支持向量机(Support Vector Machines)
优化目标(Optimization objective)
- SVM:是一个用于分类的算法,简单来说就是找到是数据分为不同种类的分界线。当一个分类问题是线性可分的,也就是只用一根棍子将小球分开,我们只要将棍的位置放在让小球距离棍的最大距离,即寻找最大间隔的过程,就叫最优化。
如图分类器B比分类器C具有更有的分类效果。不同方向的最优决策面的分类间隔通常是不同的,那个具有最大间隔的决策面j就是SVM要寻找的最优解,真正最优解对应两侧虚线所穿过的样本点,就是SVM的支持样本点,称为“支持向量”。

-
目的:最小化参数向量的平方
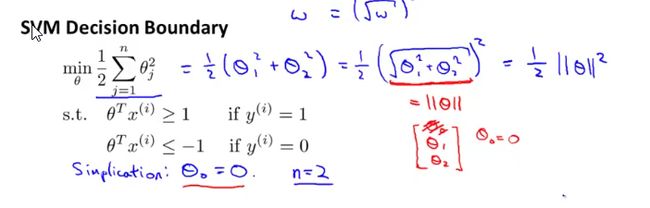
02. 如何寻找最大间隔
-
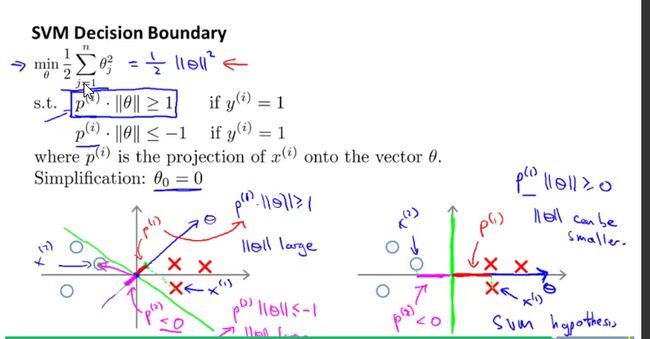
寻找决策平面的最大间隔问题可以转化为寻找参数向量长度最小值的过程(参数向量theta是一条垂直决策平面的向量),p为样本点在参数向量上面的投影向量。当p较大的时候,theta长度就比较小,故此时对应最优解。
Kernels
Kernels1
-
用核函数来找出非线性决策边界,来区分正负样本。

-
改变之前的使用高次方作为特征为另一个公式:
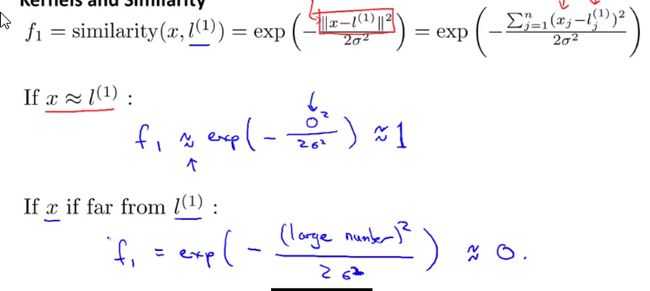
-
判定边界的过程:
用大量样本来判定,根据样本和哪个标记点(L1、L2)比较近,就套用哪个点的公式,最后在离标记点比较近的点附近判定的结果都为1,远离的地方判定结果都为0.故在相似点周围找到一条非线性边界。

02.Kernels
寻找标记点:给定X1-Xm的训练样本,标记点L1-Lm就为X1-Xm.
-
SVM with Kernels:
给定一个样本,根据相似度公式计算出f特征函数(m+1维)。
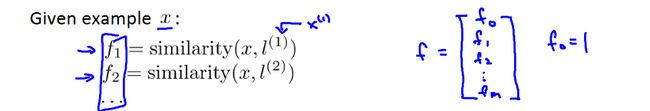
若满足:
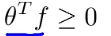
则可预测y=1
theta可从代价函数中得到:
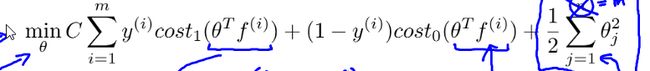
SVM中的参数:

C大,则对应小lamda:低偏差,高误差
C小,则对应大lamda:高偏差,低误差

SVM in practice
- 可以使用库(liblinear、libsvm)来解决参数theta问题。但依然需要我们做的是:
找出参数C
-
选择是否使用kernels函数
2.1
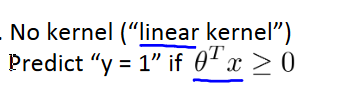
2.2
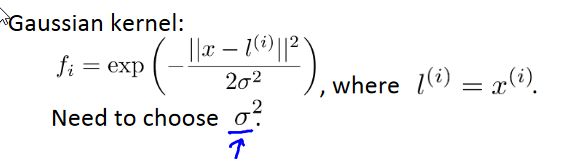
-
kernels函数的实现:
注意在实现过程中一定要先进行特征缩放,因为当某一特征值的数据太大,就会导致使得另一些特征的影响效果不明显。

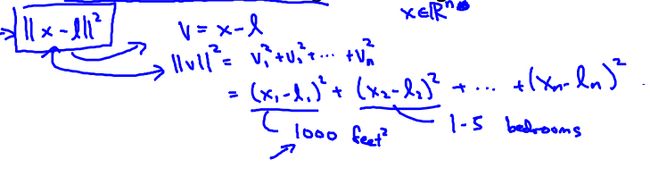
比如说第一个特征为房间面积特征,第二个特征为房间数目特征,就会使结果只受面积特征影响。
如何选择(n为特征数目,m为训练样本数目):
n>>m:逻辑回归或者没有kernels的SVM
因为训练样本数据不多的话,仅仅用线性方程就能很好实现n小,m适中:使用带有Gaussian kernels的SVM
n小,m大:增加特征后,选择逻辑回归或者没有kernels的SVM
神经网络可能对这几种情况都适用,但是训练的较慢