es筛选数据_2020招行fintech精英训练营数据赛道

作为一个CV转数分的菜鸡,第一次报名这种类似于kaggle的比赛,我是抱着一种学习的心态参加的。好在平时机器学习也有一定的积累,做项目的过程中建模的流程也都清晰,参赛过程中并没有很懵的感觉。最后的排名并没有很好,但比赛之后跟大佬们交流学到了很多课本和教程里学不到的东西,这些经验算是这次比赛最重要的收获吧,希望可以拿到招行offer~
题目描述
提供了三个Excel表,目的是预测用户是否会违约(flag字段是预测目标),二分类问题,评估指标为AUC。
用户标签表(包括基本的人口统计学信息,经济情况)。
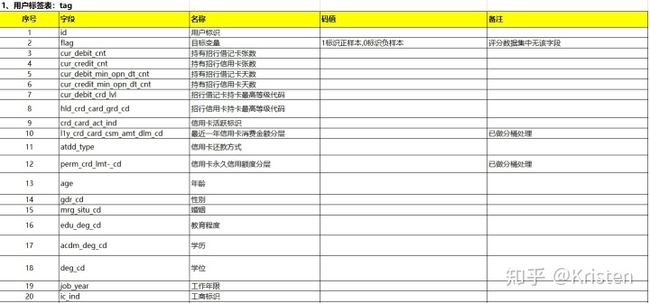
交易行为表。

APP行为表。

原始数据分析:用户标签表(以下简称tag)包含的字段最多,由"id"字段唯一的标识记录,而交易行为表(以下简称trd)和APP行为表(以下简称beh)中,同一个"id"可以存在多条记录,这两个表的与用户标签表的"id"相对应,且只有部分用户有相关数据。
数据基本情况
使用pandas_profiling观察原始数据中每个变量的详情。
import pandas_profiling
pfr = pandas_profiling.ProfileReport(data)
pfr.to_file('original.html')


数据预处理与特征工程
对原始数据进行分析,主要有三类变量,数值型,有序型分类变量和无序型分类变量。
缺失值的处理:
- 数值型变量:缺失值超过50%,丢弃列,否则使用中位数填充。
- 有序型分类变量:使用sklearn的LabelEncoder()编码。
- 无序型分类变量:缺失值不做处理,直接独热编码。
特征生成
使用featuretools这个包把三个表连接起来,基于“ 深度特征合成 ”的方法来自动生成特征。生成完之后大概500多维。
参考资料:https://zhuanlan.zhihu.com/p/43630912
https://www.cnblogs.com/wkang/p/10380500.html
#首先,需要创建一个存放所有数据表的空实体集对象:
es=ft.EntitySet(id='id')
#接着添加实体,每个实体都必须有一个索引,索引中的每个值可以唯一的标识记录(类似于主键的概念)。
es.entity_from_dataframe(entity_id='tag',
dataframe=tag_combi,
index='id')
es.entity_from_dataframe(entity_id='trd',
dataframe=trd_combi,
make_index=True,#对于没有唯一索引的表:需要传入参数make_index = True并指定索引的名称
index='trd_id',
time_index='trx_tm')
es.entity_from_dataframe(entity_id='beh',
dataframe=beh_combi,
make_index=True,
index='beh_id',
#使用参数variable_types来重新定义数据类型
variable_types={'page_tm': ft.variable_types.Datetime},
time_index='page_tm')
#创建表之间关系并将其添加到实体集中
r_tag_trd = ft.Relationship(es['tag']['id'], es['trd']['id'])
es = es.add_relationship(r_tag_trd)
r_tag_beh = ft.Relationship(es['tag']['id'], es['beh']['id'])
es = es.add_relationship(r_tag_beh)
# 最后,使用dfs函数自动为我们构建特征。
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='tag',
max_depth=2,
verbose=1,
n_jobs=-1)
feature_matrix = feature_matrix.reindex(index=tag_combi['id'])特征处理
生成后的特征保存成Excel,并且使用pandas_profiling观察变量情况。生成的特征中有一些存在大量缺失值(由于并不是每个客户都有trd和beh信息),所以删除了缺失值>50%的列,其余缺失值用0填充。
最后,使用z-score标准化数据。
ss = StandardScaler()
features[lis] = ss.fit_transform(features[lis])准备好输入模型的数据。
x = features.iloc[:tag.shape[0], 1:].values
y = flag.values.reshape(-1)
test = features.iloc[tag.shape[0]:, :]
x_test=test.iloc[:,1:].values # testing dataset模型算法
我试过单模型和模型融合,模型融合并没有很大提升。比赛结束后大家在群里讨论,发现这个数据集奇怪的点就在于,单模型也可以达到很好的效果,甚至比模型融合好。(也就是说最重要的还是特征工程)。
单模型我用的是XGBoost。
model = xgb.XGBClassifier(
learning_rate=0.03,
n_estimators=1500,
max_depth=3,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective='binary:logistic',
reg_alpha=1,
nthread=4,
scale_pos_weight=1)模型融合(stacking)的代码也贴一下。由于之前用GridSearchCV做过超参数搜索,所以这里stacking只用了交叉验证结果比较好的模型。
def stacking():
clf1 = KNeighborsClassifier(
algorithm='auto', n_neighbors=45, weights='uniform'
)
clf2 = RandomForestClassifier(
max_depth=20, max_features='auto', n_estimators=400,random_state=100
)
clf3 = GaussianNB()
clf4 = xgb.XGBClassifier(
learning_rate=0.03,
n_estimators=1500,
max_depth=3,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective='binary:logistic',
reg_alpha=1,
nthread=4,
scale_pos_weight=1
)
clf5 = LogisticRegression(
C=0.0001, class_weight='balanced', max_iter=1000, solver='sag'
)
clf6 = DecisionTreeClassifier(max_depth=150)
clf7 = AdaBoostClassifier(n_estimators=150)
clf8 = GradientBoostingClassifier(learning_rate=0.1)
lr = LogisticRegression(C=0.01)
estimators = [('KNN', clf1), ('Random Forest', clf2), ('XGBoost', clf4), ('LR', clf5),
('Adaboost', clf7), ('GradientBoost', clf8)]
sclf = StackingClassifier(estimators=estimators, final_estimator=lr)
return sclf线下结果评估
使用5折交叉验证进行结果评估(比赛的时候用的kfold,赛后讨论发现用StratifiedKFold会比较好,因为正负样本不均衡,正:负≈1: 3.5)。使用sklearn中的SelectFromModel进行特征筛选,筛选后特征约200维。特征选择的方法参考https://www.zhihu.com/question/28641663/answer/41653367。这里我用了3个模型(GradientBoostingClassifier(),RandomForestClassifier(),XGBClassifier())筛选特征,取特征交集作为最终输入。
kfold = KFold(n_splits=5, shuffle=True, random_state=100)
pred = []
for train_index, val_index in kfold.split(x, y):
x_train, x_val = x[train_index], x[val_index]
y_train, y_val = y[train_index], y[val_index]
def select(model):
# 使用模型进行特征筛选
s=SelectFromModel(model,threshold='median')
s_x_train=s.fit_transform(x_train,y_train)
s_x_val=s.transform(x_val)
s_x_test=s.transform(x_test)
lis=list(s.get_support())
return s_x_train,s_x_val,s_x_test,lis
s1_x_train, s1_x_val, s1_x_test ,slis1=select(GradientBoostingClassifier())
s2_x_train, s2_x_val, s2_x_test ,slis2= select(RandomForestClassifier())
s3_x_train, s3_x_val, s3_x_test ,slis3= select(xgb.XGBClassifier())
select_x_train=[]
select_x_val = []
select_x_test = []
for i in range(len(slis1)):
if slis1[i] and slis2[i] and slis3[i]:
select_x_train.append(s1_x_train[:,i:i+1])
select_x_val.append(s1_x_val[:,i:i+1])
select_x_test.append(s1_x_test[:,i:i+1])
selected = pd.DataFrame(select_x_train)
writer = pd.ExcelWriter('selected.xlsx') # 写入Excel文件
features.to_excel(writer, 'page_1', float_format='%.5f') # ‘page_1’是写入excel的sheet名
writer.save()
writer.close()
pfr = pandas_profiling.ProfileReport(selected)
pfr.to_file('selected.html')
model.fit(select_x_train, y_train)
y_pred = model.predict_proba(select_x_val)
auc = roc_auc_score(pd.get_dummies(y_val), y_pred)
print("Auc: %.2f%%" % (auc * 100.0))
pred.append(print_ensemble(model, select_x_test))
data = pd.DataFrame(pred)
writer = pd.ExcelWriter('pred.xlsx') # 写入Excel文件
data.to_excel(writer, 'page_1', float_format='%.5f') # ‘page_1’是写入excel的sheet名
writer.save()
writer.close()
res = np.mean(pred, axis=0)
results=pd.DataFrame(test['id'])
results['p']=res
results.to_csv('results_b.txt',sep='t',index=False,header=False,encoding='utf8')
for i, id in enumerate(test['id'].values):
print(id, res[i])最终结果:
线上a榜:0.7366。b榜:0.7697。
一点心得
比赛结束后跟群里的前排大佬讨论了一下,总结了一些经验。
- 特征工程的重要性。这句话相信大家一定不陌生,“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,这次比赛让我对特征的重要性有了更深刻的体会。在做特征工程的时候,重点关注业务场景。结合业务分析可以生成更有意义的特征。之前我认为我不是学金融的,对业务分析分析不出什么东西,但是看了大佬的讨论之后发现,有些强特征是不难挖掘出来的,关键是动脑子多思考,基本的知识储备够用了,当然这只是比赛,实际场景中有专业知识储备会更好。
- 多多尝试。深入的业务分析对于外行人来说有一定的难度,有时候生成的特征也拿不准是否有用,那就先根据自己的判断尽可能的多生成特征。包括预处理方法,特征选择和模型选择等,都需要多尝试,记录实验过程,及时发现问题并改进。
- 前辈的分享非常重要!我在比赛的时候居然都没想着去找一下往年的比赛方案分享。赛后才在github上看到有人分享,这两天从前辈的方案中又学习到了不少特征生成的方法,看完会惊呼“原来还可以这样啊!”。可惜自己太菜了,眼界有限,参加比赛的时候特征生成和特征选择都用的自动工具,真的懒:)
最后贴一下前辈的分享帖,看完记得点个赞呀!!!
uncleban/2019_cmb_fintechgithub.com
