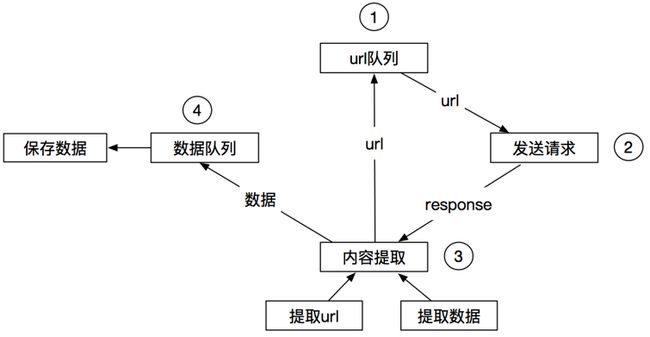
通用爬虫
爬虫的定义
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.
只要是浏览器能做的事情,原则上,爬虫都能够做
爬虫的分类
- 通用爬虫:通常指搜索引擎的爬虫
- 聚焦爬虫:针对特定网站的爬虫
http和https
HTTP
- 超文本传输协议
- 默认端口号:80
HTTPS
- HTTP + SSL(安全套接字层)
- 默认端口号:443
HTTPS比HTTP更安全,但是性能更低
HTTP常见请求头

响应状态码(status code)
200:成功
302:临时转移至新的url
307:临时转移至新的url
404:not found
500:服务器内部错误
str类型和bytes类型
bytes:二进制
互联网上数据的都是以二进制的方式传输的
str :unicode的呈现形式
str bytes如何转化
str 使用encode方法转化为 bytes
bytes通过decode转化为str
编码方式解码方式必须一样,否则就会出现乱码
decode(解码)
encode(编码)
Requests
作用:发送网络请求,返回响应数据
为什么要学习requests?
requests的底层实现就是urllib
requests在python2 和python3中通用,方法完全一样
requests简单易用
Requests能够自动帮助我们解压(gzip压缩的等)网页内容
中文文档 API: http://docs.python-requests.org/zh_CN/latest/index.html
get请求
#导入requests包
import requests
#请求的网址
url = "https://www.baidu.com"
#url后面的参数?xxx
kw = {'wd':"我爱你"}
#请求头
headers = {"User-Agent":"xxx"}
#GET请求(url,请求头,url后面参数?xxx)
response = requests.get(url,headers=heasers,params=kw)
#打印网页源代码
print(response.content.decode())
post请求
#导入requests包
import requests
#请求的网址
url = "https://www.baidu.com"
#post参数
formdata = {"xxx":"xxx"}
#请求头
headers = {"User-Agent":"xxx"}
#POST请求(url,请求头,post请求参数)
response = requests.post(url,headers=headers,data=formdata)
#json格式
response = requests.post(url,headers=heasers,data=dumps(formdata))
#打印网页源代码
print(response.content.decode())
请求参数
url = "xxx" #请求网址
headers = {} #请求头
data = {} #post请求参数
params={"xx":"我爱你"}#url后面的参数?xxx
#代理
proxies={
"http":"http://12.34.56.79:9527",
"https":"https://12.34.56.79:9527"
}
响应参数
content #响应内容,返回字节流数据,用decode()解码
text #响应内容,返回Unicode格式的数据
url #查看url地址
encoding #查看响应头字符编码
status_code #查看状态码
request.headers #查看发过去的报头信息
json() #如果是json文件可以直接显示
.decode(‘gb18030’,’ignore’) #忽略非法字符
timeout请求超时
https://www.jianshu.com/p/5cf16cb5a362
爬虫处理Cookie和Session
带上cookie、session的好处:
- 能够请求到登录之后的页面
带上cookie、session的弊端:
- 一套cookie和session往往和一个用户对应
- 请求太快,请求次数太多,容易被服务器识别为爬虫
不需要cookie的时候尽量不去使用cookie
但是为了获取登录之后的页面,我们必须发送带有cookies的请求
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
使用方法:
- 实例化一个session对象
- 让session发送get或者post请求
session = requests.session()
response = session.get(url,headers)
模拟登陆的三种方式
- session
- 实例化session(session具有的方法和requests一样)
- session发送请求post请求,对方服务器设置的cookie会保存在session
- session请求登录后能够访问的页面
- cookie放在headers中
- headers = {"Cookie":"cookie字符串"}
- cookie转化为字典放在请求方法中
- requests.get(url,cookies={"name的值":"values的值"})
正则使用
import re
re.findall(r"a(.*?)b",body)
\t 制表符 \r 回车 \n 换行
#替换
.replace('\t','').replace('\r','').replace('\n','')
xpath使用
#获取文本
a/text() #获取a下的文本
a//text() #获取a下的所有标签的文本
//a[text()='下一页'] #选择文本为下一页三个字的a标签
#@符号
a/@href #获取url
//ul[@id="detail-list"] #获取标签属性
//div[contains(@class,"i")] #div标签包含i属性的
#在xpath最前面表示从当前html中任意位置开始选择
#li//a表示的是li下任何一个标签
//ul/li[1] #ul下第一个li标签
//ul/li[last()] #ul下最后一个li标签
//ul/li[last()-1] #ul下倒数第二个li标签
//ul/li[position()<3] #ul下前两个li标签
//div/* #div下所有的标签
//div[@*] #选取所有带属性的div标签
/li[not(@class="height_5")] #不包括某个属性节点
//tbody/tr[not(@class or @id)] #不包括多个属性节点
lxml库
安装lxml:pip install lxml
#导入lxml的etree库
from lxml import etree
response = requests.get(url,headers=headers)
html = response.content.decode()
#利用etree.HTML,将字符串转化为Element对象,Element具有xpath的方法
body = etree.HTML(html)
#在利用xpath取数据,先分组,在遍历取值
data = body.xpath('//div[@id="content-left"]/div')
for i in data:
#拿到图片连接,列表形式[www.xxxx.com]
touxiang = i.xpath('.//a/img/@src')
#拼接"http",并判断头像列表长度是不是大于0,如果不大于0就为空列表,输出None
touxiang = "http:"+touxiang[0].replace('?imageView2/1/w/90/h/90','') if len(touxiang)>0 else None
lxml使用注意点
- lxml能够修正HTML代码,但是可能会改错了
- 使用etree.tostring观察修改之后的html的样子,根据修改之后的html字符串写xpath
- lxml 能够接受bytes和str的字符串
- 提取页面数据的思路
- 先分组,渠道一个包含分组标签的列表
- 遍历,取其中每一组进行数据的提取,不会造成数据的对应错乱
数据提取之JSON
json.dumps和json.loads()使用方法
数据类型转换
dumps:字典转字符串
loads:字符串转字典
json.dump和json.load()使用方法
json.dump()和json.load()使用方法
用来对json文件的读和写
import requests
import json
#漂亮显示json
from pprint import pprint
#请求json地址
url = "https://www.baidu.com/rec?platform=wise&ms=1&lsAble=1&rset=rcmd&word=python&qid=9063735324500671597&rq=python&from=844b&baiduid=243F13D57A4DA7E648A71F9C61F2160A%3AFG%3D1&tn=&clientWidth=360&t=1541323156347&r=2799"
#请求头信息,如果不显示内容,把所有请求头加进来
headers = {"User-Agent":"xxx"}
#发起请求
response = requests.get(url,headers=headers)
html_str = response.content.decode()
#把字符转成字典,不然不显示中文
ret1 =json.loads(html_str)
#取数据
print(ret1["trans"][0]['dst'])
#漂亮的显示内容
print(pprint(ret1))
json文件读和写
#保存json文件,以utf-8的格式写进去
with open("a.json","w",encoding="utf-8") as f:
#json.dumps能够把python类型转化为json字符串
#ensure_ascii=False 显示中文,不然是ascii格式
#indent=4 换行显示,下一级比上一级多4个空格,跟漂亮显示一样
f.write(json.dumps(ret1,ensure_ascii=False,indent=4))
#使用json.load提取json文件的数据
with open("a.json",encoding="utf-8")as f:
ret4 = json.load(f)
print(ret4) #字典类型
爬取数据存到mysql数据库
#导入连接数据库的包
from pymysql import connect
#连接数据库
conn = connect(host='localhost',port=3306,db='biaoqing',user='root',passwd='root',charset='utf8')
#获取游标,实现数据库的(增删改查)
cc = self.conn.cursor()
#需要存的数据
aa = (touxing,mingzi,neirong,url)
#存数据库的命令
sql = 'insert into qsbk1(touxiang,mingzi,neirong,url) values ("%s","%s","%s","%s")'
#向数据库添加数据
cc.execute(sql%aa)
#提交数据
conn.commit()
#关闭游标
cc.close()
数据去重
def shuju(self):
rs = self.quchong(url)
#如果数据库有数据,不执行下面的语句
if rs == True:
continue
#数据去重
def quchong(self,url):
#数据查询语句
sql = "select count(1) from qsbk1 WHERE url='%s';" % url
#在数据库查询
self.cc.execute(sql)
#查询一条
f = self.cc.fetchone()[0]
#如果查询的数据大于0
if f > 0:
#有数据
return True
else:
#没有数据
return False