Python网络爬虫实例——正则表达式爬取B站排行榜
1.爬取分析
需要抓取的目标站点为:https://www.bilibili.com/v/popular/rank/all

页面中显示的有效信息有视频名称、播放量、分享数、up主名、综合得分、封面图片等信息。
根据视频分类,观察页面的URL变化

https://www.bilibili.com/v/popular/rank/bangumi
发现URL路径发生变化,all变成了bangumi
初步判断不同分类视频放在不同的路径下
可以把路径存放在元组中,循化爬取
2.抓取全站榜单
首先先试着抓取全站的榜单
import requests
def get_all_page(url):
headers = {
'User-Agent':'www.Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def main():
url = 'https://www.bilibili.com/v/popular/rank/all'
html = get_all_page(url)
print(html)
main()
运行结果:全站榜单的源代码

3.正则提取
回到网页看一下页面的真实源码

注意,这里不要在 Elements 选项卡中直接查看源码,因为那里的源码可能经过 JavaScript 操作而与原始请求不同,而是需要从 Network 选项卡部分查看原始请求得到的源码。
可以看到,一条视频信息对应的源代码是一个 li 节点,我们可以用记事本分析一个节点的结构,然后用正则表达式来提取这里面的一些视频信息 。

根据节点结构发现在div class=‘img’存放的是视频封面,随后跟的div class=“info”中存的是视频的数据(名称、播放量、分享数、up主名)
正则如下:
<li.*?<div\sclass="img"><a href="//(.*?)"\starget.*?lazy-image.*?title">(.*?).*?b-icon\splay"></i>(.*?)</span>.*?b-icon\sview">(.*?).*?b-icon\sauthor"></i>(.*?)</span>.*?pts.*?<div>(.*?)</div>综合得分.*?</li>
![]()
列表数据比较杂乱,再将匹配结果处理一下,遍历提取结果并生成字典:
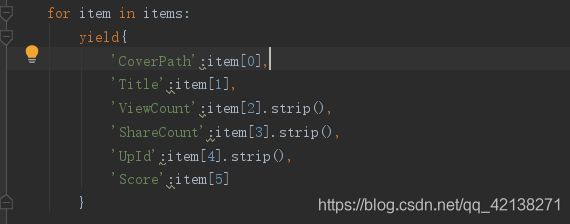
效果图:

4.写入文件
for item in parse_one_page(html):
with open(urlpath+'.txt','a',encoding='utf-8') as f:
print(item)
f.write(json.dumps(item,ensure_ascii=False) +'\n')
5.分类爬取
把不同类别的榜单路径组成一个元组urlpaths,循环爬取
def main():
url = 'https://www.bilibili.com/v/popular/rank/'
urlpaths=('all','guochuang','douga','music','dance',
'game','technology','digital','life','food','kichiku','fashion','ent','cinephile','origin','rookie')
for urlpath in urlpaths:
upath = url + urlpath
html = get_all_page(upath)
for item in parse_one_page(html):
with open(urlpath+'.txt','a',encoding='utf-8') as f:
print(item)
f.write(json.dumps(item,ensure_ascii=False) +'\n')
main()
6.运行结果

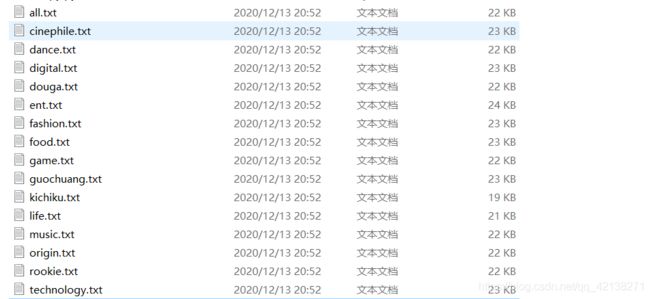

完整代码如下:
import requests
import re
from requests.exceptions import RequestException
import json
def get_all_page(url):
try:
headers = {
'User-Agent':'www.Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('(.*?).*?b-icon\splay">(.*?) .*?b-icon\sview">(.*?).*?b-icon\sauthor">(.*?).*?pts.*?(.*?)综合得分.*?', re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'CoverPath':item[0],
'Title':item[1],
'ViewCount':item[2].strip(),
'ShareCount':item[3].strip(),
'UpId':item[4].strip(),
'Score':item[5]
}
def main():
url = 'https://www.bilibili.com/v/popular/rank/'
urlpaths=('all','guochuang','douga','music','dance',
'game','technology','digital','life','food','kichiku','fashion','ent','cinephile','origin','rookie')
for urlpath in urlpaths:
upath = url + urlpath
html = get_all_page(upath)
for item in parse_one_page(html):
with open(urlpath+'.txt','a',encoding='utf-8') as f:
print(item)
f.write(json.dumps(item,ensure_ascii=False) +'\n')
main()