可选)。一般会产生多个溢写的文件,这些文件会在map端先被“归并”为一个大的磁盘文件,通知reduce任务来领取自己的分区。
在reduce端,每个reduce任务会从多个map任务领取文件,然后将这些文件进行“归并”,交给reduce任务。合并(combine)和归并(merge)的区别:对于两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,即复用reduce的逻辑(也可以自己实现combiner类);如果归并,会得到<“a”,<1,1>>。combine为可选,可通过调用job.setCombinerClass(MyReduce.class)设置这一操作。 -
4、reduce阶段:
执行reduce任务。reduce数量由分区数决定,结果文件的数量也由此决定,且记录默认按key升序排列。reduce数量可通过mapred.reduce.tasks设置,或在代码中调用job.setNumReduceTasks(int n)方法。
Hadoop自带统计词频的示例,可以好好看看,如果能理解以后自己写一遍,基本就对 MapReduce 的思想和使用有一定程度的掌握了,剩下的就是复杂逻辑的使用了。