Python之爬取《你好,李焕英》电影豆瓣短评
2021年春节档热播电影《你好,李焕英》,拿下累计票房54.12亿,一路杀进中国票房榜前五,堪称票房黑马。今天就以《你好,李焕英》这部电影为例,利用Python中的Xpath爬取其豆瓣短评,爬取的字段主要有:评论者、评分、评论日期、点赞数以及评论内容。该案例难度系数不大,刚好作为入门案例,废话不多说,让我们一起去看看吧!

注:虽然在《你好,李焕英》豆瓣短评首页中显示共有41万多条短评,但是当浏览时,却发现只能查看前25页的短评,也就是说用户只能看到500条短评评论。发现这个问题后,查阅了一些相关资料,原来是豆瓣电影早在2017年起就不再展示全部短评。官方给出的调整原因是:“为了在不影响用户体验的前提下反爬虫、反水军”(无奈.ipg)。鉴于此,本案例只爬取前500条热门短评。
1. 获取《你好,李焕英》豆瓣短评URL
不论爬取什么网站,第一步都是先获取我们所要爬取的网站地址,也就是url,获取的途径就是打开浏览器,找到《你好,李焕英》短评所在网页界面,然后地址栏中即为我们所需要的url。(注:一般情况下,网站第一页的url不会显示页码,所以这里就需要查看第二页的url)
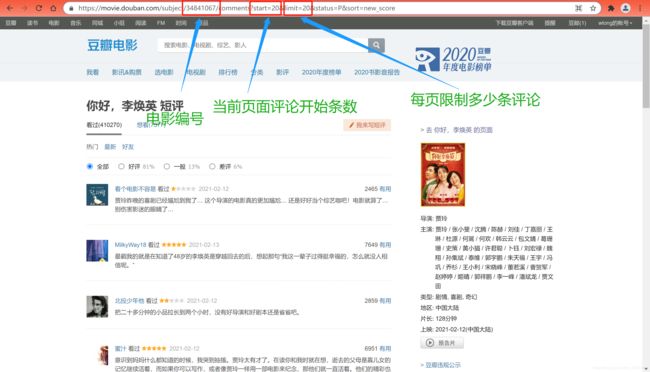
所以,该URL即为:
# 第一页的url
url = "https://movie.douban.com/subject/34841067/comments?start=0&limit=20&status=P&sort=new_score"
# 多页时,只需加入循环
for i in range(25): #豆瓣限制最多爬取25页,400条短评
url = "https://movie.douban.com/subject/34841067/comments?start={}&limit=20&status=P&sort=new_score".format(i*20)2. 分析网页html代码,查看评论所在的网页位置
直接在网页空白处,点击鼠标右键,选择【检查】,即可查看网页详细的源代码;
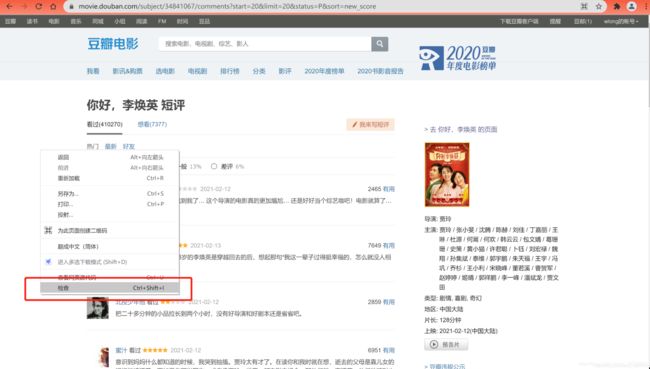
由于html网页源码,具有层层递进的关系,所以在查看评论在源代码中的位置时,可以将鼠标放在右边的代码块中,如果左边网页加深,即可以看到该代码在网页中的位置,如此一层一层的去找,直到找到最终我们所需的信息位置所在。
根据上述所讲,一层层的去找代码块与代码块的关系,最终找到我们所需要爬取的字段所在网页位置,主要有:评论者、评分、评论日期、点赞数、评论内容;
3. 利用Xpath解析网页拿到相应字段的值
(1)评论者:
reviewer = tree.xpath("//div[@class='comment-item ']//span[@class='comment-info']/a/text()")(2)评分等级:
score = tree.xpath("//div[@class='comment-item ']//span[@class='comment-info']/span[2]/@title")(3)评论日期:
comment_date = tree.xpath("//div[@class='comment-item ']//span[@class='comment-time ']/text()")(4)点赞数:
vote_count = tree.xpath("//div[@class='comment-item ']//span[@class='votes vote-count']/text()")(5)评论内容:
comments = tree.xpath("//p[@class=' comment-content']/span/text()")4. 完整代码解析如下:
## 导入相关包
import requests
import random
import time
import csv
import re
from fake_useragent import UserAgent # 随机生成UserAgent
from lxml import etree # xpath解析
## 创建文件对象
f = open('你好李焕英短评.csv', 'w', encoding='utf-8-sig', newline="")
csv_write = csv.DictWriter(f, fieldnames=['评论者', '评分等级', '评论日期', '点赞数', '评论内容'])
csv_write.writeheader() # 写入文件头
## 设置请求头参数:User-Agent, cookie, referer
headers = {
#随机生成User-Agent
'User-Agent' : UserAgent().random,
#不同用户不同时间访问,cookie都不一样,根据自己网页的来,获取方法见另一篇博客
'cookie' : 'll="118088"; bid=yiGUey7WS7s; __yadk_uid=0cC4MMTdwKcJLzygCFa059h947KmagyE; _vwo_uuid_v2=D84F02149AA36D0B6FA4F41B29BFC8A53|ba693980c9f906e4f903392f22cfdea4; gr_user_id=bd3c8d92-11df-4592-92b2-88e7c29d4131; viewed="21371175_34985248_34893628_34861737_33385402_1454809"; __gads=ID=f8e6531ebdf6b4f6-225dba1f51c50016:T=1608771142:RT=1608771142:S=ALNI_MZD_cEsfbC7rqyS1kxPf34UWKoQhg; douban-fav-remind=1; _vwo_uuid_v2=D84F02149AA36D0B6FA4F41B29BFC8A53|ba693980c9f906e4f903392f22cfdea4; __utmz=30149280.1620951897.27.24.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmc=30149280; __utma=30149280.1338646787.1605867382.1619667064.1620951897.27; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1620951908%2C%22https%3A%2F%2Fwww.douban.com%2Fsearch%3Fq%3D%25E4%25BD%25A0%25E5%25A5%25BD%25E6%259D%258E%25E7%2584%2595%25E8%258B%25B1%22%5D; _pk_ses.100001.4cf6=*; __utmc=223695111; __utmb=223695111.0.10.1620951908; __utma=223695111.1014600653.1605867382.1618911290.1620951908.13; __utmz=223695111.1620951908.13.11.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/search; dbcl2="238045093:HrICBFdes2U"; ck=0dzK; push_noty_num=0; push_doumail_num=0; __utmv=30149280.23804; __utmb=30149280.17.10.1620951897; _pk_id.100001.4cf6=eb739f645a2cadf1.1605867382.13.1620955097.1618911303.',
#设置从何处跳转过来
'referer': 'https://movie.douban.com/subject/34841067/comments?limit=20&status=P&sort=new_score',
}
## 从代理IP池,随机获取一个IP,比如必须ProxyPool项目在运行中
def get_proxy():
try:
PROXY_POOL_URL = 'http://localhost:5555/random'
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
except ConnectionError:
return None
## 循环爬取25页短评,每页短评20条,共400条短评
for i in range(25):
url = 'https://movie.douban.com/subject/34841067/comments?start={}&limit=20&status=P&sort=new_score'.format(i*20)
# request请求获取网页页面
page_text = requests.get(url=url, headers=headers, proxies={"http": "http://{}".format(get_proxy())}).text
# etree解析HTML文档
tree = etree.HTML(page_text)
# 获取评论者字段
reviewer = tree.xpath("//div[@class='comment-item ']//span[@class='comment-info']/a/text()")
# 获取评分等级字段
score = tree.xpath("//div[@class='comment-item ']//span[@class='comment-info']/span[2]/@title")
# 获取评论日期字段
comment_date = tree.xpath("//div[@class='comment-item ']//span[@class='comment-time ']/text()")
# 获取点赞数字段
vote_count = tree.xpath("//div[@class='comment-item ']//span[@class='votes vote-count']/text()")
# 获取评论内容字段
comments = tree.xpath("//p[@class=' comment-content']/span/text()")
# 去除评论日期的换行符及空格
comment_date = list(map(lambda date: re.sub('\s+', '', date), comment_date)) # 去掉换行符制表符
comment_date = list(filter(None, comment_date)) # 去掉上一步产生的空元素
# 由于每页20条评论,故需循环20次依次将获取到的字段值写入文件中
for j in range(20):
data_dict = {'评论者': reviewer[j], '评分等级': score[j], '评论日期': comment_date[j], '点赞数': vote_count[j], '评论内容': comments[j]}
csv_write.writerow(data_dict)
print('第{}页爬取成功'.format(i+1))
# 设置睡眠时间间隔,防止频繁访问网站
time.sleep(random.randint(5, 10))
print("---------------")
print("所有评论爬取成功")
5. 最终爬取到的数据:

好了,到此爬虫工作就差不多结束了,本文主要利用了Python中的Xpath去爬取《你好,李焕英》这部电影的豆瓣短评,整体来说,该案例总体难度系数不大,可以当作入门案例来做,只要好好加深理解相应知识点,一定可以掌握的!这篇博客主要目的在于从网站上爬取数据,至于分析数据、对评论绘制词云图等,可以见后续博客详解。
如果哪里有介绍的不是很全面的地方,欢迎小伙伴在评论区留言,我会不断完善的!
来都来了,确定不留下点什么嘛,嘻嘻~
