一、Lru算法
Lru算法:最近最少使用算法;
算法的核心关键类是LinkedHashMap。
基本算法:将key-value键值对按照访问顺序进行排列放置,当存入的数据超过最大内存分配时,移除最久访问的数据;
所以要搞清楚LruCache的原理,首先需要研究LinkedHashMap这个类;
LinkedHashMap继承自HashMap,自然也就继承了HashMap中的众多方法,所以在研究LinkedHashMap之前,有必要去研究下LinkedHashMap的父类HashMap;
二、Map接口
Map接口,key-value集合的抽象,反映了单个的key映射着单个的value这样一种数据结构;
它的核心行为是
存入key-value,对应着put(key,value)方法和根据key来取出value,对应着get(key);
然后为了功能上的完善,还提供了其他的接口:
//清除map中的所有数据
clear();
//是否包含某个key
containsKey(key);
//是否包含某个value
containsValue(value);
//map是否为空
isEmpty()
//根据某个key来移除key-values
remove(key)
三、HashMap——Map的实现;
3.1. HashMapEntry
它是HashMap中的一个内部类,它是HashMap存储的数据单元,HashMap中的存储数组的存储单位就是HashMapEntry
final K key;
V value;
final int hash;
HashMapEntry next;
主要有四个值,key,values,hash和next,这个next是为了解决hash冲突而设置的,当存在hash冲突时,next会链式地指向下一个HashMapEntry对象;这个具有相同table index的entry可以链式存储到table中的同一个位置;
废话不多说了,直接进入到HashMap的核心方法get(key)和put(key,value)方法;
3.2. put(key,value)方法
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
//根据key来计算hash值,至于为什么是Collections.secondaryHash(key)?
//这样做只是为了使得hash分布更均匀,避免hash冲突;
//具体来参考大神的解释:http://burtleburtle.net/bob/hash/integer.html
int hash = Collections.secondaryHash(key);
//这里就是要存储数据的数组,基本元素是HashMapEntry
HashMapEntry[] tab = table;
//根据hash值和table的长度来计算索引index值,注意一点,计算的index值不能超过数组的索引范围
int index = hash & (tab.length - 1);
//这一步,需要自己品味和分析,首先抛出一个问题:如果两个不同的key,计算得到的index恰巧相同,这种情况下怎么办呢?
//上面的问题,其实就是发生了hash冲突如何解决的问题,HashMap采用的方法是,当index值相同时,采用链式的存储方式来存储不同的key-value值
//这么说不明白?不要着急,看下面代码,且听我来细细道来(解释废话比较多,放在代码后边,文字里叙述,免得注释过多):
for (HashMapEntry e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}
首先处理key为null的情况,根据成员属性entryForNullKey是否为null,如果为null,则调用addNewEntryForNullKey(value)方法来对其进行赋值:
void addNewEntryForNullKey(V value) {
entryForNullKey = new HashMapEntry(null, value, 0, null);
}
这种情况不做过多的论述;
接下来,是重点哈哈哈哈~~~好像重点有点画多了哈哈哈,不过下面是重点中的重点:
HashMap是通过基础的数据类型数组HashMapEntry[] table来存入key-value键值对的;
what??没有搞错把?搞了半天,HashMap是用数组来实现数据存储的??数组的使用我想大家都没有问题把》》》
当我们往HashMap中存入键值对的时候,会根据key来计算出一个int类型的hash值,然后再将这个hash值转换成table长度范围内的索引index,再将value赋值给table[index],经过这样一个过程,就实现了key-value到数组存储的转化;
两个不同的key,计算得到index值一样时,也就是存在hash冲突时,HashMap是如何处理的?
第一次得到index值时,此时的table[index]为null,所以直接存入addNewEntry(key, value, hash, index);
第二次得到index值时,此时的table[index]不为null,进入for循环,判断是不是相同的key,如果是,则存入newValue,返回oldValue;
如果不是相同的key,for循环中if条件为false,走addNewEntry(key, value, hash, index);
//我们仔细回顾下,在执行这个方法之前,table[index]已经存入了第一次得到index时的hashMapEntryOne,
//那么new HashMapEntry(key, value, hash, table[index]),生成新的对象hashMapEntryTwo,它的内部成员属性next指向了hashMapEntryOne;
//结果就是table[index]存入了hashMapEntryTwo的引用,然后hashMapEntryTwo的next又指向了hashMapEntryOne;
//这样存在hash冲突的两个key-values键值对,就以链式数据结构,存储到了table[index]下;
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry(key, value, hash, table[index]);
}
HashMapEntry(K key, V value, int hash, HashMapEntry next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
3.3. get(key)方法
public V get(Object key) {
//首先处理key为null的情况,根据成员属性entryForNullKey的值来返回null或者entryForNullKey的value;
if (key == null) {
HashMapEntry e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry[] tab = table;
for (HashMapEntry e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
当根据key来获取对应的value时,其实是上述过程的逆过程:
首先根据key的值来按照特定的算法计算出对应的hash值,然后将hash值转换成数组table的索引index,然后取出table[index]中存储的值hashMapEntry,依次去遍历hashMapEntry中的值(链式存储,当存在hash冲突时,可能会有多个值,依次从next中取出值),在if条件判断中比较hashMapEntry的key是否与参数key相同,相同 的话,说明当前的hashMapEntry的value是我们要取的值;
否则的话,返回null;
整个HashMap的核心就是将key映射到内部存储结构table的index的方法+HashMapEntry链式数据结构来解决hash冲突:
四、几个关键问题
4.1. 如何避免和解决hash冲突的
HashMap解决hash冲突的方法:
hash复用,同一个hash值,链式地加入多个value;
即如果不同的key,计算出的table index相同的话,那么会将这些值存入table[index]中,而table[index]的值HashMapEntry为链式存储结构,可以链式的的放入多个值;
4.2.如何解决HashMap容量不足的问题
前面解决了hash冲突的问题,那么现在如何解决容量不足的问题了。
考虑这样的情况,如果用户大量地调用put方法,在这种情况下,如果容量不变,那么势必会出现大量的冲突,调用get方法时,可能需要很长长度的遍历才能得到答案,性能损失严重,因此,我们可以发现put(key,value)源码中有这样一种方法doubleCapacity(),这个方法在HashMap存储容量到达阈值时调用,使得HashMap的存储容量增加一倍;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
这个方法的具体原理,有兴趣的可以去看下源码,这里我只想说一下,扩容之后,旧数组和新数组的index之前的关系:
int highBit = e.hash & oldCapacity;
HashMapEntry broken = null;
newTable[j | highBit] = e;
oldCapacity假设为16(00010000), int highBit = e.hash & oldCapacity 能够得到高位的值,因为低位全为0,经过与操作过后,低位一定是0。J 在这里是index,J 与 高位的值进行‘|’操作过后,就能得到在扩容后面的新的index值。
设想一下,理论上我们得到的新的值应该是 newValue = hash & (newCapacity - 1) ,与 oldValue = hash & (oldCapacity - 1) 的区别仅在于高位上。 因此我们用 J | highBit 就可以得到新的index值。
4.3.如何解决迭代问题的
4.4.HashMap 是如何实现序列化接口的
这两个问题,可以参考下面这篇文章:
http://www.woaitqs.cc/program/2015/04/14/read-source-code-about-hashmap
五、LinkedHashMap——有序的Map接口实现;
5.1
有序指的是元素可以按照插入顺序或者访问顺序排列;
既然有两种顺序选择,就需要一个标志位来确定应用中选择哪种排序方式;
LinkedHashMap成员属性boolean accessOrder就是这样一个标志位:
如果为true的话,LinkedHashMap应用访问顺序排序;
如果为false的话,LinkedHashMap应用插入顺序排序;
5.2.
LinkedHashMap内部包含一个双向循环链表,元素排序就是根据这个双向循环链表来进行的;
其数据结构示意图如下:

双向循环链表示意图:

双向循环链表头部存储的是最久访问或者最先插入的节点;
尾部存放的是最近访问或者最近插入的节点;
迭代器的遍历方向是从链表的头部开始到链表的尾部结束;
链表的头部(也可以叫尾部,叫法不一样,但不影响它的本质)有一个空的节点header;
该节点不存放key-value键值,是LinkedHashMap类的成员属性,是双向循环链表的入口;
5.3.LinkedHashMap中的双向链表的操作
示意图

说了这么多,都是描述性的语言,看了似乎很明白很直白,但是还是要提醒一点哦,真理还是在源码中,哈哈哈~
六、LinkedHashMap源码解析
有了HashMap的源码分析,LinkedHashMap的源码应该不难理解;
在get(key)方法中会根据访问的key来,调用makeTail(e)来调整hashMapEntry[] table中的数据顺序;
6.1.
LinkedHashMap是一个双向循环链表,它的每一个数据结点都有两个指针,分别指向直接前驱和直接后继,这一个我们可以从它的内部类LinkedEntry中看出,其定义如下:
static class LinkedEntry extends HashMapEntry {
LinkedEntry nxt;
LinkedEntry prv;
/** Create the header entry */
LinkedEntry() {
super(null, null, 0, null);
nxt = prv = this;
}
/** Create a normal entry */
LinkedEntry(K key, V value, int hash, HashMapEntry next,
LinkedEntry nxt, LinkedEntry prv) {
super(key, value, hash, next);
this.nxt = nxt;
this.prv = prv;
}
}
加入一个新的节点时,执行方法,新插入的节点放置在尾部:
@Override void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry header = this.header;
// Remove eldest entry if instructed to do so.
LinkedEntry eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
// Create new entry, link it on to list, and put it into table
LinkedEntry oldTail = header.prv;
LinkedEntry newTail = new LinkedEntry(
key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;
}
当accessOrder为true时,访问一个节点会执行方法makeTail(),将这个节点移动到尾部;
6.2. makeTail(e)方法
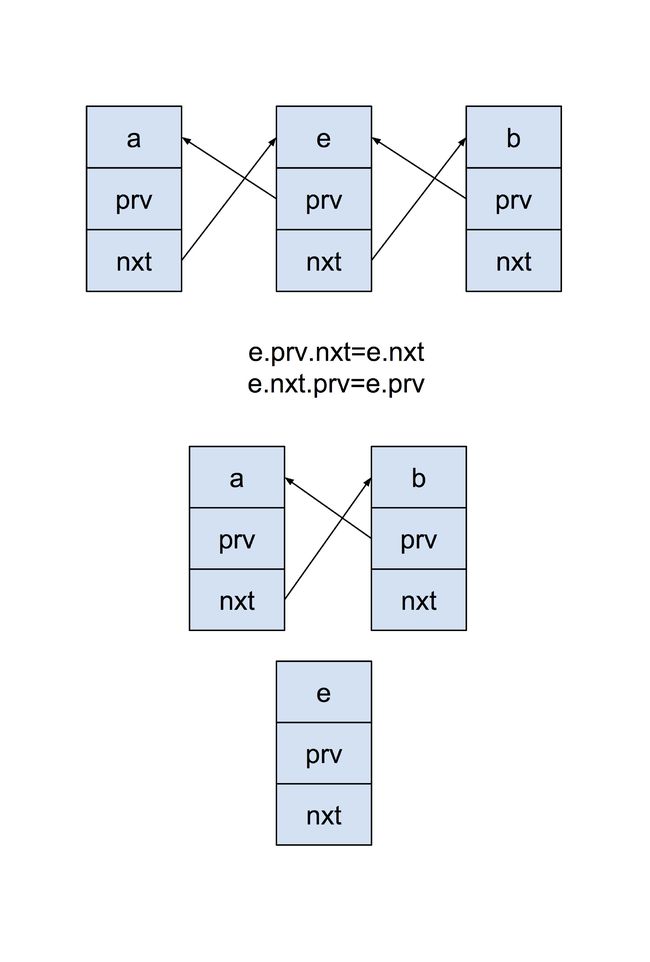
private void makeTail(LinkedEntry e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
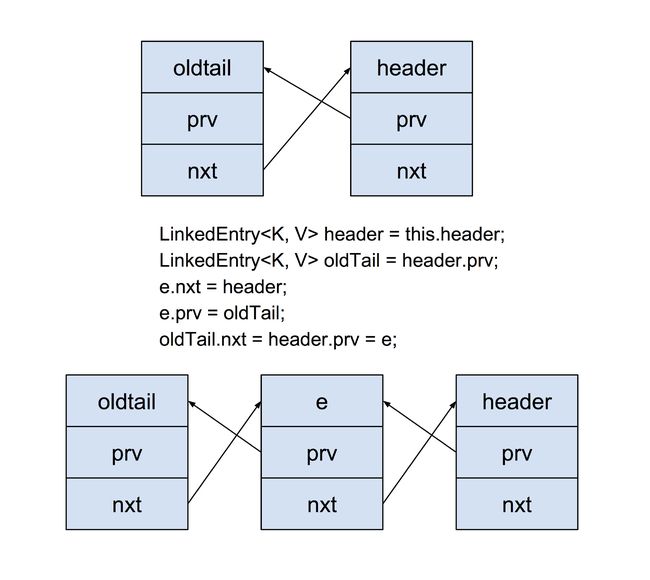
// Relink e as tail
LinkedEntry header = this.header;
LinkedEntry oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}
理解makeTail()方法,直接看下面两个过程示意图:
unlink过程
relink过程
references:
http://www.cnblogs.com/chenpi/p/5294077.html
https://github.com/LittleFriendsGroup/AndroidSdkSourceAnalysis/blob/master/article/LruCache%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90.md
http://www.woaitqs.cc/program/2015/04/14/read-source-code-about-hashmap