简介
-- 后面有很多习题,可以先做题目再来看文章
参考资料:https://docs.python.org/3/howto/index.html
正则表达式(Regular expressions REs或regexes或regex patterns)本质是小的且高度专业化的编程语言。它嵌入到 Python 中,调用使用re模块。需要指定一些规则来描述那些你希望匹配的字符串集合。这些字符串集合可能包含英语句子、e-mail地址、TeX 命令,或任何你想要的东东。然后可以提出问题,例如“字符串是否匹配该模式?”或“模式是否匹配字符串?”。 您还可以使用RE修改字符串或以各种方式拆分它。
正则表达式模式被编译成字节码,然后由 C 语言写的匹配引擎执行。对于高级的使用,你可能需要关注匹配引擎是如何执行给定RE,并通过一定的方式来编写RE,以便产生运行得更快的字节码。
正则表达式语言小而严格,不是所有的字符处理都可以使用正则表达式。还有一些任务,可以使用正则表达式来完成,但是表达式非常复杂。在这种情况下编写 Python 代码来处理会更好些;尽管 Python 代码比精巧的正则表达式执行起来会慢一些,但可能会更容易理解。
简单的模式
字符匹配
大多数字母和字符会匹配它们自身。举个例子,正则表达式test将完全匹配字符串test(你可以启用不区分大小写模式,该正则表达式可以匹配Test或TEST)。
这条规则有例外; 有些字符是特殊的元字符,不匹配自身。 相反,它们匹配一些与众不同的东西,或者通过重复它们或改变它们的含义来影响RE的其他部分。
这是元字符的完整列表
#!python
. ^ $ * + ? { } [ ] \ | ( )
方括号 [ ]指定用于存放你需要匹配的字符集合。例如 [abc] 会匹配字符 a,b 或 c;[a-c] 可以实现相同功能。后者使用范围来表示与前者相同的字符集合。如果你想只匹配小写字母,你的 RE 可能写成 [a-z]。
注意方括号元字符在中不会触发特殊功能例如 [akm'。
你还可以匹配方括号中未列出的所有其它字符,开头添加 ^即可,例如 [^5] 会匹配除了 '5' 之外的任何字符。
元字符转义:前面加上一个反斜杠,以消除它们的特殊功能:[,\ 。
反斜杠后边跟一些字符还可以表示特殊的意义,例如表示十进制数字,表示所有的字母或者表示非空白的字符集合。
让我们来举个例子:\w 匹配任何单词字符。如果正则表达式以字节的形式表示,这相当字符类 [a-zA-Z0-9_];如果正则表达式是一个字符串,\w 会匹配所有 Unicode 数据库(unicodedata 模块提供)中标记为字母的字符。你可以在编译正则表达式的时候,通过提供 re.ASCII 表示进一步限制 \w 的定义。
批注:re.ASCII 标志使得 \w 只能匹配 ASCII 字符,不要忘了,Python3 是 Unicode 的。
下边列举一些反斜杠加字符构成的特殊含义:
| 特殊字符 | 含义 |
|---|---|
| \number | 匹配相同编号的组。组从1开始编号。例如,(.+) \1匹配'the the'或'55 55',但不匹配'thethe'(注意组后面的空格)。此特殊序列只能用于匹配前99个组。如果数字的第一个数字是0,或者数字是3个八进制数字长,则不会将其解释为组匹配,而是解释为具有八进制值编号的字符。在方括号内,所有数字转义都被视为字符。默认支持Unicode,中文标点也会作为边界。可以启用re.ASCII。 |
| \d | 匹配任何十进制数字,相当于类[0-9] |
| \D | 与 \d 相反,匹配任何非十进制数字的字符,相当于 [^0-9] |
| \s | 匹配任何空白字符(包含空格、换行符、制表符等),相当于类 [\t\n\r\f\v] |
| \S | 与 \s 相反,匹配任何非空白字符,当相于类 [^\t\n\r\f\v] |
| \w | 匹配任何字符,设置了re.ASCII的情况下等同于[a-zA-Z0-9_] |
| \W | 与 \w 相反,设置了re.ASCII的情况下等同于[^a-zA-Z0-9_] |
| \b | 匹配单词的开始或结束 |
| \B | 与 \b 相反 |
| \A | 仅匹配字符串的开始。 |
| \Z | 仅匹配字符串末尾。 |
例如 [\s,.] 匹配任何空白字符(/s 的特殊含义),',' 或 ‘.’ 。
转义字符:
\a \b \f \n
\r \t \u \U
\v \x \\
'.'匹配除了换行符以外的任何字符。如果设置re.DOTALL,它将匹配包括换行在内的任何字符。
重复
'*' : 指定前一个字符匹配零次或者多次。
例如ca*t将匹配 ct(0 个 a),cat(1 个字符 a),caaat(3 个字符 a),等等。需要注意的是,由于受到 C 语言的 int 类型大小的内部限制,正则表达式引擎会限制字符 'a' 的重复个数不超过 20 亿个;不过,通常我们工作也用不到那么大的数据,你未必有这么大的内存。
默认的是贪婪的,当你重复匹配一个 RE 时,匹配引擎会尝试尽可能多的去匹配。直到RE不匹配或者到了结尾,匹配引擎就会回退一个字符,然后再继续尝试。
表达式 a[bcd]*b,首先需要匹配字符 'a',然后零个到多个 [bcd],最后以 'b' 结尾。那现在想象一下,这个 RE 匹配字符串 abcbd 会怎样?
| 步骤 | 匹配 | 说明 |
|---|---|---|
| 1 | a | 匹配 RE 的第一个字符 'a' |
| 2 | abcbd | 引擎在符合规则的情况下尽可能地匹配 [bcd]*,直到该字符串的结尾 |
| 3 | 失败 引擎尝试匹配 RE 最后一个字符 ‘b’,但当前位置已经是字符串的结尾,所以失败告终 | |
| 4 | abcb | 回退,所以 [bcd]* 匹配少一个字符 |
| 5 | 失败 | 再一次尝试匹配 RE 最后一个字符 'b',但字符串最后一个字符是 'd',所以失败告终 |
| 6 | abc | 再次回退,所以 [bcd]* 这次只匹配 'bc' |
| 7 | abcb | 再一次尝试匹配这符 'b',这一次字符串当前位置指向的字符正好是 'b',匹配成功。最终,RE 匹配的结果是 abcb 。 |
另一个实现重复的元字符是 +,用于指定前一个字符匹配一次或者多次。
要特别注意 * 和 + 的区别:* 匹配的是零次或者多次,所以被重复的内容可能压根儿不会出现;+ 至少需要出现一次。例如 ca+t 会匹配 cat 和 caaat,但不会匹配 ct 。
还有两个表示重复的元字符,一个是问号?: 字符匹配零次或者一次。
元字符 {m,n}(m 和 n 都是十进制数),必须匹配 m 次到 n 次之间。例如 a/{1,3}b 会匹配 a/b,a//b 和 a///b 。但不会匹配 ab(没有斜杠);也不会匹配 a////b(斜杠超过三个)。
你可以省略 m 或者 n,这样的话,引擎会用合理的值代替。 m默认为0;n 默认为 20 亿。
{0,}跟’*‘ 是一样的;{1,}跟‘+’是一样的;{0,1} 跟?是一样的。不过还是鼓励大家记住并使用 * 、+ 和 ?,因为这些字符更短并且更容易阅读。
习题
1, 下面那些不是python3正则表达式的元字符:
A $ B - C * D ? E /
参考答案:B E
2,python3正则表达式r'\bfoo\b'匹配下面哪些字符串
A 'foo' B 'foo.' C '(foo)' D 'bar foo baz' E 'foobar' F 'foo3'
参考答案:A B C D
3,python3正则表达式r'\bfoo\b'匹配下面哪些字符串
A 'foo,' B 'foo。' C '(foo!' D 'bar foo baz' E 'foobar' F 'foo3'
参考答案:A B C D
4,下面python3正则表达式元字符的描述哪些是错误的。
A. 默认\w不能匹配汉字
B. 默认\w能匹配汉字
C. 默认.能匹配换行符
D. 默认.不能匹配换行符
参考答案:A C
使用正则表达式
Python通过re模块提供正则表达式支持,并可将正则表达式编译成对象,用它们来进行匹配。
编译正则表达式
正则表达式编译为模式对象,该对象拥有各种方法,如查找模式匹配或者执行字符串替换。
>>> import re
>>> p = re.compile('ab*')
>>> p
re.compile('ab*')
re.compile()也接受可选的flags 参数,用于开启各种特殊功能和语法变化。
简单的例子:
>>> p = re.compile('ab*', re.IGNORECASE)
正则表达式作为字符串参数传给 re.compile() 。由于正则表达式并不是 Python语言的核心部分,因此没有为它提供特殊的语法支持,所以正则表达式只能以字符串的形式表示。
原始字符串
'\section' 要用'\\section'表示。不巧,Python 字符串也使用 '\' 表示字符 ''。原始字符串则方便得多:r"\section"即可。
匹配
模式对象的常用方法:
| 方法 | 功能 |
|---|---|
| match() | 判断正则表达式是否从开始处匹配一个字符串 |
| search() | 遍历字符串,找到正则表达式匹配的第一个位置 |
| findall() | 遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回 |
| finditer() | 遍历字符串,找到正则表达式匹配的所有位置,并以迭代器的形式返回 |
如果没有找到任何匹配的话,match() 和 search() 会返回 None;如果匹配成功,则会返回匹配对象(match object),包含所有匹配的信息:例如从哪儿开始,到哪儿结束,匹配的子字符串等等。
python自带了正则表达式调试工具redemo.py:
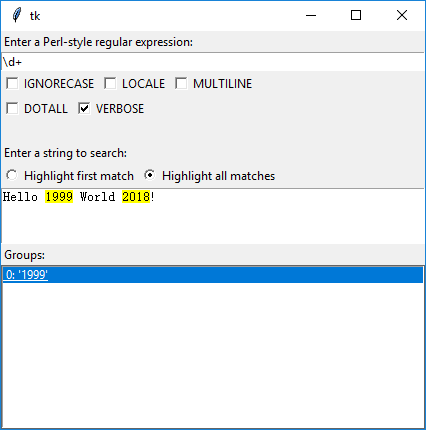
实例:
>>> import re
>>> p = re.compile('[a-z]+')
>>> p
re.compile('[a-z]+')
>>> p.match("")
>>> print(p.match(""))
None
>>> m = p.match('tempo')
>>> m
>>> m.group()
'tempo'
>>> m.start(), m.end()
(0, 5)
>>> m.span()
(0, 5)
匹配对象包含了很多方法和属性,以下几个是最重要的:
| 方法 | 功能 |
|---|---|
| group() | 返回匹配的字符串 |
| start() | 返回匹配的开始位置 |
| end() | 返回匹配的结束位置 |
| span() | 返回元组表示匹配位置(start, end) |
match的start总是0,search() 方法则不一定了:
>>> print(p.match('::: message'))
None
>>> m = p.search('::: message'); print(m)
>>> m.group()
'message'
>>> m.span()
(4, 11)
在实际应用中,最常用的方法是将匹配对象存放在局部变量中,并检查其返回值是否为 None 。
p = re.compile( ... )
m = p.match( 'string goes here' )
if m:
print('Match found: ', m.group())
else:
print('No match')
有两个方法可以返回所有的匹配结果,一个是 findall(),一个是 finditer() 。
findall() 返回的是一个列表:
>>> p = re.compile(r'\d+')
>>> p.findall('12 drummers drumming, 11 pipers piping, 10 lords a-leaping')
['12', '11', '10']
而 finditer() 则是将匹配对象作为迭代器返回:
>>> iterator = p.finditer('12 drummers drumming, 11 ... 10 ...')
>>> iterator
>>> for match in iterator:
... print(match.span())
...
(0, 2)
(22, 24)
(29, 31)
模块级函数
re 模块同时还提供了一些全局函数,例如 match(),search(),findall(),sub() 等。这些函数跟模式对象同名方法一样,只是增加了为正则表达式字符串的第一个参数。
>>> print(re.match(r'From\s+', 'Fromage amk'))
None
>>> re.match(r'From\s+', 'From amk Thu May 14 19:12:10 1998')
这些函数帮你自动创建模式对象,并调用相关的函数。它们还将编译好的模式对象存放在缓存中,以便将来可以快速地直接调用。
在循环中大量的使用正则表达式,预编译的话可以节省一些函数调用,用模式的方法更好。但如果是循环外部,因为有内部缓存机制,两者效率相差无几。
编译标识
编译标识可修改正则表达式的工作方式。在 re 模块下,编译标识均有完整名和简写,例如 IGNORECASE 简写是 I。
| 标志 | 含义 |
|---|---|
| ASCII,A | 使得转义符号 \w,\b,\s 和 \d 只能匹配 ASCII 字符 |
| DOTALL,S | 使得 . 匹配任何符号,包括换行符 |
| IGNORECASE,I | 不区分大小写 |
| LOCALE,L | 支持当前语言(区域)设置 |
| MULTILNE,M | 多行匹配,影响 ^ 和 $ |
| VERBOSE,X(for'extended') | 启用详细的正则表达式, 更简洁且更容易理解。 |
下面我们来详细讲解一下它们的含义:
- I
IGNORECASE
不区分大小写。举个例子,正则表达式[a-z] 或[A-Z]会匹配对应的小写字母会匹配52个ASCII字母。还有4个非ASCII字母:'İ'(U + 0130,拉丁大写字母I上面带点),'ı'(U + 0131,拉丁文小写字母无点i),'s'(U + 017F,拉丁文小 字母长s)和'K'(U + 212A,开尔文标志)。 Spam 将匹配'Spam','spam','spAM'或'ſpam'(后者仅在Unicode模式下匹配)。 此小写不考虑当前区域设置; 如果您还设置了LOCALE标志,它也会。
- L
LOCALE
使得 \w,\W,\b 和 \B和大小写依赖当前的语言(区域)环境,而不是 Unicode 数据库。
区域设置是 C 语言的功能,主要作用是消除不同语言之间的差异。例如你正在处理的是法文文本,你想使用 \w+ 来匹配单词,但是 \w 只是匹配 [A-Za-z] 中的单词,并不会匹配那些法文特殊符号。python3已经推荐使用Unicode,不建议使用LOCALE。
- M
MULTILNE
通常 ^ 只匹配字符串的开头,而 $ 匹配字符串的结尾。该标识设置时,^ 不仅匹配字符串的开头,还匹配行首;$ 不仅匹配字符的结尾,还匹配行尾。
- S
DOTALL
. 可以匹配任何字符,包括换行符。如果不使用这个标志,. 将匹配除换行的所有字符。
- A
ASCII
使得 \w,\W,\b,\B,\s 和 \S 只匹配 ASCII 字符,而不是全Unicode匹配。这个标识仅对Unicode模式有意义,并忽略字节模式。
- X
VERBOSE
这个标识使你的正则表达式可以写得更可读灵活,空格会被忽略(除了出现在字符类中和使用反斜杠转义的空格);同时允许你在正则表达式字符串使用注释,# 符号后边的内容是注释(除了出现在字符类中和使用反斜杠转义的 #)。
下边是使用 re.VERBOSE 的例子,:
charref = re.compile(r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
""", re.VERBOSE)
# 没有注释
charref = re.compile("&#(0[0-7]+"
"|[0-9]+"
"|x[0-9a-fA-F]+);")
参考资料
- 讨论qq群144081101 591302926 567351477 钉钉免费群21745728
- 本文最新版本地址
- 本文涉及的python测试开发库 谢谢点赞!
- 本文相关海量书籍下载
- 本文源码地址
习题
1,下面关于python3 正则模式的说哪些是错误的?
A. match() 可以返回多个匹配
B. search() 必须从开头开始匹配
C. findall() 以迭代器的形式返回
D. finditer() 以列表的形式返回
答案:ABCD
2,python3 正则表达式re.compile('spam', re.IGNORECASE)匹配哪些字符串?
A.'Spam' B. 'spam' C. 'spAM' D. 'ſpam' E.'pam'
答案:ABCD
更多关于模式
更多元字符
- I
或操作符,对两个正则表达式进行操作。如果 A 和 B 是正则表达式,A | B 会匹配 A 或 B 中出现的任何字符。为了能够更加合理的工作,| 的优先级非常低。例如 Crow|Servo匹配'Crow'或'Servo',,而不是匹配'Cro'、 'w' 、'S'、'ervo'.。
同样,我们使用 | 来匹配 '|' 字符本身;或者包含在一个字符类中,像这样 [|] 。
- ^
匹配字符串开始。在 MULTILNE 中,每当遇到换行符就会立刻进行匹配。如果你只希望匹配位于字符串开头的单词 From,那么你的正则表达式可以写为 ^From
>>> print(re.search('^From', 'From Here to Eternity'))
>>> print(re.search('^From', 'Reciting From Memory'))
None
- $
匹配字符串的结束和行尾。
>>> print(re.search('}$', '{block}'))
>>> print(re.search('}$', '{block} '))
None
>>> print(re.search('}$', '{block}\n'))
- A
匹配字符串开始,如果没有设置 MULTILINE 标志的时候,\A 和 ^ 的功能是一样的;但如果设置了 MULTILNE 标志, ^ 会对字符串的每一行都进行匹配。
- Z
匹配字符串的结束。
- b
单词边界,这是只匹配单词的开始和结尾的零宽断言。单词定义为字母数字的序列,所以单词的结束指的是空格或者非字母数字的字符。
>>> p = re.compile(r'\bclass\b')
>>> print(p.search('no class at all'))
>>> print(p.search('the declassified algorithm'))
None
>>> print(p.search('one subclass is'))
None
在使用这些特殊的序列的时候,有两点是需要注意的:第一是Python 的字符串跟正则表达式在有些字符上是有冲突的。比如说在 Python 中,\b 表示的是退格符,ASCII 码值是 8。
下边例子中,我们故意不写表示原始字符串的 'r',结果确实大相庭径:
>>> p = re.compile('\bclass\b')
>>> print(p.search('no class at all'))
None
>>> print(p.search('\b' + 'class' + '\b'))
第二点是在字符类中不能使用这个断言。在字符类中,\b 只是用来表示退格符。
- \B
与 \b 的含义相反,\B 表示非单词边界的位置。
分组
仅仅知道正则表达式是否匹配是不够的,正则表达式通常使用分组的方式分别对不同内容进行匹配。
下例子将 RFC-822 头用 “:” 号分成名字和值:
From: [email protected]
User-Agent: Thunderbird 1.5.0.9 (X11/20061227)
MIME-Version: 1.0
To: [email protected]
先用正则表达式匹配整个RFC-822头,使用一个组来匹配头的名字,另一个组匹配名字对应的值。
正则表达式使用元字符'(', ')' 来划分组。'(', ')' 元字符跟数学表达式中的小括号含义差不多;它们将包含在内部的表达式组合在一起,所以你可以对组的内容使用重复操作的元字符,例如 *,+,? 或者 {m,n} 。
>>> p = re.compile('(ab)*')
>>> print(p.match('ababababab').span())
(0, 10)
用'(',')'表示的组也捕获它们匹配的文本的起始和结束索引; 这可以通过将参数传递给ggroup(),start(),end() 和 span() 来检索。 组从0开始编号。组0始终存在; 它是整个RE,因此匹配对象方法都将组0作为其默认参数。
>>> p = re.compile('(a)b')
>>> m = p.match('ab')
>>> m.group()
'ab'
>>> m.group(0)
'ab'
子组从左到右进行编号,子组也允许嵌套,我们可以通过从左往右来统计左括号 ( 来确定子组的序号。
>>> p = re.compile('(a(b)c)d')
>>> m = p.match('abcd')
>>> m.group(0)
'abcd'
>>> m.group(1)
'abc'
>>> m.group(2)
'b'
group() 方法可传入多个子组的序号:
>>> m.group(2,1,2)
('b', 'abc', 'b')
groups() 方法一次性返回所有的子组匹配的字符串:
>>> m.groups()
('abc', 'b')
反引用可以在后面的位置使用先前匹配过的内容,用法是反斜杠加上数字。例如 \1 表示引用前边成功匹配的序号为 1 的子组。
>>> p = re.compile(r'\b(\w+)\s+\1\b')
>>> p.search('Paris in the the spring').group()
'the the'
习题
1, python3正则表达式compile('Crow|Servo')匹配哪些内容:
A 'Crow' B 'foo。' C Servw' D 'Cro' E 'Serv' F 'Servo'
参考答案:A F
2, python3正则表达式要匹配'|',可以采用如下哪些方法:
A '||' B '|' C '[|]' D '$|'
参考答案:B C
3,关于python3正则表达式,下面哪些说法是正确的
A re.findall(r'^From', 'From Here to Eternity\nFrom', re.MULTILINE) 返回长度为2的列表
B re.findall(r'^From', 'From Here to Eternity\nFrom') 返回长度为2的列表
C re.findall(r'^From', ' From Here to Eternity\nFrom', re.MULTILINE) 返回长度为2的列表
D re.findall(r'\bFrom', ' From Here to Eternity\nFrom', re.MULTILINE) 返回长度为2的列表
参考答案:A D
4,关于python3正则表达式,下面哪些说法是正确的
A re.search(r'\bclass\b', 'no class at all')能成功匹配
B re.search('\bclass\b', 'no class at all')能成功匹配
C re.search(r'\bclass\b', 'no class at all')不能能成功匹配
D re.search('\bclass\b', 'no class at all')不能成功匹配
参考答案:A D
待整理: notepad++ 正则 http://docs.notepad-plus-plus.org/index.php/Regular_Expressions