Hadoop全分布式搭建步骤详解
1、Hadoop的全分布式集群搭建步骤
1.1完全分布式模式介绍
完全分布式,指的是在真实环境下,使用多台机器,共同配合,来构建一个完整的分布式文件系
统。
在真实环境中,hdfs中的相关守护进程也会分布在不同的机器中,比如:
-1. namenode守护进程尽可能的单独部署在一台硬件性能相对来说比较好的机器中。
-2. 其他的每台机器上都会部署一个datanode守护进程,一般的硬件环境即可。
-3. secondarynamenode守护进程最好不要和namenode在同一台机器上。
1.2平台软件说明
操作系统 Windows7 或 Windows 10 或 Mac OS
虚拟软件 VMWare 或 Parallels Desktop(Mac Only)
虚拟机
主机名: master,IP地址: 192.168.10.101
主机名: node2,IP地址: 192.168.10.102
主机名: node3,IP地址: 192.168.10.103
SSH工具 MobaXterm(Windows) 或 FinalShell(Mac)
SSH工具 MobaXterm(Windows) 或 FinalShell(Mac)
SSH工具 MobaXterm(Windows) 或 FinalShell(Mac)
JDK jdk-8u221-linux-x64.tar.gz
Hadoop hadoop-2.7.6.tar.gz
Hadoop hadoop-2.7.6.tar.gz
切记,切记,切记:
实际生产环境中,我们不会使用root用户来搭建和管理hdfs,而是使用普通用户。这里为了方便
学习,我们才使用的root用户。
注意,注意,注意:
1.如果你是从伪分布式过来的,最好先把伪分布式的相关守护进程关闭:stop-all.sh
2.删除原来伪分布式的相关设置
如果原来使用的是默认路径,现在已经没有用了
如果原来使用的跟现在全分布式路径一样,因为这里跟之前的初始化的内容不一样,而且这个文件要
让系统自动生成
综上:要删除掉namenode和datanode的目录
1.3守护进程布局
我们搭建hdfs的完全分布式,顺便搭建一下yarn。hdfs和yarn的相关守护进程的布局如下:
master: namenode,datanode,ResourceManager,nodemanager
node2: datanode,nodemanager,secondarynamenode
node3: datanode,nodemanager
1.4完全分布式搭建环境准备
1.4.1 总纲
-1. 三台机器的防火墙必须是关闭的.
-2. 确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置)
-3. 确保/etc/hosts文件配置了ip和hostname的映射关系
-4. 确保配置了三台机器的免密登陆认证(克隆会更加方便)
-5. 确保所有机器时间同步
-6. jdk和hadoop的环境变量配置
1.4.2 关闭防火墙
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
[root@master ~]# systemctl stop NetworkManager
[root@master ~]# systemctl disable NetworkManager
#最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为
disabled
[root@master ~]# vi /etc/selinux/config
.........
SELINUX=disabled
.........
情况说明: 如果安装好三台机器,三台机器的防火墙都需要单独关闭和设置开机不启 动。如果准备使用克隆方式,只关闭master机器即可。下面的配置也是如此。
1.4.3 静态IP和主机名配置
--1. 配置静态IP(确保NAT模式)
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
............
BOOTPROTO=static # 将dhcp改为static
............
ONBOOT=yes # 将no改为yes
IPADDR=192.168.10.101 # 添加IPADDR属性和ip地址
PREFIX=24 # 添加NETMASK=255.255.255.0或者PREFIX=24
GATEWAY=192.168.10.2 # 添加网关GATEWAY
DNS1=114.114.114.114 # 添加DNS1和备份DNS
DNS2=8.8.8.8
--2. 重启网络服务
[root@master ~]# systemctl restart network
或者
[root@master ~]# service network restart
--3. 修改主机名(如果修改过,请略过这一步)
[root@localhost ~]# hostnamectl set-hostname master
或者
[root@localhost ~]# vi /etc/hostname
master
1.4.4 配置/etc/hosts文件
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4
::1 localhost localhost.localdomain localhost6
localhost6.localdomain6
192.168.10.101 master #添加本机的静态IP和本机的主机名之间的映射关系
192.168.10.102 node2
192.168.10.103 node3
1.4.5 免密登陆认证
-1. 使用rsa加密技术,生成公钥和私钥。一路回车即可
[root@master ~]# cd ~
[root@master ~]# ssh-keygen -t rsa
-2. 进入~/.ssh目录下,使用ssh-copy-id命令
[root@master ~]# cd ~/.ssh
[root@master .ssh]# ssh-copy-id root@master
-3. 进行验证
[hadoop@master .ssh]# ssh master
#下面的第一次执行时输入yes后,不提示输入密码就对了
[hadoop@master .ssh]# ssh localhost
[hadoop@master .ssh]# ssh 0.0.0.0
注意:三台机器提前安装好的情况下,需要同步公钥文件。如果使用克隆技术。那么使用同
一套密钥对就方便多了
1.4.6 时间同步
- 配置ntp服务
将我们的一台主机配置成ntp服务器,同网段的其他主机可以通过ntpdate -u
host-addr命令以ntp服务器的时间来进行客户端的时间同步。
1.1 服务端
1.1.1 工具安装
我们需要先安装ntp服务和ntpdate工具:yum -y install ntp ntpdate 即使是作为服务端的主
机,在必要时刻也是需要向公用的ntp服务器进行时间同步的(一般不用)。
1.1.2 进行ntp服务文件配置
[root@master ~]# vim /etc/ntp.conf
注意:
1.大家自己在配置时,只需要把我的内容替换你的内容即可
2.授权下述网段上所有的机器允许从ntp服务器上查询和同步时间 restrict 192.168.10.0
mask 255.255.255.0 nomodify notrap
保证这里的网段是你集群的网段即可
注意:
1.大家自己在配置时,只需要把我的内容替换你的内容即可
2.授权下述网段上所有的机器允许从ntp服务器上查询和同步时间 restrict 192.168.10.0
mask 255.255.255.0 nomodify notrap
保证这里的网段是你集群的网段即可
driftfile /var/lib/ntp/drift
# 默认情况下,NTP服务器的日志保存在 /var/log/messages.当然我们也可以自己指定
# 自己指定日志目录
# 我们要确保他的属性和SELinux环境(这两项一般不用改)
# chown ntp:ntp /var/log/ntpd.log
# chcon -t ntpd_log_t /var/log/ntpd.log
logfile /var/log/ntpd.log
restrict default nomodify notrap nopeer noquery
# 给与本机所有权限
restrict 127.0.0.1
restrict ::1
#授权下述网段上所有的机器允许从ntp服务器上查询和同步时间
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
#增加下述几个时间服务器列表,除了0.asia.pool.ntp.org还会有很多时间服务器.比如
0.cn.pool.ntp.org或者time.nist.gov或者
server 0.asia.pool.ntp.org iburst
server 1.asia.pool.ntp.org iburst
server 2.asia.pool.ntp.org iburst
server 3.asia.pool.ntp.org iburst
#这两行内容表示当外部时间不可用时,使用本地时间
server 127.127.1.0 iburst
fudge 127.127.1.0 stratum 10
#下述四行表示允许上层服务器修改本机时间
restrict 0.asia.pool.ntp.org nomodify notrap noquery
restrict 1.asia.pool.ntp.org nomodify notrap noquery
restrict 2.asia.pool.ntp.org nomodify notrap noquery
restrict 3.asia.pool.ntp.org nomodify notrap noquery
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
disable monitor
1.1.3 设置开机自启动服务(初始化)
使服务端服务ntp的守护进程ntpd生效
[root@master ~]# systemctl enable ntpd
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service.
使客户端工具ntpdate工具生效(选做)
[root@master ~]# systemctl enable ntpdate
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpdate.service to /usr/lib/systemd/system/ntpdate.service.
检查
[root@master ~]# systemctl is-enabled ntpd
显示: enabled
1.1.4 启用ntp服务
[root@master ~]# systemctl start ntpd
查看ntpd进程
[root@master ~]# ps -ef | grep ntpd
ntp 1185 1 0 03:50 ? 00:00:00 /usr/sbin/ntpd -u ntp:ntp -g root 1663 1136 0 04:35 pts/2 00:00:00 grep --color=auto ntp
进程存在,说明服务已经正常启动
1.1.5 设置防火墙,放行ntp协议请求
提前将防火墙关闭即可
1.1.6 设置硬件时间
1.1.6.1 对时间的解释
linux的时间分为系统时间和硬件时间。
系统时间:
通常在开机时复制硬件时间,之后独立运行并保存了时间、时区和夏令时设置。通过date命令设
置。
硬件时间:
(RTC、Real-Time Clock),CMOS时间,在主板上靠电池供电,仅保存时期时间数值。通过
hwclock命令设置,在这里,我们用系统时间同步硬件时间:hwclock -w
同步前需要测试ntp上层服务器的连通性
1.1.6.2 查看ntp的情况
[root@master ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
+electrode.felix 89.231.96.83 2 u 56 64 1 286.235 9.133 0.971
*undefined.hostn 127.67.113.92 2 u 56 64 1 202.865 -7.224 13.201
-de-user.deepini 195.13.23.5 3 u 58 64 1 273.953 16.689 2.172
+ntp5.flashdance 192.36.143.153 2 u 55 64 1 321.711 10.639 4.733
LOCAL(0) .LOCL. 10 l 64 64 2 0.000 0.000 0.000
解释:
remote:即NTP主机的IP或主机名称.注意最左边是+表示目前正在起作用的上层NTP,如果是*表示
这个也连接上了,不过是作为次要联机的NTP主机
refid:参考的上一层NTP主机的地址
st:即stratum阶层
t:是连接类型. u代表单播(unicast) l代表本地(local) ,其他的还有多播(multicast),广播(broadcast)
when:这个时间之前刚刚做过时间同步
poll:下次更新在几秒之后
reach:已经向上层NTP服务器要求更新的次数
delay:网络传输过程中的延迟时间
offset:时间补偿的结果
jitter:Linux系统时间和Bios硬件时间的差异时间
1.1.6.3 执行同步
[root@master ~]# hwclock -w
1.1.6.4 测试
[root@master conf]# ntpstat synchronised to NTP server (78.46.102.180) at stratum 3 time correct to within 189 ms polling server every 64 s
说明本地已经与时间服务器实现了同步
1.2 客户端
1.2.1 安装ntp服务和ntpdate工具
[root@slave1 ~]# yum -y install ntp ntpdate
1 进行客户端与服务器端的时间同步
[root@node1 ~]# systemctl enable ntpdate
[root@node1 ~]# /usr/sbin/ntpdate -u 192.168.10.200
28 Mar 04:54:43 ntpdate[1727]: adjust time server 192.168.10.200 offset 0.000001 sec
2 让系统时间和硬件时间同步
[root@slave1 ~]# hwclock -w
3 可以设置定时器,定时执行,因为ntpdate每次执行完就失效了.
每天和主机同步一次 10 23 * * * (/usr/sbin/ntpdate -u 192.168.10.200 && /sbin/hwclock -w) &> /var/log/ntpdate.log
4 常见错误分析
常见错误分析: 客户端 执行 ntpdate master 显示:no server suitable for
synchronization found
原因:错误1.Server dropped: Strata too high(在客户端执行 ntpdate -d master可
以看到,且显示“stratum 16”。而正常情况下stratum这个值得范围是“0~15”)
解决:
这是因为NTP server还没有和其自身或者它的server同步上。
以下的定义是让NTP Server和其自身保持同步,如果在/ntp.conf中定义的server都不可用时,
将使用local时间作为ntp服务提供给ntp客户端。
server 127.127.1.0
fudge 127.127.1.0
stratum 8
1.4.7 安装Jdk和Hadoop,配置相关环境变量
-1. 上传和解压两个软件包,大家一定要找对自己安装包上传以及解压的位置,后面配置环境变量的时候记得写上自己安装的路径
[root@masert ~]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/
[root@masert ~]# tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/
-2. 进入local里,给两个软件更名
[root@masert ~]# cd /usr/local/
[root@masert local]# mv 1.8.0_221/ jdk
[root@masert local]# mv hadoop-2.7.6/ hadoop
-3. 配置环境变量
[hadoop@masert local]# vi /etc/profile
.....省略...........
#java environment
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
#hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
1.5Hadoop的配置文件
1.在完全分布式集群的配置中,需要配置的是4个配置文件
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
2.这几个配置文件有默认的配置,命名为default
core-default.xml
hdfs-default.xml
mapred-default.xml
yarn-default.xml
3.我们可以将默认的配置文件找出来,看看默认的配置
[root@master share]# cd /usr/local/hadoop/share
[root@master share]# find -name "*-default.xml" -exec cp {}
~/defaultXml \;
4.属性的优先级
代码中配置的属性 > *-site.xml > *-default.xml
1.6 完全分布式配置
1.配置core-site.xm
[root@master ~]# cd $HADOOP_HOME/etc/hadoop/
[root@master hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/tmpvalue>
property>
configuration>
2.配置hdfs-site.xml
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file://${hadoop.tmp.dir}/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file://${hadoop.tmp.dir}/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node2:50090value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>master:50070value>
property>
configuration>
3.配置mapred-site.xml
如果只是搭建hdfs,只需要配置core-site.xml和hdfs-site.xml文件就可以了,但是我们
后期的MapReduce是需要YARN资源管理器的,因此,在这里,我们提前配置一下相关文件。
(如果只是搭建全分布式集群,这一步可以省略)
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>
4.配置yarn-site.xml
[root@master hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>
5.配置hadoop-env.sh
[root@qianfeng01 hadoop]# vi hadoop-env.sh
.........
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
.........
6.配置slaves文件
# 此文件用于指定datanode守护进程所在的机器节点主机名
[root@master hadoop]# vi slaves
master
node2
node3
7.配置yarn-env.sh文件
# 此文件可以不配置,不过,最好还是修改一下yarn的jdk环境比较好
[root@master hadoop]# vi yarn-env.sh
.........
# some Java parameters
export JAVA_HOME=/usr/local/jdk
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
.........
1.7 另外两台机器配置说明
当把qianfeng01机器上的hadoop的相关文件配置完毕后,我们有以下两种方式来选择配置 另外几台机器的hadoop.
方式一: “scp”进行同步
提示:本方法适用于多台虚拟机已经提前搭建出来的场景。
--1. 同步hadoop到slave节点上
[root@master ~]# cd /usr/local
[root@master local]# scp -r ./hadoop node2:/usr/local/
[root@master local]# scp -r ./hadoop node3:/usr/local/
--2. 同步/etc/profile到slave节点上
[root@master local]# scp /etc/profile node2:/etc/
[root@master local]# scp /etc/profile node3:/etc/
--3. 如果slave节点上的jdk也没有安装,别忘记同步jdk。
--4. 检查是否同步了/etc/hosts文件
方式二: 克隆qianfeng01虚拟机
提示:本方法适用于还没有安装slave虚拟机的场景。通过克隆master节点的方式,来克隆
一个node2和node3机器节点,这种方式就不用重复安装环境和配置文件了,效率非
常高,节省了大部分时间(免密认证的秘钥对都是相同的一套)。
--1. 打开一个新克隆出来的虚拟机,修改主机名
[root@master ~]# hostnamectl set-hostname node2
--2. 修改ip地址
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
.........省略.........
IPADDR=192.168.10.102 <==修改为node2对应的ip地址
.........省略........
--3. 重启网络服务
[root@master ~]# systemctl restart network
--4. 其他新克隆的虚拟机重复以上1~3步
--5. 免密登陆的验证
从master机器上,连接其他的每一个节点,验证免密是否好使,同时去掉第一次的询
问步骤
--6. 建议:每台机器在重启网络服务后,最好reboot一下。
1.8. 格式化NameNode
1.注意事项
格式化完成NameNode后,会在core-site.xml中的配置hadoop.tmp.dir的路径下生成集群
相关的文件。如果之前在伪分布式的时候已经格式化完成,并且这个路径已经生成了,需要先
将这个目录手动删除掉,然后再格式化集群,否则会导致集群启动失败,NameNode和
DataNode无法建立连接。
2.在master机器上运行命令
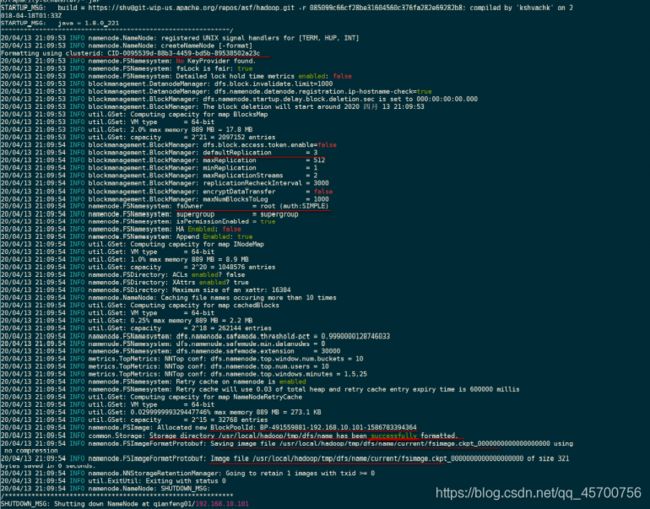
[root@master ~]# hdfs namenode -format
3.格式化的相关信息解读
--1. 生成一个集群唯一标识符:clusterid
--2. 生成一个块池唯一标识符:blockPoolId
--3. 生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录
--4. 生成镜像文件fsimage,记录分布式文件系统根路径的元数据
--5. 其他信息都可以查看一下,比如块的副本数,集群的fsOwner等。
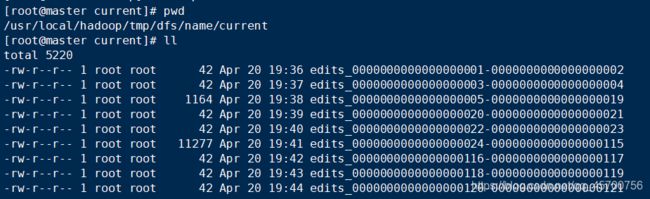
4.目录里的内容查看
[root@master current]# pwd
1.9. 启动集群
1.启动脚本和关闭脚本介绍
1. 启动脚本
-- start-dfs.sh :用于启动hdfs集群的脚本
-- start-yarn.sh :用于启动yarn守护进程
-- start-all.sh :用于启动hdfs和yarn
2. 关闭脚本
-- stop-dfs.sh :用于关闭hdfs集群的脚本
-- stop-yarn.sh :用于关闭yarn守护进程
-- stop-all.sh :用于关闭hdfs和yarn
3. 单个守护进程脚本
-- hadoop-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- hadoop-daemon.sh :用于单独启动或关闭hdfs的某一个守护进
程的脚本
reg:
hadoop-daemon.sh [start|stop]
[namenode|datanode|secondarynamenode]
-- yarn-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- yarn-daemon.sh :用于单独启动或关闭hdfs的某一个守护进
程的脚本
reg:
yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]
2.启动hdfs
1.使用start-dfs.sh,启动 hdfs。参考图片

2.启动过程解析
- 启动集群中的各个机器节点上的分布式文件系统的守护进程
一个namenode和resourcemanager以及secondarynamenode
多个datanode和nodemanager
- 在namenode守护进程管理内容的目录下生成edit日志文件
- 在每个datanode所在节点下生成${hadoop.tmp.dir}/dfs/data目录,参考下图:

3.jps查看进程
--1. 在master上运行jps指令,会有如下进程
namenode
datanode
--2. 在node2上运行jps指令,会有如下进程
secondarynamenode
datanode
--3. 在node3上运行jps指令,会有如下进程
datanode



4.启动yarn
1.使用start-yarn.sh脚本,参考图片

2.jps查看
--1. 在master上运行jps指令,会多出有如下进程
resoucemanager
nodemanager
--2. 在node2上运行jps指令,会多出有如下进程
nodemanager
--3. 在node3上运行jps指令,会多出有如下进程
nodemanager


