金融科技之NLP:上市公司新闻标题分类
本文的目标
本文的目标是训练出上市公司新闻的分类模型,根据新闻标题将上市公司的新闻自动分为利好、利空和模糊中性三类。
本文是创新创业项目第一阶段的技术总结,只给出了设计方法和结果,不提供源码。
实现步骤
1.获取原始数据
使用爬虫调用百度搜索引擎的接口,获取了10000余条沪深300成分股的新闻。
部分结果展示:
2.原始数据人工标注
从10000余条原始数据中选取来源于主流媒体的8000条数据,由人工根据新闻标题进行标注,分为利好、利空、模糊中性和数据存在问题4类。每条数据将由两名同学独立标注,拥有两个标签,汇总时只保留两个同学标准结果相同的数据,以提高标注数据的质量。
部分标注数据如下图所示。
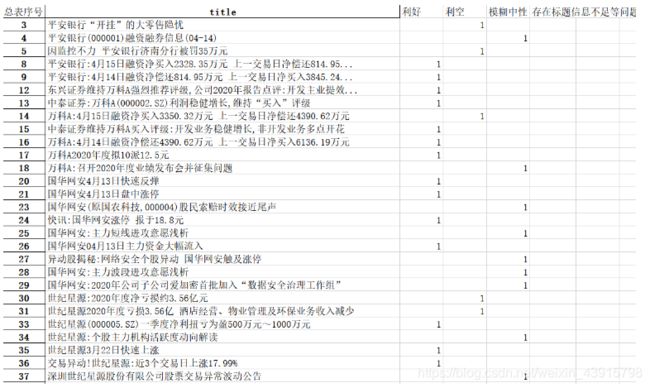
将只有一个标注结果的数据筛掉,得到6000余条带标注的数据。其中两个标注相同的数据约4000条,将这4000余条数据作为样本。
3.样本数据分析
3.1 样本类别分布
样本的类别分布如下图所示。

3.2 数据清洗
数据清洗阶段的工作:
1.清洗掉上市公司的名称,因为公司的名词会多次出现,但本身并没有偏向性,影响训练结果。
2.只保留汉字。
3.3 词频统计
使用jieba库对标题数据分词,统计每个类别的标题中各词出现的频率。
各类别标题中出现次数前20的词以及词频。
| 利好类 | count | 利空类 | count | 模糊中性类 | count | ||
|---|---|---|---|---|---|---|---|
| 万元 | 610 | 万元 | 412 | 公司 | 86 | ||
| 日 | 420 | 净利润 | 245 | 的 | 45 | ||
| 月 | 418 | 年 | 225 | 万元 | 30 | ||
| 净利润 | 416 | 年度 | 209 | 拟 | 30 | ||
| 年 | 368 | 亿元 | 195 | 日 | 29 | ||
| 增长 | 312 | 同比 | 193 | 月 | 28 | ||
| 同比 | 303 | 亏损 | 181 | 股东 | 28 | ||
| 净利 | 298 | 预计 | 165 | 为 | 26 | ||
| 一季度 | 282 | 下降 | 155 | 减持 | 25 | ||
| 净 | 278 | 约 | 132 | 净 | 25 | ||
| 亿元 | 278 | 一季度 | 124 | 亿元 | 25 | ||
| 预计 | 228 | 日 | 124 | 股份 | 23 | ||
| 买入 | 214 | 月 | 115 | 融资 | 22 | ||
| 年度 | 200 | 归母 | 98 | 有限公司 | 19 | ||
| 融资 | 184 | 净利 | 97 | 业务 | 19 | ||
| 快速 | 169 | 第一季度 | 87 | 目前 | 19 | ||
| 第一季度 | 156 | 净亏损 | 76 | 股权 | 18 | ||
| 公司 | 148 | 减少 | 73 | 年 | 18 | ||
| 约 | 148 | 万 | 66 | 子公司 | 17 | ||
| 偿还 | 146 | 业绩 | 64 | 偿还 | 17 |
4 特征构建
4.1 单词偏向性特征构建
从3.3的结果中可以明显得看出,中性的词在各类别中出现的次数都较多,如万元、公司、年、月、日等,但这些词本身没有太多有价值的信息。
需要构建一个指标,来量化一个词对某一类的偏向性。
假设单词个数为n,类别数量为m
我们采用的算法如下:
step1:对于每一类,将该类新闻标题包含的单词按照出现的频率降序排序,每一个单词在每一类中都有一个排序后的位置序号。index[word_i][cls_j]即为单词word_i在cls_j类中按照出现频率降序排序后的位置。
step2: 对于单词word_i,其对新闻类别cls_j的偏向性分数定义为:
score[word_i][cls_j] = sigma(index[word_j][cls_k],k不等于j)/ (m-1)- index[word_i][cls_j]
即该单词在其他类别中的位置序号的均值减去在该类别中的位置序号。
将单词根据利好偏向性降序排序:

将单词根据利空偏向性降序排序:
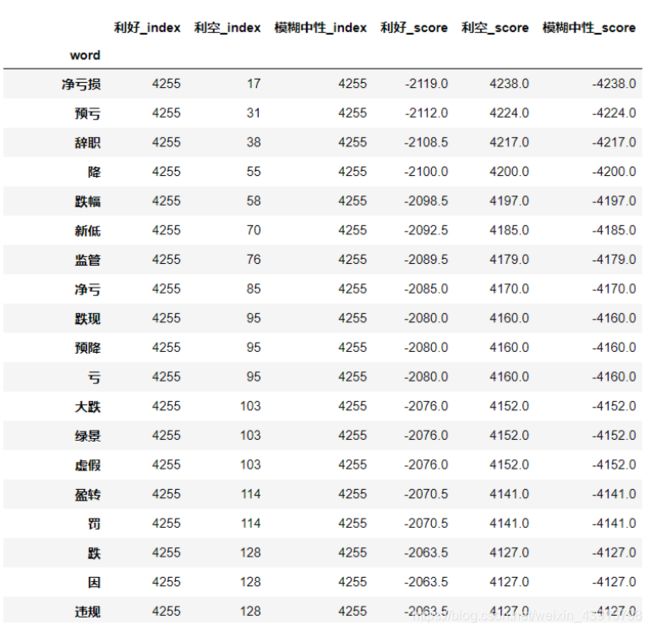
可见,构建的单词对类别的偏向性指标可以有效地量化一个单词对一个类别的偏向程度。
4.2 标题偏向性特征构建
一个标题对某个类别的偏向性计算步骤:
1、将标题分词
2、计算每一个单词对该类别的偏向性
3、求该标题包含的所有单词对该类别的偏向性的均值,该均值就是标题对该类别的偏向性。
4.3 标题分类模型的特征选取
每一个标题构建3个维度的特征,即该标题对利好、利空、模糊中性三个类别的偏向性。
样本点在三个维度构成的空间中的分布如下图所示。

可以看到,样本点按照类别在三维空间中分布范围特别明显,说明这三个特征对样本的分类很有帮助。
5 模型训练与评价
使用SVM训练分类器。
使用5折交叉验证对模型的过拟合情况进行检测,5次训练-测试的模型f1-score的均值为0.866
具体为
0.852, 0.867, 0.855, 0.866, 0.883
6 优化方向
1.使用专业的金融词典进行分词
2.更多的样本