GoogLeNet-论文阅读及paddlepaddle复现
论文原文链接(百度云资源): https://pan.baidu.com/s/1KPiQqBRLS6ZPufkJShWlBQ 密码:hans
该篇文章主要包括两部分内容:
一、论文中的小知识点
二、paddlepaddle复现GoogLeNet(该篇文章只复现了inception v1 模块,关于v2、v3、v4会在后面的文章陆续复现)
知识点:
1、背景知识:视觉皮层包含了一系列复杂的细胞,这些细胞中的每个细胞只是对一个视觉区域内的一小部分敏感(稀疏连接,sparse connect),而对其它部分则可以视而不见,被称为局部感受野(receptive field),而这些receptive field的叠加就构成了visual field,这一点很像inception module(融合不同的信息)。
2、inception module:从LeNet到AlexNet再到VGG,人们似乎习惯了这种卷积加pooling的方式,并且习以为常的通过增加这种操作的层数来增加模型深度和宽度,从而提高模型“质量”。但是,如果一味的通过这种方式来增加模型的深度(层数layer)和宽度(卷积核数),会使参数量迅速增长,消耗大量计算资源;网络计算复杂度大,无法部署推理;反向传播时易造成梯度消失,难以优化模型。于是问题便来了,怎样才能在增加模型深度和宽度的同时又能减少参数量从而解决这些问题呢?在论文introduction部分有这样一句话:One encouraging news is that most of this progress is not just the result of more powerful hardware, larger datasets and bigger models,but mainly a consequence of new ideas , algorithms and improved network architectures.作者在拥有这样的认识下便“构造出了”inception module,这样的一种结构(如下图:)。

图a是原始inception module(naive version)。图b是(with dimensionality reduction)版本,加入了1x1卷积进行降维。
所以inception module到底是怎么减少计算量的呢?(1x1卷积)如果没有加入1x1卷积的话,对于3x3卷积、5x5卷积的分支,它们会使输出越积越厚,concat的时候输出向量维度更深,随着网络的加深,inception模块的增加,会是的计算量爆炸。因此引入了1x1卷积来降维。
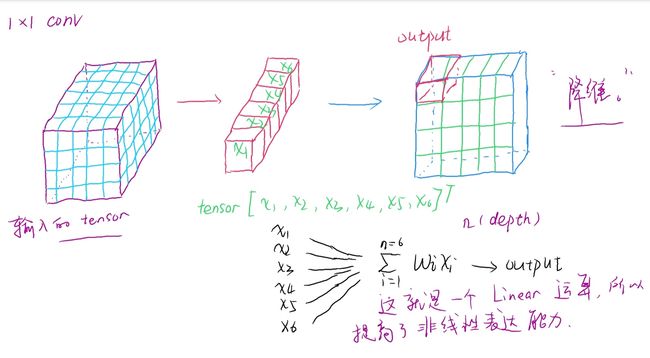
当然1x1卷积不仅仅有降维的作用;还能使信息跨通道交融;减少参数量;增加模型的深度,提高非线性表达能力。具体解释,见下图:
3、concat与add的区别:
concat是将向量进行叠加的操作,沿着一个(axis)方向进行,会使向量在这个方向上越来越厚;而add操作是将相同维度的向量相加,也就是加操作,不会改变向量的维度。通过paddlepaddle的concat、add两个api来实现。
5、GoogLeNet:


!unzip -q -o data/data68755/signs.zip
#该程序用于生成标签文件
#使用了十二生肖数据集
import os
data_root = "signs"
classes = ["rooster", "tiger", "dragon", "snake", "ratt", "ox", "monkey", "dog", "goat", "pig", "horse", "rabbit"]
k = 0
def generate_txt(mode):
with open ("{}/{}.txt".format(data_root, mode), "w") as f:
train_path = "{}/{}".format(data_root, mode)
for classe in os.listdir(train_path):
label = classes.index(classe)
image_path = "{}/{}".format(train_path, classe)
for image in os.listdir(image_path):
image_file = "{}/{}".format(image_path, image)
f.write("{}\t{}\n".format(image_file, label))
global k
k += 1
generate_txt('train')
m = k
print(m)
generate_txt("test")
n = k - m
print(n)
generate_txt("valid")
z = k - m - n
print(z)
7200
660
660
#将图片路径及标签放到一个列表中
data = []
with open("signs/{}.txt".format("train")) as f:
for line in f.readlines():
info = line.strip().split("\t")
#print(info)
data.append([info[0].strip(), info[1].strip()])
#测试:
image_file, label = data[1]
print(image_file)
print(label)
signs/train/goat/00000139.jpg
8
#加载数据集
import paddle
from paddle.io import Dataset
from paddle.vision import transforms as T
import numpy as np
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
class mydataset(Dataset):
def __init__(self, mode):
self.mode = mode
self.data = []
with open("signs/{}.txt".format(mode)) as f:
for line in f.readlines():
info = line.strip().split("\t")
if (len(info) > 0):
self.data.append([info[0].strip(), info[1].strip()])
if mode == "train":
self.transforms = T.Compose([T.RandomHorizontalFlip(0.5),
T.Resize((224, 224)),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), data_format="CHW")])
else:
self.transforms = T.Compose([
T.Resize((224, 224)),
T.ToTensor()
])
def __getitem__(self, index):
image_file, label = self.data[index]
image = Image.open(image_file)
if image.mode != "RGB":
image = image.convert("RGB")
image = self.transforms(image)
return image, np.array(label, dtype="int64")
def __len__(self):
return len(self.data)
train_dataset = mydataset("train")
test_dataset = mydataset("test")
valid_dataset = mydataset("valid")
from paddle.io import DataLoader
trainset = DataLoader(train_dataset, batch_size=64, shuffle=True)
testset = DataLoader(test_dataset, batch_size=64, shuffle=True)
validset =DataLoader(valid_dataset, batch_size=64, shuffle=True)
#GoogLeNet
#inception v1
import paddle
from paddle.nn import Layer
import paddle.nn as nn
#inception v1 parameters:
inception_3a = {
'in_channel':192, '_1filter':64, '_3filter':128, '_5filter':32, '_3reduce':96, '_5reduce':16, 'pool_proj':32}
inception_3b = {
'in_channel':256, '_1filter':128, '_3filter':192, '_5filter':96, '_3reduce':128, '_5reduce':32, 'pool_proj':64}
inception_4a = {
'in_channel':480, '_1filter':192, '_3filter':208, '_5filter':48, '_3reduce':96, '_5reduce':16, 'pool_proj':64}
inception_4b = {
'in_channel':512, '_1filter':160, '_3filter':224, '_5filter':64, '_3reduce':112, '_5reduce':24, 'pool_proj':64}
inception_4c = {
'in_channel':512, '_1filter':128, '_3filter':256, '_5filter':64, '_3reduce':128, '_5reduce':24, 'pool_proj':64}
inception_4d = {
'in_channel':512, '_1filter':112, '_3filter':288, '_5filter':64, '_3reduce':144, '_5reduce':32, 'pool_proj':64}
inception_4e = {
'in_channel':528, '_1filter':256, '_3filter':320, '_5filter':128, '_3reduce':160, '_5reduce':32, 'pool_proj':128}
inception_5a = {
'in_channel':832, '_1filter':256, '_3filter':320, '_5filter':128, '_3reduce':160, '_5reduce':32, 'pool_proj':128}
inception_5b = {
'in_channel':832, '_1filter':384, '_3filter':384, '_5filter':128, '_3reduce':192, '_5reduce':48, 'pool_proj':128}
#inception v1 moudle:这里将inception Moudle写成一个类,是为了,后边便于扩展到v2、v3、v4。
#不过这篇文章暂时只写了v1,后面可能会继续复现v2、v3、v4
class inception_v1(Layer):
def __init__(self, input_activation, parameters={
}):
super(inception_v1, self).__init__()
self.input_ = input_activation
self.in_channel = parameters['in_channel']
self.filter_1x1 = parameters['_1filter']
self.filter_3x3 = parameters['_3filter']
self.filter_5x5 = parameters['_5filter']
self.reduce_3 = parameters['_3reduce']
self.reduce_5 = parameters['_5reduce']
self.proj = parameters['pool_proj']
self.relu = nn.ReLU()
def conv(self, in_channel, out_channel, kernel_size, stride, paddling, in_x):
conv_ = nn.Conv2D(in_channel, out_channel, kernel_size, stride, paddling)
x = conv_(in_x)
return x
def max_pool(self, kernel_size, stride, paddling, in_x):
maxpool = nn.MaxPool2D(kernel_size, stride, paddling)
x = maxpool(in_x)
return x
#max_pool branch:
def max_pool_branch(self, input_data):
x = self.max_pool(3, 1, 1, input_data)
x = self.conv(self.in_channel, self.proj, 1, 1, 0, x)
x = self.relu(x)
return x
#5x5_conv_branch:
def conv_5x5_branch(self, input_data):
x = self.conv(self.in_channel, self.reduce_5, 1, 1, 0, input_data)
x = self.relu(x)
x = self.conv(self.reduce_5, self.filter_5x5, 5, 1, 2, x)
x = self.relu(x)
return x
#3x3_conv_brabch:
def conv_3x3_branch(self, input_data):
x = self.conv(self.in_channel, self.reduce_3, 1, 1, 0, input_data)
x = self.relu(x)
x = self.conv(self.reduce_3, self.filter_3x3, 3, 1, 1, x)
x = self.relu(x)
return x
def forword_v1(self, input_):
branch_pool = self.max_pool_branch(input_)
branch_3 = self.conv_3x3_branch(input_)
branch_5 = self.conv_5x5_branch(input_)
branch_1 = self.conv(self.in_channel, self.filter_1x1, 1, 1, 0, input_)
out = paddle.concat(x = [branch_pool, branch_3, branch_5, branch_1], axis=1)
#x = branch_pool + branch_3 + branch_5 + branch_1
#print(out)
return out
#inception_v1_arch:
inception_v1_arch_list= [
inception_3a,
inception_3b,
inception_4a,
inception_4b,
inception_4c,
inception_4d,
inception_4e,
inception_5a,
inception_5b
]
#GoogleNet:
class GoogLeNet(Layer):
def __init__(self, num_classes, inception_arch_list, inception):
super(GoogLeNet, self).__init__()
self.inception = inception
self.inception_arch_list = inception_arch_list
self.num_classes = num_classes
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.4)
self.conv1 = nn.Conv2D(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.conv2 = nn.Conv2D(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.max_pool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.avg_pool = nn.AvgPool2D(kernel_size=7, stride=1)
self.flatten = nn.Flatten()
self.linear = nn.Linear(in_features=1024, out_features=num_classes)
self.softmax = nn.Softmax()
def forward(self, input_data):
x = self.conv1(input_data)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool(x)
if self.inception == 'v1':
v1_3a = inception_v1(x, self.inception_arch_list[0])
x = v1_3a.forword_v1(x)
v1_3b = inception_v1(x, self.inception_arch_list[1])
x = v1_3b.forword_v1(x)
x = self.max_pool(x)
v1_4a = inception_v1(x, self.inception_arch_list[2])
x = v1_4a.forword_v1(x)
v1_4b = inception_v1(x, self.inception_arch_list[3])
x = v1_4b.forword_v1(x)
v1_4c = inception_v1(x, self.inception_arch_list[4])
x = v1_4c.forword_v1(x)
v1_4d = inception_v1(x, self.inception_arch_list[5])
x = v1_4d.forword_v1(x)
v1_4e = inception_v1(x, self.inception_arch_list[6])
x = v1_4e.forword_v1(x)
x = self.max_pool(x)
v1_5a = inception_v1(x, self.inception_arch_list[7])
x = v1_5a.forword_v1(x)
v1_5b = inception_v1(x, self.inception_arch_list[8])
x = v1_5b.forword_v1(x)
x = self.avg_pool(x)
x = self.dropout(x)
x = self.flatten(x)
x = self.linear(x)
x = self.softmax(x)
return x
GoogLeNet_v1_model = paddle.Model(GoogLeNet(12, inception_v1_arch_list, 'v1'))
GoogLeNet_v1_model.summary((64, 3, 224, 224))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[64, 3, 224, 224]] [64, 64, 112, 112] 9,472
ReLU-1 [[64, 192, 56, 56]] [64, 192, 56, 56] 0
MaxPool2D-1 [[64, 832, 14, 14]] [64, 832, 7, 7] 0
Conv2D-2 [[64, 64, 56, 56]] [64, 192, 56, 56] 110,784
AvgPool2D-1 [[64, 1024, 7, 7]] [64, 1024, 1, 1] 0
Dropout-1 [[64, 1024, 1, 1]] [64, 1024, 1, 1] 0
Flatten-1 [[64, 1024, 1, 1]] [64, 1024] 0
Linear-1 [[64, 1024]] [64, 12] 12,300
Softmax-1 [[64, 12]] [64, 12] 0
===========================================================================
Total params: 132,556
Trainable params: 132,556
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 36.75
Forward/backward pass size (MB): 1001.42
Params size (MB): 0.51
Estimated Total Size (MB): 1038.67
---------------------------------------------------------------------------
{'total_params': 132556, 'trainable_params': 132556}
#模型的训练:
rate = 0.01
epochs = 90
Batchsize = 16
GoogLeNet_v1_model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=rate, parameters=GoogLeNet_v1_model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
GoogLeNet_v1_model.fit(trainset, epochs=epochs, batch_size=Batchsize, verbose=1)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/90
step 10/113 [=>............................] - loss: 2.5875 - acc: 0.0797 - ETA: 2:34 - 2s/step