【21】ShuffleNetV1
文章目录
-
-
- 1.ShuffleNetV1的介绍
- 2.ShuffleNetV1的结构
-
-
- 1)Channel Shuffle操作
- 2)ShuffleNet基本单元
-
- 3.ShuffleNetV1的性能统计
- 4.ShuffleNetV1的pytorch实现
-
1.ShuffleNetV1的介绍
- 分组卷积
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
- 分组卷积的矛盾——计算量
使用group convolution的网络有很多,如Xception,MobileNet,ResNeXt等。其中Xception和MobileNet采用了depthwise convolution,这是一种比较特殊的group convolution,此时分组数恰好等于通道数,意味着每个组只有一个特征图。但这些网络存在一个很大的弊端:采用了密集的1x1 pointwise convolution。在RexNeXt结构中,其实3x3的组卷积只占据了很少的计算量,而93.4%的计算量都是1x1的卷积所占据的理论计算量。
这个问题可以解决:对1x1卷积采用channel sparse connection, 即分组卷积,那样计算量就可以降下来了,但这就涉及到下面一个问题。
- 分组卷积的矛盾——特征通信
group convolution层另一个问题是不同组之间的特征图需要通信,否则就好像分了几个互不相干的路,大家各走各的,会降低网络的特征提取能力,这也可以解释为什么Xception,MobileNet等网络采用密集的1x1 pointwise convolution,因为要保证group convolution之后不同组的特征图之间的信息交流。
- channel shuffle的引出
为达到特征通信目的,我们不采用dense pointwise convolution,考虑其他的思路:channel shuffle。其含义就是对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。进一步的展示了这一过程并随机,其实是“均匀地打乱”。
2.ShuffleNetV1的结构
1)Channel Shuffle操作
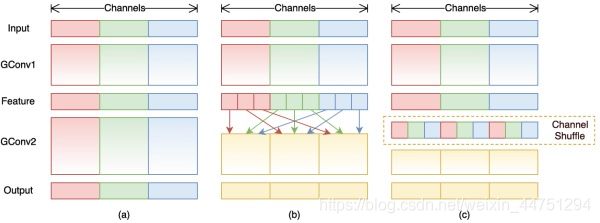
对于图a可以看见,特征矩阵会通过两个串行的组卷积操作计算。而对于普通的组卷积的计算可以发现,每次的卷积都是针对组内的一些特定的channel进行计卷积操作。也就是一直都是对同一个组进行卷积处理,每一个组内之间是没有进行交流的。
GConv虽然能够减少参数与计算量,但GConv中不同组之间信息没有交流。所以基于这个问题,ShuffleNetV1提出了channels shuffle的思想。
如图b所示,对于输入的特征矩阵,通过了GConv卷积之后得到的特征矩阵,对这些G组的特征矩阵的内部同样划分为G组,也就是现在有原来的G份变成了G*G份。那么,对于每一个大组内的G组中的同样位置,来重新构成一个channel,也就是有第1组的第1个channel,第2组的第1个channel,第3组的第1个channel,重新拼接成一个新的组。

这样进行了Channel shuffle操作之后,再进行组卷积,那么现在就可以融合不同group之间的特征信息。这个就是ShuffleNetV1中的Channel shuffle思想。
2)ShuffleNet基本单元
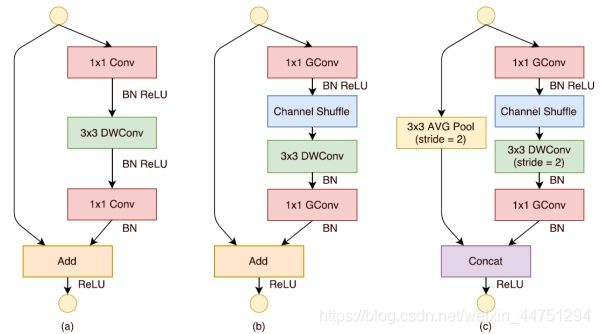
下图a展示了基本ResNet轻量级结构,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
下图b展示了改进思路:将密集的1x1卷积替换成1x1的group convolution(因为前诉了主要计算量较大的地方就是这个密集的1x1的卷积操作),不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。这是针对stride为1的情况。
下图c的降采样版本,对原输入采用stride=2的3x3 avg pool,在depthwise convolution卷积处取stride=2保证两个通路shape相同,然后将得到特征图与输出进行连接concat操作而不是相加。极致的降低计算量与参数大小。
3.ShuffleNetV1的性能统计
- 参数量

与ResNet和ResNeXt网络的参数使用对比

计算可以知道,ShuffleNetV1的参数使用量比ResNet和ResNeXt网络的参数都要少。
- 实时性
下图可以看到,ShuffleNetV1与AlexNet的错误率相识,在晓龙820处理器上的推理时间上可以看见,ShuffleNetV1只需要15ms,而AlexNet需要184ms,推理时间提升的还是比较高的。(所以的结果应用的是单线程处理)

- 准确率
下表给出了不同g值(分组数)的ShuffleNet在ImageNet上的实验结果。可以看到基本上当g越大时,效果越好,这是因为采用更多的分组后,在相同的计算约束下可以使用更多的通道数,或者说特征图数量增加,网络的特征提取能力增强,网络性能得到提升。注意Shuffle 1x是基准模型,而0.5x和0.25x表示的是在基准模型上将通道数缩小为原来的0.5和0.25。
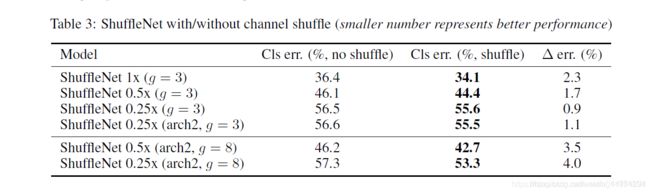
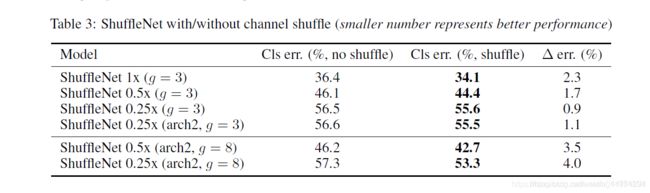
除此之外,作者还对比了不采用channle shuffle和采用之后的网络性能对比,如下表的看到,采用channle shuffle之后,网络性能更好,从而证明channle shuffle的有效性。
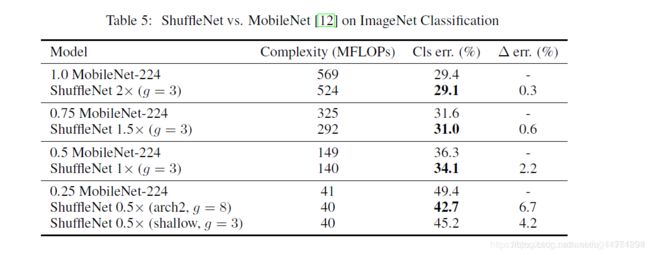
然后是ShuffleNet与MobileNet的对比,如下表ShuffleNet不仅计算复杂度更低,而且精度更好。
4.ShuffleNetV1的pytorch实现
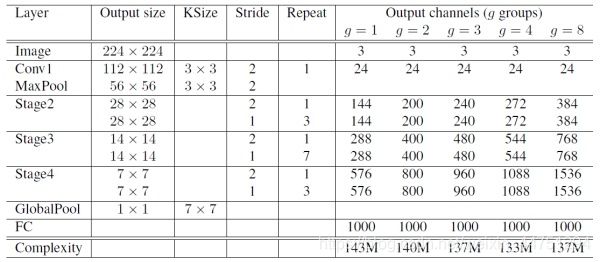
可以看到开始使用的普通的3x3的卷积和max pool层。然后是三个阶段,每个阶段都是重复堆积了几个ShuffleNet的基本单元。对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍。后面的基本单元都是stride=1,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的。还有其中的g表示的是分组的数量,其中较多论文使用的是g=3的版本。
参考代码:
import torch
import torch.nn as nn
import torchvision
# 分类数
num_class = 5
# DW卷积
def Conv3x3BNReLU(in_channels,out_channels,stride,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# 普通的1x1卷积
def Conv1x1BNReLU(in_channels,out_channels,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# PW卷积(不使用激活函数)
def Conv1x1BN(in_channels,out_channels,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,groups=groups),
nn.BatchNorm2d(out_channels)
)
# channel重组操作
class ChannelShuffle(nn.Module):
def __init__(self, groups):
super(ChannelShuffle, self).__init__()
self.groups = groups
# 进行维度的变换操作
def forward(self, x):
# Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]
N, C, H, W = x.size()
g = self.groups
return x.view(N, g, int(C / g), H, W).permute(0, 2, 1, 3, 4).contiguous().view(N, C, H, W)
# ShuffleNetV1的单元结构
class ShuffleNetUnits(nn.Module):
def __init__(self, in_channels, out_channels, stride, groups):
super(ShuffleNetUnits, self).__init__()
self.stride = stride
# print("in_channels:", in_channels, "out_channels:", out_channels)
# 当stride=2时,为了不因为 in_channels+out_channels 不与 out_channels相等,需要先减,这样拼接的时候数值才会不变
out_channels = out_channels - in_channels if self.stride >1 else out_channels
# 结构中的前一个1x1组卷积与3x3组件是维度的最后一次1x1组卷积的1/4,与ResNet类似
mid_channels = out_channels // 4
# print("out_channels:",out_channels,"mid_channels:",mid_channels)
# ShuffleNet基本单元: 1x1组卷积 -> ChannelShuffle -> 3x3组卷积 -> 1x1组卷积
self.bottleneck = nn.Sequential(
# 1x1组卷积升维
Conv1x1BNReLU(in_channels, mid_channels,groups),
# channelshuffle实现channel重组
ChannelShuffle(groups),
# 3x3组卷积改变尺寸
Conv3x3BNReLU(mid_channels, mid_channels, stride,groups),
# 1x1组卷积降维
Conv1x1BN(mid_channels, out_channels,groups)
)
# 当stride=2时,需要进行池化操作然后拼接起来
if self.stride > 1:
# hw减半
self.shortcut = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
self.relu = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.bottleneck(x)
# 如果是stride=2,则将池化后的结果与通过基本单元的结果拼接在一起, 否则直接将输入与通过基本单元的结果相加
out = torch.cat([self.shortcut(x),out],dim=1) if self.stride >1 else (out + x)
# 假设当前想要输出的channel为240,但此时stride=2,需要将输出与池化后的输入作拼接,此时的channel为24,24+240=264
# torch.Size([1, 264, 28, 28]), 但是想输出的是240, 所以在这里 out_channels 要先减去 in_channels
# torch.Size([1, 240, 28, 28]), 这是先减去的结果
# if self.stride > 1:
# out = torch.cat([self.shortcut(x),out],dim=1)
# 当stride为1时,直接相加即可
# if self.stride == 1:
# out = out+x
return self.relu(out)
class ShuffleNet(nn.Module):
def __init__(self, planes, layers, groups, num_classes=num_class):
super(ShuffleNet, self).__init__()
# Conv1的输入channel只有24, 不算大,所以可以不用使用组卷积
self.stage1 = nn.Sequential(
Conv3x3BNReLU(in_channels=3,out_channels=24,stride=2, groups=1), # torch.Size([1, 24, 112, 112])
nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # torch.Size([1, 24, 56, 56])
)
# 以Group = 3为例 4/8/4层堆叠结构
# 24 -> 240, groups=3 4层 is_stage2=True,stage2第一层不需要使用组卷积,其余全部使用组卷积
self.stage2 = self._make_layer(24,planes[0], groups, layers[0], True)
# 240 -> 480, groups=3 8层 is_stage2=False,全部使用组卷积,减少计算量
self.stage3 = self._make_layer(planes[0],planes[1], groups, layers[1], False)
# 480 -> 960, groups=3 4层 is_stage2=False,全部使用组卷积,减少计算量
self.stage4 = self._make_layer(planes[1],planes[2], groups, layers[2], False)
# in: torch.Size([1, 960, 7, 7])
self.global_pool = nn.AvgPool2d(kernel_size=7, stride=1)
self.dropout = nn.Dropout(p=0.2)
# group=3时最后channel为960,所以in_features=960
self.linear = nn.Linear(in_features=planes[2], out_features=num_classes)
# 权重初始化操作
self.init_params()
def _make_layer(self, in_channels,out_channels, groups, block_num, is_stage2):
layers = []
# torch.Size([1, 240, 28, 28])
# torch.Size([1, 480, 14, 14])
# torch.Size([1, 960, 7, 7])
# 每个Stage的第一个基本单元stride均为2,其他单元的stride为1。且stage2的第一个基本单元不使用组卷积,因为参数量不大。
layers.append(ShuffleNetUnits(in_channels=in_channels, out_channels=out_channels, stride=2, groups=1 if is_stage2 else groups))
# 每个Stage的非第一个基本单元stride均为1,且全部使用组卷积,来减少参数计算量, 再叠加block_num-1层
for idx in range(1, block_num):
layers.append(ShuffleNetUnits(in_channels=out_channels, out_channels=out_channels, stride=1, groups=groups))
return nn.Sequential(*layers)
# 初始化权重
def init_params(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias,0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.Linear):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.stage1(x) # torch.Size([1, 24, 56, 56])
x = self.stage2(x) # torch.Size([1, 240, 28, 28])
x = self.stage3(x) # torch.Size([1, 480, 14, 14])
x = self.stage4(x) # torch.Size([1, 960, 7, 7])
x = self.global_pool(x) # torch.Size([1, 960, 1, 1])
x = x.view(x.size(0), -1) # torch.Size([1, 960])
x = self.dropout(x)
x = self.linear(x) # torch.Size([1, 5])
return x
# planes 是Stage2,Stage3,Stage4输出的参数
# layers 是Stage2,Stage3,Stage4的层数
# g1/2/3/4/8 指的是组卷积操作时的分组数
def shufflenet_g8(**kwargs):
planes = [384, 768, 1536]
layers = [4, 8, 4]
model = ShuffleNet(planes, layers, groups=8)
return model
def shufflenet_g4(**kwargs):
planes = [272, 544, 1088]
layers = [4, 8, 4]
model = ShuffleNet(planes, layers, groups=4)
return model
def shufflenet_g3(**kwargs):
planes = [240, 480, 960]
layers = [4, 8, 4]
model = ShuffleNet(planes, layers, groups=3)
return model
def shufflenet_g2(**kwargs):
planes = [200, 400, 800]
layers = [4, 8, 4]
model = ShuffleNet(planes, layers, groups=2)
return model
def shufflenet_g1(**kwargs):
planes = [144, 288, 576]
layers = [4, 8, 4]
model = ShuffleNet(planes, layers, groups=1)
return model
if __name__ == '__main__':
# model = shufflenet_g3() # 常用
model = shufflenet_g8()
# print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
训练出来的模型大小有7M左右,与MobileNetV3的small版本结构相差不大。

参考:
https://blog.csdn.net/yzy__zju/article/details/107746203