第一章 中文语言的机器处理
文章目录
- 1. 搭建NLTK环境
-
- 1.1 操作系统
- 1.2 Python开发环境
- 1.3 安装常用Python应用程序
- 2. 整合中文分词模块
-
- 2.1 安装Ltp Python组件
- 2.2 使用Ltp3.4进行中文分词
- 2.3 使用结巴分词模块
- 3. 整合词性标注模块
-
- 3.1 Ltp 3.4 词性标注
- 3.2 安装StanfordNLP并编写Python接口类
- 3.3 执行Stanford词性标注
- 4. 整合命名实体识别模块
-
- 4.1 Ltp3.4命名实体识别
- 4.2 Stanford 命名实体识别
- 5. 整合句法解析模块
-
- 5.1 Ltp 3.4 句法依存树
- 5.2 Stanford Parser 类
- 5.3 Stanford 短语结构树
- 5.4 Stanford 依存句法树
- 6. 整合语义角色标注模块
- 7. 结语
1. 搭建NLTK环境
1.1 操作系统
本教程用的操作系统是Windows 10 x64(如果你使用的是32位系统,则应升级为64位的操作系统;如果你安装的是Windows 7或XP,则无需升级到Windows 10操作系统)。
1.2 Python开发环境
本教程使用的是当前最新版本的Python-3.7版本。
安装方法,我是用过两种。
第一种是标准方法,也就是到官网上下载最新版本。
第二种是使用 Anaconda跨平台安装包,可以到官网 https://www.continuum.io/downloads 上自行下载,部分教程可以参考本人博客相关内容。
编辑器用的是Pycharm。
1.3 安装常用Python应用程序
-
安装数学运算包。
pip install numpy
conda install scipy -
安装mysql数据库工具包 。
略 -
安装Tornado网络包 。
pip install Tornado
-
安装NLTK开发环境。
(1)安装NLTK语言开发系统的基本指令。pip install nltk
(2)下载常用语料库:NLTK,执行如下代码可下载相关的语料。
import nltk
nltk.download()出现如图所示界面:
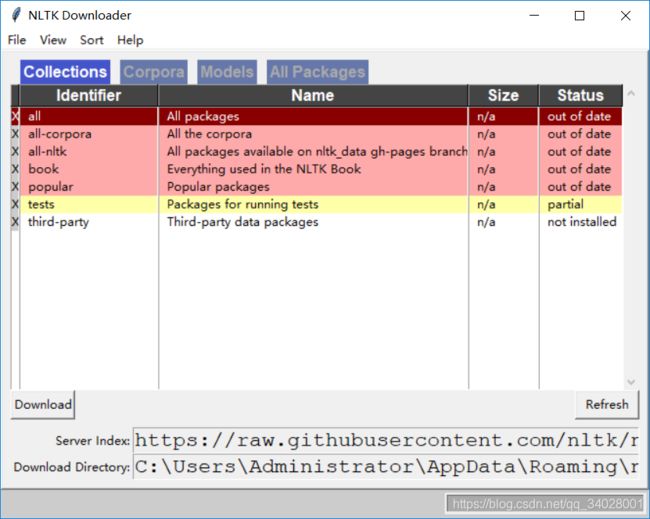
注意,如果在Pycharm中运行代码。import nltk
可能会报一系列错误,主要表示无法获取模块。然而这个时候感觉一切都是正确的(python用的是Anaconda的虚拟环境,Anaconda环境变量配置完整,cmd中执行上述代码没有问题),却找不到正确方法。建议重启电脑,清理电脑垃圾(360),在cmd上运行一遍,在觉得比较通畅的时候,再在Pycharm上再试一遍。如果没有报错,那就说明成功了。如果按照上面安装nltk的参考链接,已经将nltk_data下载到了本地,结果是老是显示网络链接超时,只跳出来窗口,不显式各种库,只需点击refresh,慢慢地各种库就会显示出来。
这个在整合句法分析模块用的到,现在也不必太过着急,可以回头参考,免得事倍功半。
2. 整合中文分词模块
这里将几个开源的NLP系统整合到NLTK中。
本节主要介绍【中文分词】部分。汉语自然语言处理的第一部分是中文分词。 因为中文不像英文那样,实行分词连写,即词与词之间用空格分隔。在分析中文文本之前必须将一个汉字序列切分成一个一个单独的词。这个过程称为中文分词(Chinese Word Segmentation)。
按照使用的算法不同,介绍两大类中文分词模块
- 基于条件随机场(CRF)的中文分词算法的开源系统。
- 基于张华平NShort的中文分词算法的开源系统。
2.1 安装Ltp Python组件
国内使用CRF做中文分词的开源系统主要为哈工大的HIT LTP语言技术平台。
(1)pyltp安装。
pip install pyltp
然而失败(我python3.5,3.7都试过了失败),报错原因:
c:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe’ failed with exit status 2
解决办法:
果断放弃pip和conda方法,参考链接这位仁兄的解决办法。
步骤1:添加VC路径到用户环境变量中,注意是用户环境变量中,而不是系统环境变量中。
变量名:VCINSTALLDIR (变量值为vs安装路径下的VC,默认是这个)
变量值(我的):C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC
步骤2:
win+R运行cmd,执行命令:
set CL=/FI”%VCINSTALLDIR%\INCLUDE\stdint.h” %CL%
步骤3:
先下载pyltp压缩文件。下载链接:https://github.com/hit-scir/pyltp ,下载完成后,解压到任意一个文件夹下,如pyltp-master。注意,解压pyltp后所得到的文件夹中可能已经有一个名为ltp的空文件夹:
步骤4:
然后下载ltb压缩文件。下载;链接:https://github.com/hit-scir/ltp ,下载完成后,解压文件夹到任意一个文件夹中,如,ltp-master。
步骤5:
将ltp-master该文件夹重命名为ltp复制并覆盖pyltp的ltp文件夹。
步骤6:
win+R打开CMD,cd到pyltp目录下,然后输入python setup.py install,如下所示(我用的是Anaconda,所以有第一句激活命令,如果不是Anaconda忽略第一句)。
(base) C:\Users\Administrator>activate Anaconda-Pycharm
(Anaconda-Pycharm) C:\Users\Administrator>d:
(Anaconda-Pycharm) D:>cd D:\Anaconda3\envs\Anaconda-Pycharm\pyltp-master
(Anaconda-Pycharm) D:\Anaconda3\envs\Anaconda-Pycharm\pyltp-master>python setup.py install
结果是!!!!(神啊,让我成功吧!):
报错:
ltp/src/utils/strutils.hpp(344): warning C4267: ‘initializing’: conversion from ‘size_t’ to ‘int’, possible loss of data
ltp/src/utils/sbcdbc.hpp(67): warning C4267: ‘initializing’: conversion from ‘size_t’ to ‘int’, possible loss of data
ltp/src/utils/sbcdbc.hpp(85): warning C4267: ‘initializing’: conversion from ‘size_t’ to ‘int’, possible loss of data
ltp/src/utils/smartmap.hpp(617): warning C4267: ‘initializing’: conversion from ‘size_t’ to ‘int32_t’, possible loss of data
patch\libs\python\src\converter\builtin_converters.cpp(51): error C2440: ‘return’: cannot convert from ‘const char *’ to ‘void *’
patch\libs\python\src\converter\builtin_converters.cpp(51): note: Conversion loses qualifiers
patch\libs\python\src\converter\builtin_converters.cpp(442): warning C4244: ‘initializing’: conversion from ‘Py_ssize_t’ to ‘int’, possible loss of data
error: command ‘C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe’ failed with exit status 2
可以看的出来前面都是warning,可以忽略,但是这里有一个报错的信息:
patch\libs\python\src\converter\builtin_converters.cpp(51): error C2440: ‘return’: cannot convert from ‘const char *’ to ‘void *’
错误原因:类型转换出错。
解决办法:(51)行加(void*),暴力解决,强制类型转换。
#if PY_VERSION_HEX < 0x03000000
void* convert_to_cstring(PyObject* obj)
{
return PyString_Check(obj) ? PyString_AsString(obj) : 0;
}
#else
void* convert_to_cstring(PyObject* obj)
{
return PyUnicode_Check(obj) ? (void*) _PyUnicode_AsString(obj) : 0;
}
#endif
再来试一下:
结果是:成功!!!!
Installed d:\anaconda3\envs\anaconda-pycharm\lib\site-packages\pyltp-0.2.1-py3.7-win-amd64.egg
Processing dependencies for pyltp==0.2.1Finished processing dependencies for pyltp==0.2.1
没得塔西,没得塔西
(2)部署语言模型库。
从链接:https://pan.baidu.com/s/1DQObXdIkGyS_Ne_h7ixrZg 提取码:40zu下载Ltp的模型文件,好几种,我自己用v3.4.0,解压在自己的某一个盘符下: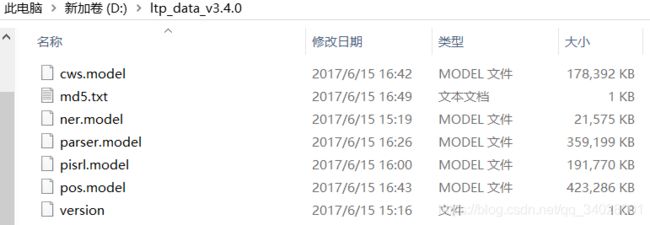 cws.model为中文分词模块所需的语言模型,为二进制文件。
cws.model为中文分词模块所需的语言模型,为二进制文件。
fulluserdict.txt为用户可添加的外部词典文件,貌似一开始并不存在,可以用户在运行过程中慢慢添加,如下面的实例,结构如图所示。
2.2 使用Ltp3.4进行中文分词
(1)Ltp3.4 安装成功之后,新建一个Python文件:
# -*- coding: utf-8 -*-
from pyltp import Segmentor # 导入ltp库
segmentor = Segmentor() # 实例化分词模块
segmentor.load("D:/ltp_3.4/cws.model")# 加载分词库
words = segmentor.segment("在包含问题的所有解的解空间树种,按照深度优先搜索的策略,从根节点出发深度探索解空间树。")# ,调用分词函数,设置分词对象
print("|".join(words))# 打印分词结果
segmentor.release()
执行结果如下:
在|包含|问题|的|所有|解|的|解|空间|树种|,|按照|深度|优先|搜索|的|策略|,|从|根节点|出发|深度|探索|解|空间|树|。
(2)分词结果的处理。
观察上述分词结果,“解|空间”、“解|空间|树”、“深度|优先”都可以看作一个完成的专有名词:解空间、解空间树、深度优先,所以说,分词器划分的【粒度过细】。
为了获得更精确的结果,可以将错分的结果合并为【专有名词】。这就是分词结果的后处理过程,即【一般外部用户词典的构成原理】。
# -*- coding: utf-8 -*-
from pyltp import Segmentor # 导入ltp库
postdict={
"解|空间":"解空间","深度|优先":"深度优先"}# 分词后处理——矫正一些错误的结果
segmentor = Segmentor() # 实例化分词模块
segmentor.load("D:/ltp_3.4/cws.model")# 加载分词库
words = segmentor.segment("在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。")# 设置分词对象
seg_sent = "|".join(words)# 分割后的分词结果
print("分割后的分词结果 :"+seg_sent)
for key in postdict:
seg_sent=seg_sent.replace(key,postdict[key])
print("分词后处理的分词结果 : "+seg_sent)# 打印分词后处理的分词结果
segmentor.release()
分词结果如下:
分割后的分词结果 :在|包含|问题|的|所有|解|的|解|空间|树|中|,|按照|深度|优先|搜索|的|策略|,|从|根节点|出发|深度|探索|解|空间|树|。
分词后处理的分词结果 : 在|包含|问题|的|所有|解|的|解空间|树|中|,|按照|深度优先|搜索|的|策略|,|从|根节点|出发|深度|探索|解空间|树|。
(3)现在加入用户词典,词典中登陆一些新词,如解空间。
javascript
2.3 使用结巴分词模块
张华平NShort的中文分词算法是目前最大规模中文分词的主流算法。在商用领域,大多数搜索引擎公司都使用该算法做欸主要的分词算法。具有算法原理简单、容易理解、便于训练、大规模分词的效率高、模型支持增量扩展、模型占用资源低等优势。
结巴分词的算法核心就是NShort中文分词算法。
(1)结巴分词库的安装。
pip install jieba
结巴分词下载地址:https://github.com/fxsjy/jieba 下载完解压到任一文件夹,如,D:\jieba-master,命令如下:
(base) C:\Users\Administrator>activate Anaconda-Pycharm
(Anaconda-Pycharm) C:\Users\Administrator>d:
(Anaconda-Pycharm) D:>cd D:\jieba-master
(Anaconda-Pycharm) D:\jieba-master>python setup.py install
(2)使用结巴分词
# -*- coding: utf-8 -*-
import jieba # 导入结巴分词库
# 结巴分词--全模式
sent = '在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。'
wordlist = jieba.cut(sent, cut_all=True)
print('|'.join(wordlist))
# 结巴分词--精确切分
wordlist = jieba.cut(sent) # cut_all = False
print('|'.join(wordlist))
# 结巴分词--搜索引擎模式
wordlist = jieba.cut_for_search(sent)
print('|'.join(wordlist))
分词结果如下。
D:\Anaconda3\envs\Anaconda-Pycharm\python.exeD:/PycharmProjects/NLP/jieba_test.py
Building prefix dict from the default dictionary …
Dumping model to file cacheC:\Users\Administrator\AppData\Local\Temp\jieba.cache
在|包含|问题|的|所有|解|的|解空|空间|树|中|||按照|深度|优先|搜索|的|策略|||从|根|节点|点出|出发|深度|探索|索解|解空|空间|树||
在|包含|问题|的|所有|解|的|解|空间|树中|,|按照|深度|优先|搜索|的|策略|,|从根|节点|出发|深度|探索|解|空间|树|。
在|包含|问题|的|所有|解|的|解|空间|树中|,|按照|深度|优先|搜索|的|策略|,|从根|节点|出发|深度|探索|解|空间|树|。
Loading model cost 1.191 seconds.
Prefix dict has been built successfully.进程已结束,退出代码 0
结巴分词的基础词库较之Ltp分词要少一些,标准词典的词汇量约有35万个。上例的分词结果显示,一些专有名词的切分缺乏足够的精度,不仅出现粒度问题,还出现错分问题(如上例中的“树中”、“从根”)。由此可见分词器的精度不仅受到算法的影响,更受到语言模型库的规模影响。这一点对于NShort最短路径算法尤其明显。
(3)定义用户词典。
如,词典文件userdict.txt
解空间 5 n
解空间树 5 n
根节点 5 n
深度优先 5 n
词典格式为一个词占一行;每一行分为三部分:词与、词频和词性,用空格隔开,顺序不可颠倒。userdict.txt文件必须为UTF-8编码。
结巴分词中的词典词频设置,默认为5。这个数越大,说明该字符串的概率越高,受内置词典的干扰就越小;这个数越小,用户词典内的词收到内置词典的干扰越强,不能受到正确切分的概率就越大。用户根据实际情况来设置这个值。
(4)使用用户词典。
# -*- coding: utf-8 -*-
import jieba # 导入结巴分词库
jieba.load_userdict("userdict.txt") #加载外部 用户词典
sent = '在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。'
# 结巴分词--精确切分
wordlist = jieba.cut(sent) # cut_all = False
print('|'.join(wordlist))
分词结果如下。
Building prefix dict from the default dictionary …
Loading model from cache C:\Users\Administrator\AppData\Local\Temp\jieba.cache
Loading model cost 1.104 seconds.
在|包含|问题|的|所有|解|的|解空间树|中|,|按照|深度优先|搜索|的|策略|,|从|根节点|出发|深度|探索|解空间树|。
Prefix dict has been built successfully.
3. 整合词性标注模块
【词性标注】(Part-of-Speech Tagging或POS Tagging),又称为词类标注,是指判断处在一个句子中没歌词所扮演的语法角色。例如,表示人、事物、地点或抽象概念的名称就是名词;表示动作或状态变换的词为动词;用来描写或修饰名词性成分或表示概念的性质、状态、特征或属性的词称为形容词,等等。
在汉语中,常用词的词性都不是固定的,也就是说,一个词可能具有多个词性。
本节主要介绍几个中文词性标注系统的应用。一般而言,中文的词性标注算法比较统一,大多数使用【HMM】(隐马尔科夫模型)或【最大熵算法】,如前文中的结巴分词的词性标注实现。为了获得更高的精度,也有使用【CRF算法】的,如Ltp3.4中的词性标注。虽然分词与词性标注是两个不同的模块,但是在一般的工程应用中,语料的【中文分词】和【词性标注】通常同时完成。
目前流行的中文词性标签有两大类:北大词性标注集和宾州词性标注集。两大标注方式各有千秋,为了更全面地反应中文标注的概况,我们使用Stanford大学的中文词性标注模块作为另一个中文词性标注系统。
3.1 Ltp 3.4 词性标注
# -*- coding: utf-8 -*-
from pyltp import Segmentor
from pyltp import Postagger
words = "在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。"
segmentor = Segmentor() # 实例化分词模块
segmentor.load("D:/ltp_3.4/cws.model")# 加载分词库
words = segmentor.segment(words)# 调用分词函数
words = '|'.join(words)
sent = words.split('|')
postagger = Postagger() # 实例化词性标注类
postagger.load("D:/ltp_3.4/pos.model")# 导入词性标注模型
postags = postagger.postag(sent)
for word,postags in zip(sent,postags):
print(word+"/"+postags)
词性标注结果如下。
在/p
包含/v
问题/n
的/u
所有/b
解/n
的/u
解/v
空间/n
树/n
中/nd
,/wp
按照/p
深度/n
优先/v
搜索/v
的/u
策略/n
,/wp
从/p
根节点/n
出发/v
深度/n
探索/v
解/v
空间/n
树/n
。/wp
标注的标签与原标签用“/”分隔,每个标签都有器语法的意义。例如,“n”表示名词,“v”表示动词。Ltp的词性标注遵从给北大词性标注规范。
3.2 安装StanfordNLP并编写Python接口类
下面介绍如何使用StanfordNLP系统来进行中文词性标注。在使用之前,需要安装jdk环境,Stanford-CoreNLP-3.6.0 版本需要安装Java 8+的环境。(安装jdk过程跳过)
安装Stanford NLP的语言程序包。读者可从http://stanfordnlp.github.io/CoreNLP/ 网页下载全套语言处理模块,或者我自己提供的下载地址:https://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip ,可以直接将链接复制到迅雷下载。
下载文件名为 standford-corenlp-full-2018-10-05.zip,但其只携带了英文的语言模型包,中文部分的语言模型需要单独下载,下载链接:https://stanfordnlp.github.io/CoreNLP/index.html#download 
最好用迅雷下载,中文模型包大概1G大小。
先将stanford-corenlp-full-2018-10-05.zip解压到盘符下一个名为stanford-corenlp的文件夹下,如,D:/stanford-corenlp。

很长的文件夹内容,其中stanford-corenlp.jar为主执行文件。
下载的中文模型文件Stanford-Chinese-corenlp-2018-10-05-models.jar解压后的目录结构如图所示。
Stanford-Chinese-corenlp-2018-10-05-models.jar中的中文模型全部解压到d:/stanford-corenlp中的models目录下。其中,pos-tagger目录下放置了词性标注的中文模型。
读者可以从http://nlp.stanford.edu/software/tagger.shtml 处下载stanford-postagger-full-2018-10-05.zip包,参考教程,并找到stanford-postagger.bat作为执行命令行的参考脚本。
该工具包是用java写的,所以使用该工具包有两种方式:Java代码和命令行调用。下面是解压的文件夹。

(1)Java代码方式。
具体的代码可以参看TaggerDemo.java和TaggerDemo2.java这两个代码,需要注意的是在工程中(例如:eclipse),工程需要将对应的“models”文件夹放置在该工程中,同时在该项目的“Build Path”中选择“Configure Build Path”,点击“Add External JARs”,将“stanford-postagger-3.9.2.jar”加入该项目中,接下来就是基于Demo改一下就可以使用。 当然,如果我们想要做一个可视化界面,可以将该工程导出(export)成一个可执行的jar(Runnable jar file),同时需要注意,我们需要在生成的可执行jar的路径下把“models”文件夹也复制进来,否则,无法调用postagger。
(2)命令行方式。
这个可以参看文件夹的“README.txt"这个文件。里面有好几种方式,我们这次主要说明利用stanford-postagger.sh来进行。
其实这里有一个小缺陷,假设一个场景:如果我们在一个路径下调用了一个python脚本,我们在该python里想要利用os。system(cmd)来调用该postagger.sh,但是该python脚本和该postagger.sh并不在一个路径下,所以我们需要用一个String构造cmd命令,这样很可能会用”../"或者“./”来表示路径,但是我们需要调用该.sh又需要使用“./"这个命令,所以这是个小矛盾,注意例子中给的”./"只是一种调用.sh的方式,我们还可以用“sh tagger.sh ..."这样的命令来进行调用。(表示这段内容,没遇到过,下面我来解释,我知道的)
在该文件夹中,点击运行stanford-postagger-gui.bat,会出来一个Stanford词性标注器,然而只有英文的。

现在需要用在命令行下,重新编辑bat文件, cd到D:/stanford-postagger目录下,在D:/stanford-postagger下新建一个postext.txt文件,要求是utf-8格式(另存为可以实现)。postext文件内容:
在 包含 问题 的 所有 解 的 解空间树 中 ,按照 深度优先 搜索 的 策略 ,从 根节点 出发 深度 探索 解空间树 。
执行过程如下:
(Anaconda-Pycharm) D:>cd d:/stanford-postagger
(Anaconda-Pycharm) d:\stanford-postagger>java -mx200m -classpath stanford-postagger.jar edu.stanford.nlp.tagger.maxent.MaxentTagger -model “models\chinese-distsim.tagger” -textFile postext.txt > result.txt
执行结果如下:
Loading default properties from tagger models\chinese-distsim.tagger
Loading POS tagger from models\chinese-distsim.tagger … done [1.5 sec].
Tagged 21 words at 262.50 words per second.
在result.txt文件中的内容如下:
在#VV 包含#VV 问题#NN 的#DEC 所有#DT 解#VV 的#DEC 解空间树#NN 中#LC ,按照#NR 深度优先#AD 搜索#VV 的#DEC 策略#NN ,从#NN 根节点#NN 出发#VV 深度#JJ 探索#NN 解空间树#VV 。#PU
在该过程中。
(Anaconda-Pycharm) d:\stanford-postagger>java -mx200m -classpath stanford-postagger.jar edu.stanford.nlp.tagger.maxent.MaxentTagger -model “models\chinese-distsim.tagger” -textFile postext.txt > result.txt
java -mx200m #调用java程序,以及设置最大的内存
可修改内容为最大内存大小。
-cp stanford-postagger.jar # 调用的jar包,3.9版只有一个就是stanford-postagger.jar
可修改的内容stanford-postagger.jar包的路径,也就是如果不cd到D:/stanford-postagger目录下,在任一目录下,需要填写完整路径。
-classpath “D:\stanford-postagger\stanford-postagger.jar”
或者
-cp “D:\stanford-postagger\stanford-postagger.jar;”
edu.stanford.nlp.tagger.maxent.MaxentTagger # 最大熵分类器
-model "models\\chinese-distsim.tagger" # 最大熵模型文件 ,对应-model %1
可修改内容为%1,其模型文件在"D:/stanford-postagger/models/"路径下,如果不是在stanford-postagger目录下执行就需要,修改为绝对路径。
-textFile postext.txt > result.txt # 最大熵输入文件,同时结果放到输出文件
可修改内容为postext.txt 和 result.txt路径,如果这两个文件不想放在执行命令的路径下,就需要填写绝对路径。
-textFile D:\stanford-postagger\postext.txt > D:\result.txt
总的来说也就是可以如此修改。
(Anaconda-Pycharm) C:\Users\Administrator>java -mx200m -classpath “D:\stanford-postagger\stanford-postagger.jar” edu.stanford.nlp.tagger.maxent.MaxentTagger -model “D:\stanford-postagger\models\chinese-distsim.tagger” -textFile D:\stanford-postagger\postext.txt > D:\result.txt
结果为:
Loading default properties from tagger D:\stanford-postagger\models\chinese-distsim.tagger
Loading POS tagger from D:\stanford-postagger\models\chinese-distsim.tagger … done [1.5 sec].
Tagged 21 words at 262.50 words per second.
为了在NLTK中使用方便,新建一个 stanford.py,专门编写了一个 StanfordCoreNLP 的若干个接口类,用于 Python 调用 Java 编写的NLP词性标注应用。 新建一个StanfordCoreNLP_Interface.py
import os
class StanfordCoreNLP_Interface(): # 所有StanfordNLP的父类
def __init__(self,root):# 构造函数
self.root = root # 获取jar包根路径
self.inputpath = "D:/stanford-postagger/postext.txt" # 临时中文输入源文件路径 -textFile %2 , 注意将文件格式设置为utf-8
self.jarlist = {
"ejml-0.23.jar","javax.jason.jar","jollyday.jar","joda-time.jar","protobuf.jar","slf4j-api.jar","slf4j-simple.jar","stanford-corenlp-3.9.2.jar","xom.jar"}
self.jarlistpath = ""
self.buildjars() # 根据根目录构建-classpath jarlistpath
# 创建临时文件存储路径
def savefile(self, inputpath, sent):
fp = open(inputpath, 'w', encoding='utf-8')
# 注意这里需要指定编码格式为utf-8,否则会报错:
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xbd in position 98: illegal multibyte sequence
fp.write(sent)
fp.close()
# 根据root路径构建所有的jar包路径 -classpath
def buildjars(self):
# D:/stanford-corenlp/ejml-0.23.jar;D:/stanford-corenlp/javax.jason.jar;....;
for jar in self.jarlist:
self.jarlistpath += self.root + jar +";"
print(self.jarlistpath)
def delfile(self,path): # 删除临时文件
os.remove(path)
新建一个StanfordPOSTagger_Interface.py
import os
from StanfordCoreNLP_Interface import StanfordCoreNLP_Interface
class StanfordPOSTagger_Interface(StanfordCoreNLP_Interface): # 词性标注子类
def __init__(self,root,modelpath): # 重写构造函数
StanfordCoreNLP_Interface.__init__(self, root)# 声明StanfordCoreNLP构造函数,这样就可以调用SCNLP的属性了,如tempsrcpath。
self.modelpath = modelpath # 模型文件路径
self.classfier = "edu.stanford.nlp.tagger.maxent.MaxentTagger" # 词性标注主类
self.delimiter = "/" # 标签分隔符
self.__buildcmd()
def __buildcmd(self):# 将此方法定义为私有
self.cmdline = 'java -mx200m -classpath "'+self.jarlistpath +'" '+self.classfier+' -model "'+ self.modelpath + '" -tagSeparator ' + self.delimiter
print(self.cmdline)
# 标注文件
def tagfile(self,sent,outpath):
self.savefile(self.inputpath,sent)
os.system(self.cmdline+' -textFile '+self.inputpath+' > ' +outpath)# 结果输出到文件outpath中
self.delfile(self.inputpath)
3.3 执行Stanford词性标注
使用StanfordPOSTagger类来进行词性标注。
from StanfordPOSTagger_Interface import StanfordPOSTagger_Interface
root = 'D:/stanford-corenlp/'
modelpath = root + "models/pos-tagger/chinese-distsim/chinese-distsim.tagger"
st = StanfordPOSTagger_Interface(root,modelpath)
seg_sent = '在 包含 问题 的 所有 解 的 解空间 树 中 , 按照 深度优先 搜索 的 策略 ,从 根节点 出发 深度 探索 解空间 树 。 '
taglist = st.tagfile(seg_sent,"D:/result.txt")
查看D:/result.txt文件内容。
在/P 包含/VV 问题/NN 的/DEC 所有/DT 解/VV 的/DEC 解空间/NN 树/NN 中/LC ,/PU 按照/P 深度优先/NN 搜索/NN 的/DEC 策略/NN ,从/NN 根节点/NN 出发/VV 深度/JJ 探索/NN 解空间/NN 树/NN 。/PU
在StanfordPOSTagger的分词结果中,“p”表示介词;“NN”表示一般名词;“LC”表示方位词等,由于Ltp3.3和Stanford使用的词性标签不同,这里对标注结果不做评估。后面章节中会对词性标注做一个专门的评估。
4. 整合命名实体识别模块
【命名实体识别】(Named Entity Recognition,NER)用于识别文本中具有特定意义 的实体,常见的实体主要包括人名、地名、机构名及其他专有名词等。
本文将命名实体划分在语义范畴的原因是,命名实体识别不仅需要标注词的语法信息(名称),更重要的是指示词的语义信息(人名还是组织机构名等)。这里所需要识别的命名实体一般不是指已知名词(词典种的登录词),而是指新词(或称未登录词)。
文本中新词的涌现反映了人类词汇的【能产性】。所谓能产性指基本词(字)能够构成其他新词,但是这些新词的产生并没有规律性。应该说,不同的【义类】具有不同的规律;构成中国人名的统计规律,显然区别于外文译名,或其他专有名词。新词构成的概率按照义类的不同而有所不同。这是命名实体构成的普遍规律。
更具体地命名实体识别任务还要识别出文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
4.1 Ltp3.4命名实体识别
from pyltp import *
sent = "陕西 西安 是 一 座 古老 的 城市 。"
words = sent.split(" ")
postagger = Postagger()
postagger.load("D:/ltp_3.4/pos.model") # 导入词性标注模块
postags = postagger.postag(words)
recognizer = NamedEntityRecognizer()
recognizer.load("D:/ltp_3.4/ner.model") #导入命名标注模块
netags = recognizer.recognize(words,postags)
for word,postag,netag in zip(words,postags,netags):
print(word+"/"+postag+"/"+netag)
执行结果为:
陕西/ns/B-Ns
西安/ns/E-Ns
是/v/O
一/m/O
座/q/O
古老/a/O
的/u/O
城市/n/O
。/wp/O
输出例句中“/”为分隔符,分隔符将结果按词为单位分为三段。例如,第一段是词“陕西”,第二段是词性“ns”,第三段“B-Ns”就是识别的专有名词。这里的标签“O”表示非专名,“S-Ns”表示地名。全部标签在后米娜的章节中有详细说明。
4.2 Stanford 命名实体识别
如果仅使用斯坦福的中文命名实体识别模块(也称为NER),可从从http://nlp.stanford.edu/software/CRF-NER.shtml下载。与词性标注的不同之处在于,命名实体识别模块的程序和中文模型库分开存放。应用程序可以从下图所示处下载。
斯坦福命名实体识别也可以通过Stanford-CoreNLP包运行。中文模型库内使用了基于词向量的语义相似度模型。运行该模型的前提条件需要首先进行中文分词,然后将分词结果(以空格分开的分词文本)作为输入,再运行命名实体识别模块进行输出。
仿照词性标注模块,编写一个Python命名实体类如下。
import os
from StanfordCoreNLP_Interface import StanfordCoreNLP_Interface
class StanfordNERTagger_Interface(StanfordCoreNLP_Interface):
def __init__(self,root,modelpath):
StanfordCoreNLP_Interface.__init__(self, root)
self.modelpath = modelpath # 模型文件路径
self.classfier = "edu.stanford.nlp.ie.crf.CRFClassifier"
self.__buildcmd()
# 构建命令行
def __buildcmd(self):
self.cmdline = 'java -mx2000m -classpath "'+self.jarlistpath+'" '+self.classfier+' -model "'+self.modelpath+'"'
# 标注文件,将标注的句子存储文件
def tagfile(self,sent,outpath):
self.savefile(self.inputpath,sent)
os.system(self.cmdline+' -textFile '+self.inputpath+' > '+outpath)
self.delfile(self.inputpath)
执行代码如下。
from StanfordNERTagger_Interface import StanfordNERTagger_Interface
root = 'D:/stanford-corenlp/'
modelpath = root + 'models/ner/chinese.misc.distsim.crf.ser.gz'
st = StanfordNERTagger_Interface(root,modelpath)
seg_sent = '欧洲 东部 的 罗马尼亚 , 首都 是 布加勒斯特 。 '
taglist = st.tagfile(seg_sent,"ner_test.txt")
输出结果为ner_test.txt,打开该文件可以看到执行结果为。
欧洲/LOCATION 东部/O 的/O 罗马尼亚/GPE ,/O 首都/O 是/O 布加勒斯特/GPE 。/O
Stanford 命名实体识别不需要词性标注,因此输出仅分为两段,标注集也比价简单。这里标签“O”表示非专名,“LOC”表示地名。其他标签会在后面章节中再做讲解。
5. 整合句法解析模块
【句法分析】(syntactic analysis)是根据给定的语法体系自动推导处句子的语法结构,分析句子所包含的语法单元和这些语法单元之间的关系,将句子转化为一个结构化的语法树。
目前句法分析有两种不同的理论:一种是【短语结构语法】;另一种是【依存语法】。
其中比较突出的是Ltp3.4中文句法分析系统,使用依存句法复分析理论。
除此之外,最著名的句法解析器是Stanford 句法解析器。截至2015年,Stanford句法数包含了如下三大主要解析器。
- PCFG概率解析器。是一个高度优化的词汇化PCFG依存解析器。该解析器使用A*算法,是一个随机上下文无关文法解析器。除英语之外,该解析器还包含一个中文版本,使用宾州中文树库训练。解析器的输出格式包含依存关系输出和短语结构树输出。
- Shift-Reduce解析器。为了提高PCFG概率解析器的性能,Stanford提供了一个基于移进–归约算法(Shift-Reduce)的高性能解析器。其性能远高于任何PCFG解析器,而且精度上比其他任何版本(包括RNN)的解析器都更精准。
- 神经网络依存解析器。神经网络依存解析器是深度学习算法在句法解析器中的一个重要应用。它通过中心词和修饰词之间的依存关系来构建出句子的句法树。有关此方面的研究是目前NLP的研究重点。
本节延续第3节的系统,使用Ltp3.4和Stanford Parser来进行中文的文本解析。因为Stanford的句法解析器比较多,这里仅实现比较有代表性的PCFG解析器。
5.1 Ltp 3.4 句法依存树
继续使用Ltp3.4中文命名实体识别模块。句法解析模块的文件名为parser.model。
为了简化,下面使用已经分好词的单句进行演示。
新建名为ltp_NER.py的文件。
import nltk
from nltk.tree import Tree # 导入nltk tree结构
from nltk.grammar import DependencyGrammar # 导入依存句法包
from nltk.parse import *
from pyltp import * # 导入ltp应用包
import re
sent = "陕西 西安 是 一 座 古老 的 城市 。"
# sent = "罗马尼亚 的 首都 是 布加勒斯特 。 "
words = sent.split(" ")
postagger = Postagger()
postagger.load("D:/ltp_3.4/pos.model") # 导入词性标注模块
postags = postagger.postag(words)
print(len(postags))
parser = Parser() # 将词性标注和分词结果都加入分析器中进行句法分析
parser.load("D:/ltp_3.4/parser.model")
arcs = parser.parse(words,postags)
print(type(arcs))
arclen = len(arcs)
print(arclen)
conll = ""
for i in range(arclen): # 构建Conll标准的数据结构
if arcs[i].head == 0:
arcs[i].relation = "ROOT"
conll += "\t"+words[i]+"("+postags[i]+")"+"\t"+postags[i]+"\t"+str(arcs[i].head)+"\t"+arcs[i].relation+"\n"
print(conll)
conlltree = DependencyGraph(conll) # 转换为句法依存图
tree = conlltree.tree() # 构建树结构
tree.draw() # 显示输出的树
显示的结果为
9
9
陕西(ns) ns 2 ATT
西安(ns) ns 3 SBV
是(v) v 0 ROOT
一(m) m 5 ATT
座(q) q 8 ATT
古老(a) a 8 ATT
的(u) u 6 RAD
城市(n) n 3 VOB
。(wp) wp 3 WP

上面的代码中的文本 “陕西 西安 是 一 座 古老 的 城市 。”,而如果换成是文本 "罗马尼亚 的 首都 是 布加勒斯特 。 " 就会报错。报错内容如下。
0
Traceback (most recent call last):
0
File “D:/PycharmProjects/NLP/ltp_syntacticAnalysis.py”, line 30, in
tree = conlltree.tree() # 构建树结构
File “D:\Anaconda3\envs\Anaconda-Pycharm\lib\site-packages\nltk\parse\dependencygraph.py”, line 413, in tree
word = node[‘word’]
TypeError: ‘NoneType’ object is not subscriptable
进程已结束,退出代码 1
错误意思是词性标注的内容为空,句法解析的内容更为空,所以导致无法对空对象生成句法依存树。错误原因可能是ltp对于这句话的部分词汇的未收录(猜的),导致无法词性标注,以及句法依存。
如上面正确的结果所示,将单句"陕西 西安 是 一 座 古老 的 城市 。"的解析结果给出如下结论:句法树是一棵依存关系树,根节点为其谓语动词“是”,主语是“西安”,“陕西”是修饰“西安”的定语,句子的宾语是“一座古老的城市”。
5.2 Stanford Parser 类
如果仅使用斯坦福的中文句法解析模块(也称为Parser),可从http://nlp.stanford.edu/software/lex-parser.shtml下载。语命名实体识别相同,Parser模块地程序和中文模型库也分开存放,但都在一处下载。应用程序和模型都可从图中所示的截图处下载。
这里仍旧使用stanford-corenlp中的模型和程序。在图目录列表中对应不同的句法解析器有不同的模型目录,分别为:lexparser、parser和srparser。其中PCFG概率解析器模型为lexparser;Shift-Reduce解析器模型为srparser;神经网络依存解析器模型为parser。以lexparser为例,下图所示的5个模型分别用于lexparser解析器的调用,最常用的库是chinesePCFG.ser.gz文件。该文件支持高度精确的词汇解析器。

最后,仿照前两节,编写一个python的StanfordParser接口类如下。
新建StanfordParser_Interface.py
from StanfordCoreNLP_Interface import StanfordCoreNLP_Interface
import os
class StanfordParser(StanfordCoreNLP_Interface):
def __init__(self,modelpath,jarpath,opttype):
StanfordCoreNLP_Interface.__init__(self,jarpath)
self.modelpath = modelpath # 模型文件路径
self.classfier = "edu.stanford.nlp.parser.lexparser.LexicalizedParser"
self.opttype = opttype
self.__buildcmd()
# 构建命令行
def __buildcmd(self):
self.cmdline = 'java -mx500m -classpath "'+self.jarlistpath+'" '+self.classfier+' -outputFormat "'+self.opttype+'" '+self.modelpath+' '
# 解析句子输出到文件
def tagfile(self,sent,outputpath):
self.savefile(self.inputpath,sent)
os.system(self.cmdline+self.inputpath+' > '+outputpath)
fp = open(outputpath,'r',encoding='utf-8')
result = fp.read()
print(type(result))
print(result)
self.delfile(self.inputpath)
return result
5.3 Stanford 短语结构树
以短语结构的方式输出,内容如下。
from nltk.tree import Tree # 导入nltk库
from stanford import *
from StanfordParser_Interface import StanfordParser
root = "D:/stanford-corenlp/"
modelpath = root+'models/lexparser/chinesePCFG.ser.gz'
opttype = 'penn' # 宾州树库格式
parser = StanfordParser(modelpath,root,opttype)
seg_sent = "罗马尼亚 的 首都 是 布加勒斯特 。 "
print(type(seg_sent))
result = parser.tagfile(seg_sent,"result.txt")
print(result)
tree = Tree.fromstring(result)
tree.draw()
输出结果如下:
(ROOT
(IP
(NP
(DNP
(NP (NR 罗马尼亚))
(DEG 的))
(NP (NN 首都)))
(VP (VC 是)
(NP (NR 布加勒斯特)))
(PU 。)))

如图所示,短语结构树的叶子节点是每个词的词形,词形上一级节点是词性,再上一级节点是由多个词构成的短语组块,“NP”这里表示名词性短语,“DNP”是由NP+“的”构成的短语结构,“VP”是动词短语,“IP”是简单句。
5.4 Stanford 依存句法树
以依存句法的方式输出,内容如下。
from StanfordParser_Interface import StanfordParser
root = "D:/stanford-corenlp/"
modelpath = root+'models/lexparser/chinesePCFG.ser.gz'
opttype = 'typedDependencies' # "penn,typedDependencies"
parser = StanfordParser(modelpath,root,opttype)
result = parser.tagfile("罗马尼亚 的 首都 是 布加勒斯特 。 ",'result.txt')
print(result)
输出结果如下。
nmod:assmod(首都-3, 罗马尼亚-1)
case(罗马尼亚-1, 的-2)
nsubj(布加勒斯特-5, 首都-3)
cop(布加勒斯特-5, 是-4)
root(ROOT-0, 布加勒斯特-5)
punct(布加勒斯特-5, 。-6)
Stanford依存树库的标注系统与Ltp的标注系统不同,具有更为复杂的依存结构。“root”是根节点,一般对应一个谓语(VP+NP),这里对应着的“是”,它是一个“cop”——系表助动词结构。因此,用它后面的NP结构作为根节点,剩下的部分就很容易了。“nsubj”表示名词性主语,在这个主语的内部,“首都”被“罗马尼亚”修饰,“assmod”表示关联修饰,“的”依存于“罗马尼亚”,“case”表示句法依赖。
这个结果与Ltp的分析结果略有不同,这是由标注规范的不一致导致的。有关标注规范的更多细节,第 6 章将给出具体说明。
6. 整合语义角色标注模块
语义角色标注(Semantic Role Labeling,SRL)来源于20世纪60年代美国语言学家菲尔墨提出的格语法理论。在菲尔墨看来,格关系是句子深层结构中的名词和谓语动词之间的一种固定不变的语义结构古关系(谓词——论元关系),而这种关系和具体语言中的表层结构上的语法结构没有一一对应关系。换句话说,由同样为此——论元结构支配的,但语法结构不同的句子,其语义应该是相同的。
该理论是在句子语义理解上的一个重要突破。基于此理论,语义角色标注就发展起来了,并成为句子语义分析的一种重要方式。它采用“谓词——论元角色”的结构形式,标注句法成分相对于给定谓语动词的语义角色,每个语义角色被赋予一定的语义。
美国宾州大学已经开发处一个对使用价值的表示语义命题库,成为PropBank。在本书的后续章节将会对该主题库做一个全面和深入的分析。
语义角色标注系统已经处于NLP系统的末端,其精度和效率都收前面几个模块的影响,所以,当前系统的精度都不高,在中文良玉还没有投入商业应用过的成功案例,本节介绍的是Ltp3.4中文语义角色标注系统。
报错 1
labeller.load(os.path.join(MODELDIR,“pisrl.model”))# 加载语义角色标注模型
RuntimeError: incompatible native format - size of long
解决办法
在Ltp版本为3.4.0的模型文件,其中一个文件pisrl.model,如在windows系统下不可用,可以到 此链接 下载支持windows的语义角色标注模型文件pisrl_win.model,放到ltp_3.4的目录下。也可以到此链接http://ltp.ai/download.html下找到。
报错 2
roles = labeller.label(words,postags,netags,arcs)# 设置命名标注对象
报错内容如下。
Traceback (most recent call last):
File "D:/PycharmProjects/NLP/ltp_SRL.py", line 33, in <module>
roles = labeller.label(wordlist,postags,netags,arcs)# 设置命名标注对象
Boost.Python.ArgumentError: Python argument types in
SementicRoleLabeller.label(SementicRoleLabeller, list, VectorOfString, VectorOfString, VectorOfParseResult)
did not match C++ signature:
label(struct SementicRoleLabeller {
lvalue}, class boost::python::list, class boost::python::list, class std::vector<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > >,class std::allocator<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > > >)
label(struct SementicRoleLabeller {
lvalue}, class boost::python::list, class std::vector<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> >,class std::allocator<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > >, class std::vector<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > >,class std::allocator<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > > >)
label(struct SementicRoleLabeller {
lvalue}, class std::vector<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> >,class std::allocator<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > >, class boost::python::list, class std::vector<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > >,class std::allocator<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > > >)
label(struct SementicRoleLabeller {
lvalue}, class std::vector<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> >,class std::allocator<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > >, class std::vector<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> >,class std::allocator<class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > >, class std::vector<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > >,class std::allocator<struct std::pair<int,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > > > >)
这个报错的内容极其可恨啊,我想了4个小时终于得以解决,我在网上找了很长时间,都是直接跳过这个问题的解决办法不回答,或者没有遇到这个问题。
问题原因
根据原书(《NLP汉语自然语言原理处理与实践》)上的代码我进行重现,然而,这里面有一个巨大的坑,待我慢慢道来。
首先是前面2.1节处的步骤3中的提到的pyltp安装包目录,这里再提供一次图片。

这个文件中src文件夹中有一个至关重要的文件pyltp.cpp这是一个C++类型的文件,是wrap.cpp文件。想学的话参考 此链接,但这不是重点。文件中有一段内容 line 285~344 ,关于SementicRoleLabeller,如下。
struct SementicRoleLabeller {
SementicRoleLabeller()
: loaded(false) {
}
void load(const std::string& model_path) {
loaded = (srl_load_resource(model_path) == 0);
}
std::vector<SementicRole> label(
const std::vector<std::string>& words,
const std::vector<std::string>& postags,
const std::vector<ParseResult>& parse
) {
std::vector<SementicRole> ret;
// Some trick
std::vector<ParseResult> tmp_parse(parse);
for (std::size_t i = 0; i < tmp_parse.size(); ++ i) {
tmp_parse[i].first --;
}
if (!loaded) {
std::cerr << "SRL: Model not loaded!" << std::endl;
} else {
srl_dosrl(words, postags, tmp_parse, ret);
}
return ret;
}
std::vector<SementicRole> label(
const std::vector<std::string>& words,
const boost::python::list& postags,
const std::vector<ParseResult>& parse
) {
return label(words, py_list_to_std_vector<std::string>(postags), parse);
}
std::vector<SementicRole> label(
const boost::python::list& words,
const std::vector<std::string>& postags,
const std::vector<ParseResult>& parse
) {
return label(py_list_to_std_vector<std::string>(words), postags, parse);
}
std::vector<SementicRole> label(
const boost::python::list& words,
const boost::python::list& postags,
const std::vector<ParseResult>& parse
) {
return label(py_list_to_std_vector<std::string>(words), py_list_to_std_vector<std::string>(postags), parse);
}
void release() {
if (loaded) {
srl_release_resource();
}
}
bool loaded;
};
其中有四个重构函数,注意了,参数都是(words,postags,parse),我们在执行roles = labeller.label(words,postags,netags,arcs)# 设置命名标注对象的过程中就是调用这个Wrap代码,然而参数不对应,这就是为什么错了(心里一万个FUCK,这谁写的Wrap,不写完整,真FUCK,认真点好不好???绝对不会再用Ltp做NLP工作,FUCK)。
解决办法
删除netags这个参数。
执行代码如下。
import os
from pyltp import *
MODELDIR = "D:/ltp_3.4/"
sentence = "欧洲东部的罗马尼亚,首都是布加勒斯特,也是一座世界性的城市。"
segmentor = Segmentor() # 实例化分词模块
segmentor.load(os.path.join(MODELDIR,"cws.model"))# 加载专有名词词典
print(os.path.join(MODELDIR,"cws.model"))
words = segmentor.segment(sentence)# 设置分词对象
print(words)
wordlist = list(words) # 生成器变为列表元素
postagger = Postagger() # 实例化词性标注模块
postagger.load(os.path.join(MODELDIR,"pos.model"))# 加载词性标注模型
postags = postagger.postag(words)# 设置词性标注对象
print(postags)
parser = Parser()# 实例化句法分析模块
parser.load(os.path.join(MODELDIR,'parser.model'))# 加载句法分析模型
arcs = parser.parse(words,postags)# 设置句法分析对象
print(arcs)
recognizer = NamedEntityRecognizer()#实例化命名标注模块
recognizer.load(os.path.join(MODELDIR,"ner.model"))# 加载命名标注模型
netags = recognizer.recognize(words,postags)# 设置命名标注对象
print(netags)
labeller = SementicRoleLabeller()# 实例化语义角色标注模块
labeller.load(os.path.join(MODELDIR,"pisrl_win.model"))# 加载语义角色标注模型
print(os.path.join(MODELDIR,"pisrl_win.model"))
roles = labeller.label(words,postags,arcs)# 设置命名标注对象
print(roles)
# 输出标注结果
for role in roles:
print('rel:',wordlist[role.index]) # 谓词
for arg in role.arguments:
if arg.range.start != arg.range.end:
print(arg.name,"".join(wordlist[arg.range.start:arg.range.end]))
else:
print(arg.name,wordlist[arg.range.start])
执行结果如下。
rel: 是
A0 欧洲东部的罗马尼亚
A0 首都
A1 布加勒斯特
rel: 是
A0 欧洲东部的罗马尼亚
A0 首都
ADV 也
A1 一座世界性的
这里“rel”标签表示的是谓词,“A0”指动作的施事,“A1”指动作的受事。关于其他标签,再后面章节会专门讲解。
7. 结语
本章节终于暂时结束,千里之行,始于足下,欢迎评论。