搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了
↑ 点击蓝字 关注极市平台
作者丨科技猛兽
编辑丨极市平台
极市导读
本文对Vision Transformer的原理和代码进行了非常全面详细的解读,一切从Self-attention开始、Transformer的实现和代码以及Transformer+Detection:引入视觉领域的首创DETR。>>加入极市CV技术交流群,走在计算机视觉的最前沿
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用RNN顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。本文将对Vision Transformer的原理和代码进行非常全面的解读。考虑到每篇文章字数的限制,每一篇文章将按照目录的编排包含三个小节,而且这个系列会随着Vision Transformer的发展而长期更新。
目录
(每篇文章对应一个Section,目录持续更新。)
Section 1
1 一切从Self-attention开始
1.1 处理Sequence数据的模型
1.2 Self-attention
1.3 Multi-head Self-attention
1.4 Positional Encoding2 Transformer的实现和代码解读 (NIPS2017)
(来自Google Research, Brain Team)
2.1 Transformer原理分析
2.2 Transformer代码解读3 Transformer+Detection:引入视觉领域的首创DETR (ECCV2020)
(来自Facebook AI)
3.1 DETR原理分析
3.2 DETR代码解读
Section 2
4 Transformer+Detection:Deformable DETR:可变形的Transformer (ICLR2021)
(来自商汤代季峰老师组)
4.1 Deformable DETR原理分析
4.2 Deformable DETR代码解读5 Transformer+Classification:用于分类任务的Transformer (ICLR2021)
(来自Google Research, Brain Team)
5.1 ViT原理分析
5.2 ViT代码解读6 Transformer+Image Processing:IPT:用于底层视觉任务的Transformer
(来自北京华为诺亚方舟实验室)
6.1 IPT原理分析
Section 3
7 Transformer+Segmentation:SETR:基于Transformer 的语义分割
(来自复旦大学,腾讯优图等)
7.1 SETR原理分析8 Transformer+GAN:VQGAN:实现高分辨率的图像生成
(来自德国海德堡大学)
8.1 VQGAN原理分析
8.2 VQGAN代码解读9 Transformer+Distillation:DeiT:高效图像Transformer
(来自Facebook AI)
9.1 DeiT原理分析
1 一切从Self-attention开始
1.1 处理Sequence数据的模型:
Transformer是一个Sequence to Sequence model,特别之处在于它大量用到了self-attention。
要处理一个Sequence,最常想到的就是使用RNN,它的输入是一串vector sequence,输出是另一串vector sequence,如下图1左所示。
如果假设是一个single directional的RNN,那当输出 时,默认 都已经看过了。如果假设是一个bi-directional的RNN,那当输出 任意 时,默认 都已经看过了。RNN非常擅长于处理input是一个sequence的状况。
那RNN有什么样的问题呢?它的问题就在于:RNN很不容易并行化 (hard to parallel)。
为什么说RNN很不容易并行化呢?假设在single directional的RNN的情形下,你今天要算出 ,就必须要先看 再看 再看 再看 ,所以这个过程很难平行处理。
所以今天就有人提出把CNN拿来取代RNN,如下图1右所示。其中,橘色的三角形表示一个filter,每次扫过3个向量 ,扫过一轮以后,就输出了一排结果,使用橘色的小圆点表示。
这是第一个橘色的filter的过程,还有其他的filter,比如图2中的黄色的filter,它经历着与橘色的filter相似的过程,又输出一排结果,使用黄色的小圆点表示。
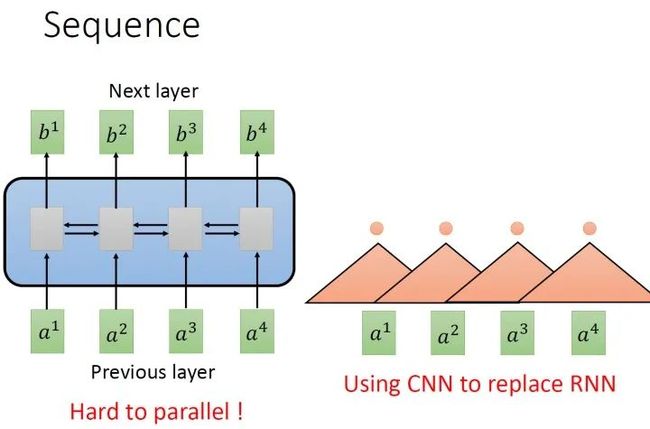 图1:处理Sequence数据的模型
图1:处理Sequence数据的模型
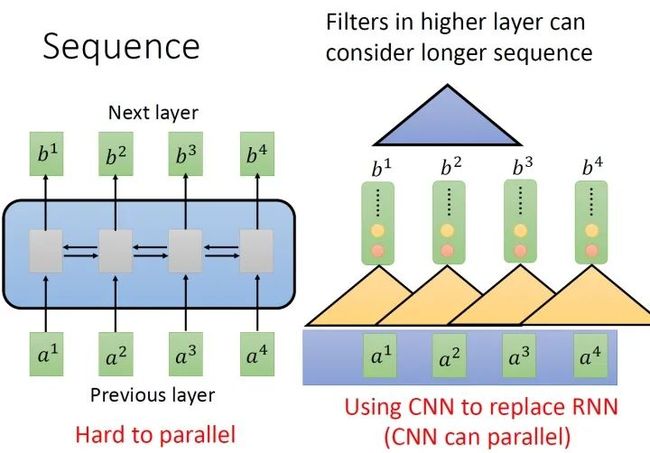 图2:处理Sequence数据的模型
图2:处理Sequence数据的模型
所以,用CNN,你确实也可以做到跟RNN的输入输出类似的关系,也可以做到输入是一个sequence,输出是另外一个sequence。
但是,表面上CNN和RNN可以做到相同的输入和输出,但是CNN只能考虑非常有限的内容。比如在我们右侧的图中CNN的filter只考虑了3个vector,不像RNN可以考虑之前的所有vector。但是CNN也不是没有办法考虑很长时间的dependency的,你只需要堆叠filter,多堆叠几层,上层的filter就可以考虑比较多的资讯,比如,第二层的filter (蓝色的三角形)看了6个vector,所以,只要叠很多层,就能够看很长时间的资讯。
而CNN的一个好处是:它是可以并行化的 (can parallel),不需要等待红色的filter算完,再算黄色的filter。但是必须要叠很多层filter,才可以看到长时的资讯。所以今天有一个想法:self-attention,如下图3所示,目的是使用self-attention layer取代RNN所做的事情。
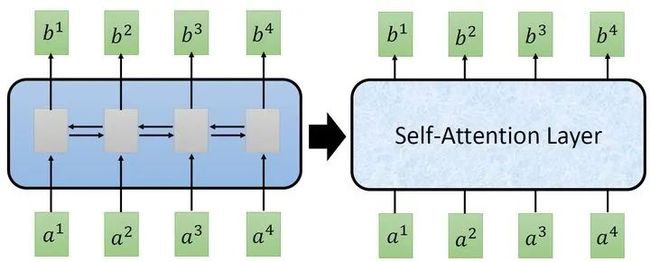 图3:You can try to replace any thing that has been done by RNNwith self attention
图3:You can try to replace any thing that has been done by RNNwith self attention
所以重点是:我们有一种新的layer,叫self-attention,它的输入和输出和RNN是一模一样的,输入一个sequence,输出一个sequence,它的每一个输出 都看过了整个的输入sequence,这一点与bi-directional RNN相同。但是神奇的地方是:它的每一个输出 可以并行化计算。
1.2 Self-attention:
那么self-attention具体是怎么做的呢?
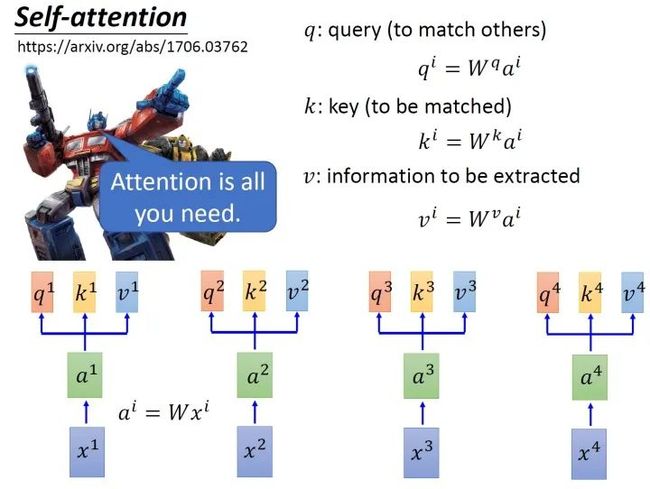 图4:self-attention具体是怎么做的?
图4:self-attention具体是怎么做的?
首先假设我们的input是图4的 ,是一个sequence,每一个input (vector)先乘上一个矩阵 得到embedding,即向量 。接着这个embedding进入self-attention层,每一个向量 分别乘上3个不同的transformation matrix ,以向量 为例,分别得到3个不同的向量 。
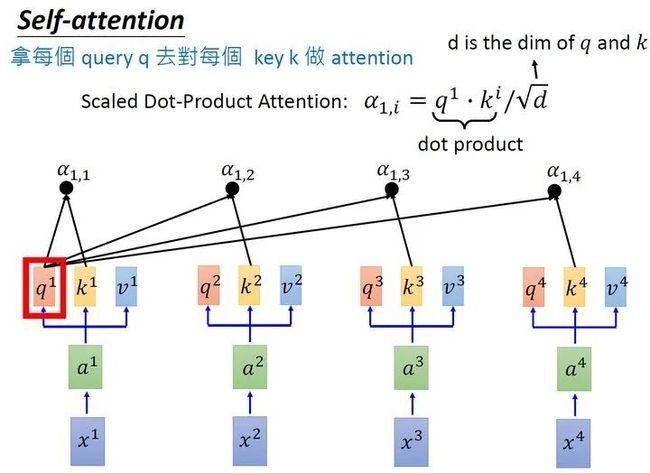 图5:self-attention具体是怎么做的?
图5:self-attention具体是怎么做的?
接下来使用每个query 去对每个key 做attention,attention就是匹配这2个向量有多接近,比如我现在要对 和 做attention,我就可以把这2个向量做scaled inner product,得到 。接下来你再拿 和 做attention,得到 ,你再拿 和 做attention,得到 ,你再拿 和 做attention,得到 。那这个scaled inner product具体是怎么计算的呢?
式中, 是 跟 的维度。因为 的数值会随着dimension的增大而增大,所以要除以 的值,相当于归一化的效果。
接下来要做的事如图6所示,把计算得到的所有 值取 操作。
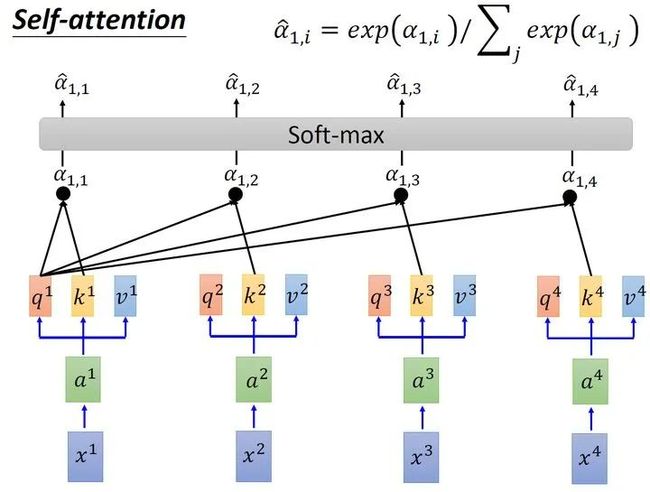 图6:self-attention具体是怎么做的?
图6:self-attention具体是怎么做的?
取完 操作以后,我们得到了 ,我们用它和所有的 值进行相乘。具体来讲,把 乘上 ,把 乘上 ,把 乘上 ,把 乘上 ,把结果通通加起来得到 ,所以,今天在产生 的过程中用了整个sequence的资讯 (Considering the whole sequence)。如果要考虑local的information,则只需要学习出相应的 , 就不再带有那个对应分支的信息了;如果要考虑global的information,则只需要学习出相应的 , 就带有全部的对应分支的信息了。
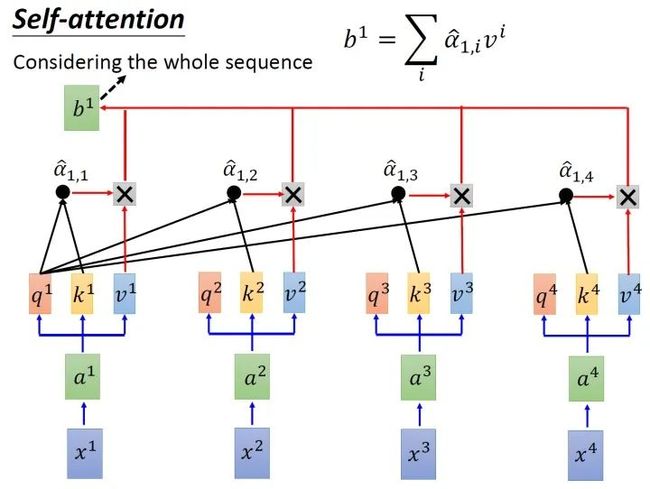 图7:self-attention具体是怎么做的?
图7:self-attention具体是怎么做的?
同样的方法,也可以计算出 ,如下图8所示, 就是拿query 去对其他的 做attention,得到 ,再与value值 相乘取weighted sum得到的。
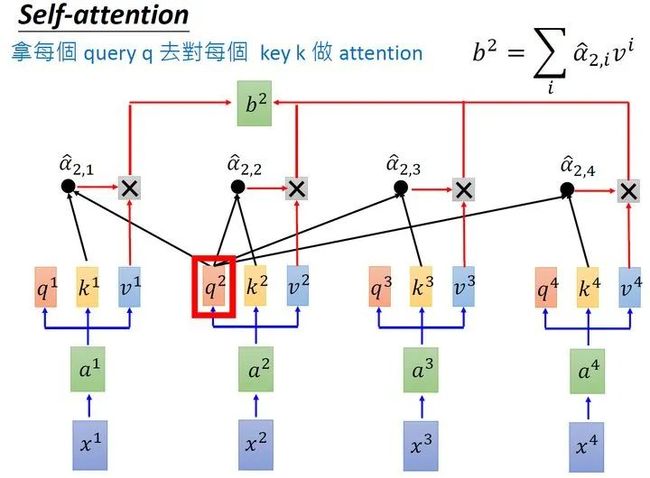 图8:self-attention具体是怎么做的?
图8:self-attention具体是怎么做的?
经过了以上一连串计算,self-attention layer做的事情跟RNN是一样的,只是它可以并行的得到layer输出的结果,如图9所示。现在我们要用矩阵表示上述的计算过程。
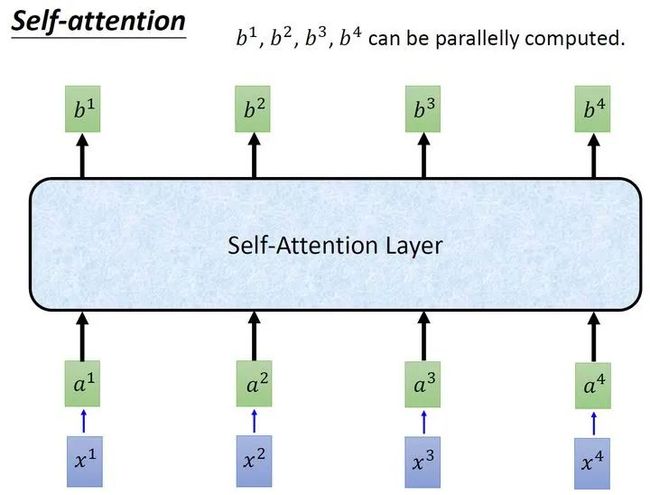 图9:self-attention的效果
图9:self-attention的效果
首先输入的embedding是 ,然后用 乘以transformation matrix 得到 ,它的每一列代表着一个vector 。同理,用 乘以transformation matrix 得到 ,它的每一列代表着一个vector 。用 乘以transformation matrix 得到 ,它的每一列代表着一个vector 。
 图10:self-attention的矩阵计算过程
图10:self-attention的矩阵计算过程
接下来是 与 的attention过程,我们可以把vector 横过来变成行向量,与列向量 做内积,这里省略了 。这样, 就成为了 的矩阵,它由4个行向量拼成的矩阵和4个列向量拼成的矩阵做内积得到,如图11所示。
在得到 以后,如上文所述,要得到 , 就要使用 分别与 相乘再求和得到,所以 要再左乘 矩阵。
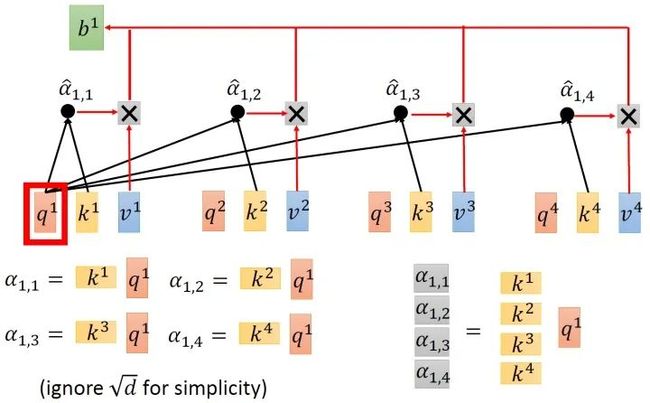

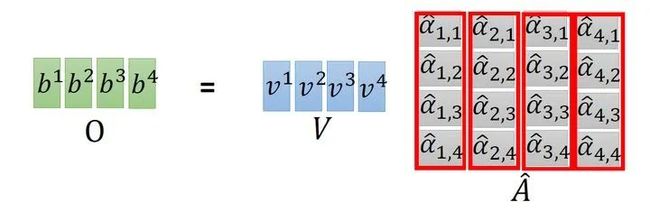 图11:self-attention的矩阵计算过程
图11:self-attention的矩阵计算过程
到这里你会发现这个过程可以被表示为,如图12所示:输入矩阵 分别乘上3个不同的矩阵 得到3个中间矩阵 。它们的维度是相同的。把 转置之后与 相乘得到Attention矩阵 ,代表每一个位置两两之间的attention。再将它取 操作得到 ,最后将它乘以 矩阵得到输出vector 。
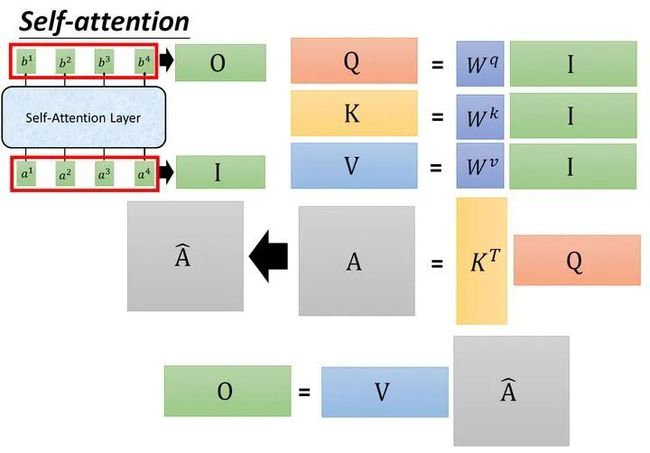 图12:self-attention就是一堆矩阵乘法,可以实现GPU加速
图12:self-attention就是一堆矩阵乘法,可以实现GPU加速
1.3 Multi-head Self-attention:
还有一种multi-head的self-attention,以2个head的情况为例:由 生成的 进一步乘以2个转移矩阵变为 和 ,同理由 生成的 进一步乘以2个转移矩阵变为 和 ,由 生成的 进一步乘以2个转移矩阵变为 和 。接下来 再与 做attention,得到weighted sum的权重 ,再与 做weighted sum得到最终的 。同理得到 。现在我们有了 和 ,可以把它们concat起来,再通过一个transformation matrix调整维度,使之与刚才的 维度一致(这步如图13所示)。
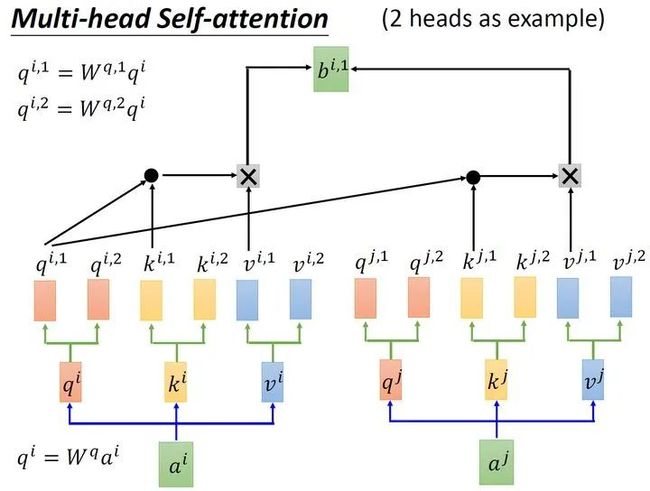
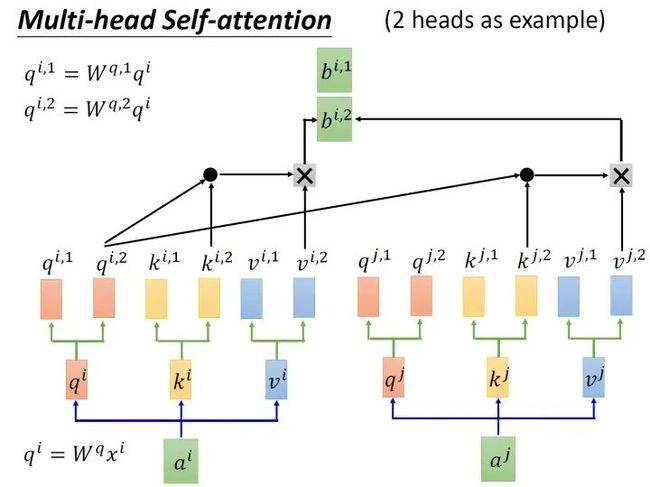 图13:multi-head self-attention
图13:multi-head self-attention
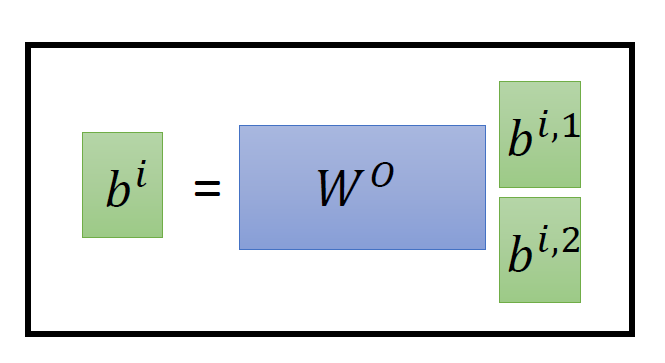 图13:调整b的维度
图13:调整b的维度
从下图14可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入 分别传递到 2个不同的 Self-Attention 中,计算得到 2 个输出结果。得到2个输出矩阵之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出 。可以看到 Multi-Head Attention 输出的矩阵 与其输入的矩阵 的维度是一样的。
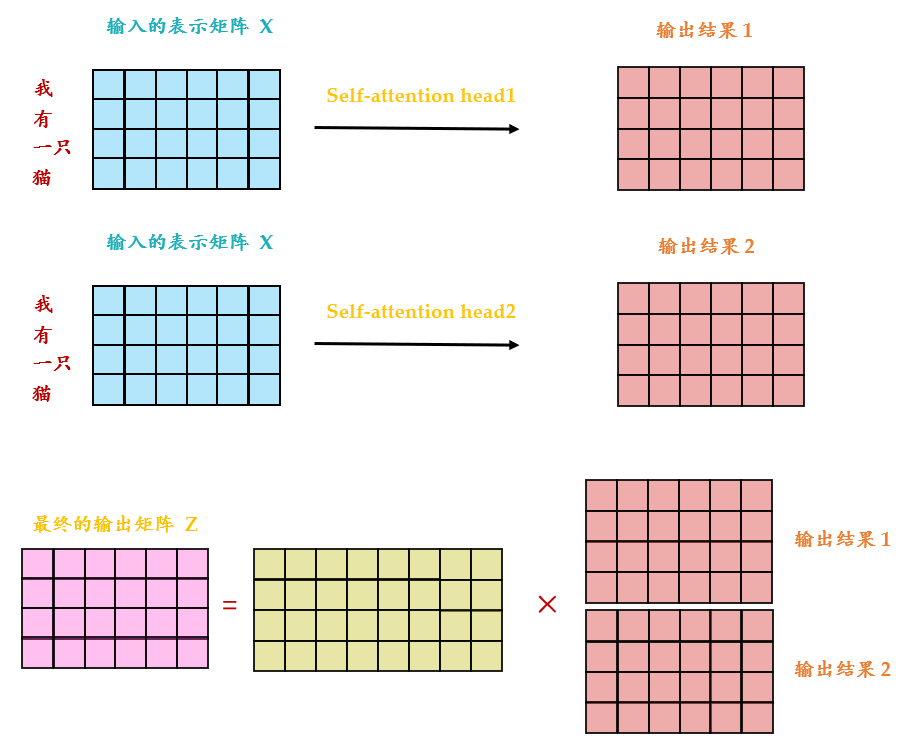 图14:multi-head self-attention
图14:multi-head self-attention
这里有一组Multi-head Self-attention的解果,其中绿色部分是一组query和key,红色部分是另外一组query和key,可以发现绿色部分其实更关注global的信息,而红色部分其实更关注local的信息。
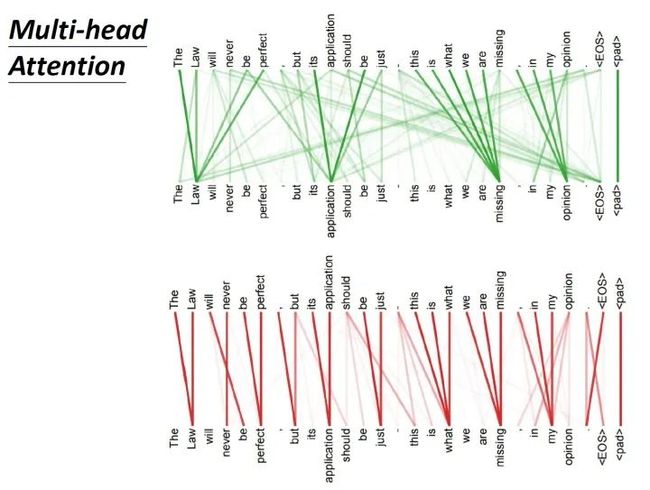 图15:Multi-head Self-attention的不同head分别关注了global和local的讯息
图15:Multi-head Self-attention的不同head分别关注了global和local的讯息
1.4 Positional Encoding:
以上是multi-head self-attention的原理,但是还有一个问题是:现在的self-attention中没有位置的信息,一个单词向量的“近在咫尺”位置的单词向量和“远在天涯”位置的单词向量效果是一样的,没有表示位置的信息(No position information in self attention)。所以你输入"A打了B"或者"B打了A"的效果其实是一样的,因为并没有考虑位置的信息。所以在self-attention原来的paper中,作者为了解决这个问题所做的事情是如下图16所示:
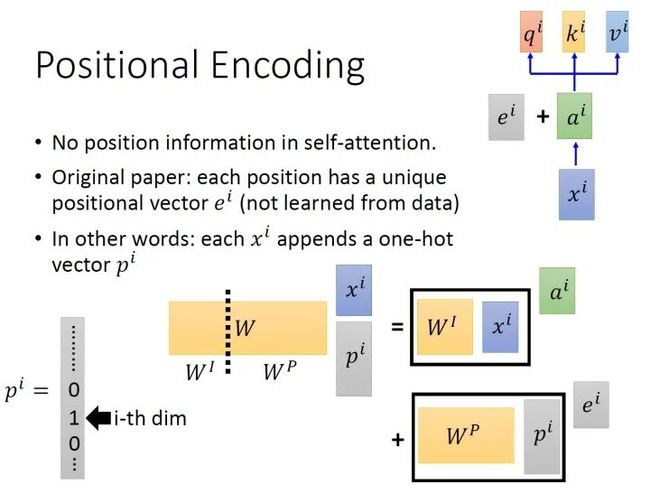
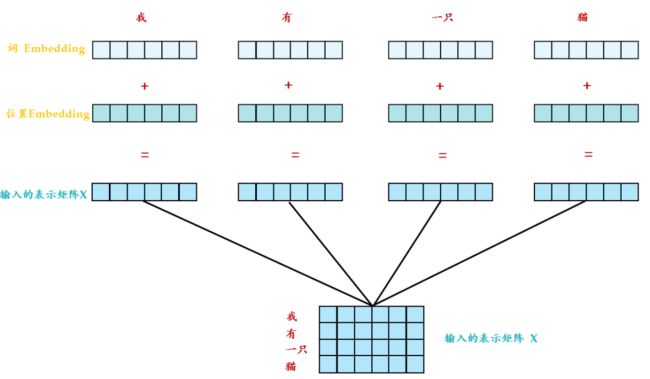 图16:self-attention中的位置编码
图16:self-attention中的位置编码
具体的做法是:给每一个位置规定一个表示位置信息的向量 ,让它与 加在一起之后作为新的 参与后面的运算过程,但是这个向量 是由人工设定的,而不是神经网络学习出来的。每一个位置都有一个不同的 。
那到这里一个自然而然的问题是:为什么是 与 相加?为什么不是concatenate?加起来以后,原来表示位置的资讯不就混到 里面去了吗?不就很难被找到了吗?
这里提供一种解答这个问题的思路:
如图15所示,我们先给每一个位置的 append一个one-hot编码的向量 ,得到一个新的输入向量 ,这个向量作为新的输入,乘以一个transformation matrix 。那么:
所以, 与 相加就等同于把原来的输入 concat一个表示位置的独热编码 ,再做transformation。
这个与位置编码乘起来的矩阵 是手工设计的,如图17所示。
 图17:与位置编码乘起来的转移矩阵WP
图17:与位置编码乘起来的转移矩阵WP
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
式中, 表示token在sequence中的位置,例如第一个token "我" 的 。
,或者准确意义上是 和 表示了Positional Encoding的维度, 的取值范围是: 。所以当 为1时,对应的Positional Encoding可以写成:
式中, 。底数是10000。为什么要使用10000呢,这个就类似于玄学了,原论文中完全没有提啊,这里不得不说说论文的readability的问题,即便是很多高引的文章,最基本的内容都讨论不清楚,所以才出现像上面提问里的讨论,说实话这些论文还远远没有做到easy to follow。这里我给出一个假想: 是一个比较接近1的数(1.018),如果用100000,则是1.023。这里只是猜想一下,其实大家应该完全可以使用另一个底数。
这个式子的好处是:
每个位置有一个唯一的positional encoding。
使 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
可以让模型容易地计算出相对位置,对于固定长度的间距 ,任意位置的 都可以被 的线性函数表示,因为三角函数特性:
接下来我们看看self-attention在sequence2sequence model里面是怎么使用的,我们可以把Encoder-Decoder中的RNN用self-attention取代掉。
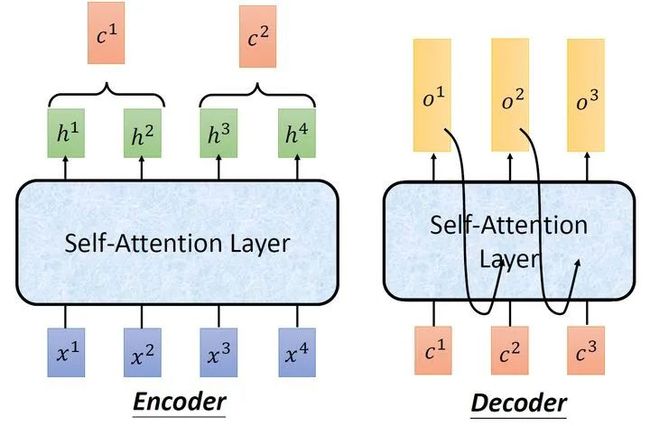 图18:Seq2seq with Attention
图18:Seq2seq with Attention
2 Transformer的实现和代码解读
2.1 Transformer原理分析:
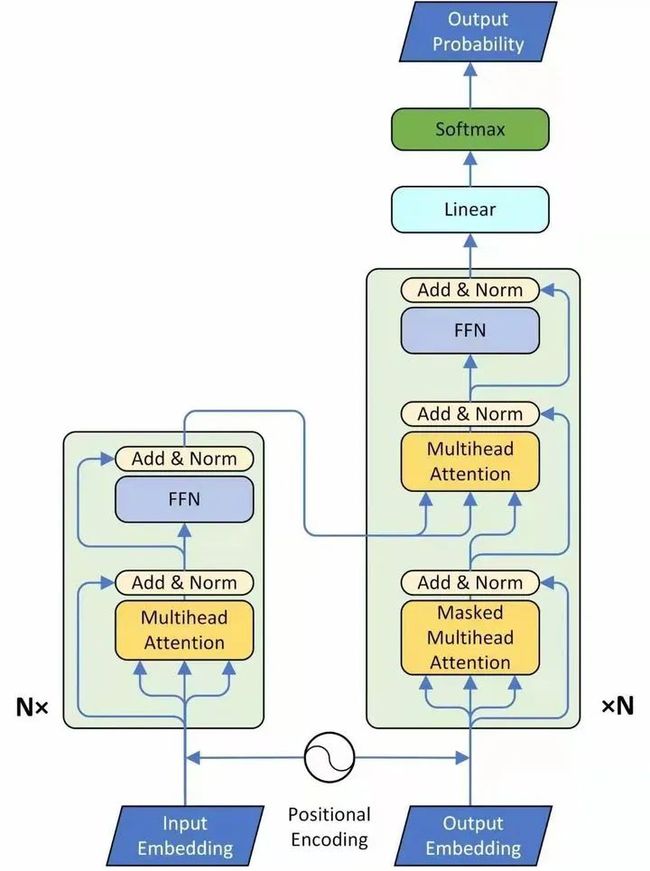 图19:Transformer
图19:Transformer
Encoder:
这个图19讲的是一个seq2seq的model,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为Multi-Head Attention,是由多个Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。比如说在Encoder Input处的输入是机器学习,在Decoder Input处的输入是
接下来我们看看这个Encoder和Decoder里面分别都做了什么事情,先看左半部分的Encoder:首先输入 通过一个Input Embedding的转移矩阵 变为了一个张量,即上文所述的 ,再加上一个表示位置的Positional Encoding ,得到一个张量,去往后面的操作。
它进入了这个绿色的block,这个绿色的block会重复 次。这个绿色的block里面有什么呢?它的第1层是一个上文讲的multi-head的attention。你现在一个sequence ,经过一个multi-head的attention,你会得到另外一个sequence 。
下一个Layer是Add & Norm,这个意思是说:把multi-head的attention的layer的输入 和输出 进行相加以后,再做Layer Normalization,至于Layer Normalization和我们熟悉的Batch Normalization的区别是什么,请参考图20和21。
 图20:不同Normalization方法的对比
图20:不同Normalization方法的对比
其中,Batch Normalization和Layer Normalization的对比可以概括为图20,Batch Normalization强行让一个batch的数据的某个channel的 ,而Layer Normalization让一个数据的所有channel的 。
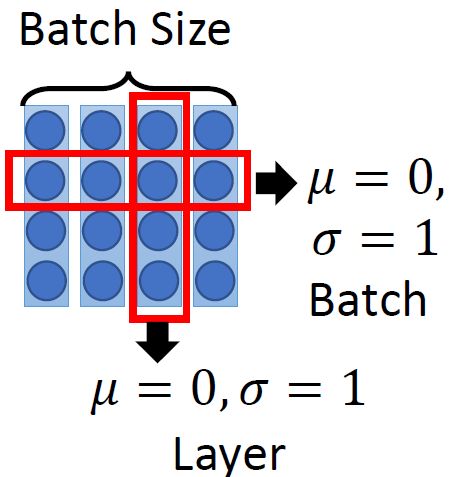 图21:Batch Normalization和Layer Normalization的对比
图21:Batch Normalization和Layer Normalization的对比
接着是一个Feed Forward的前馈网络和一个Add & Norm Layer。
所以,这一个绿色的block的前2个Layer操作的表达式为:
这一个绿色的block的后2个Layer操作的表达式为:
所以Transformer的Encoder的整体操作为:
Decoder:
现在来看Decoder的部分,输入包括2部分,下方是前一个time step的输出的embedding,即上文所述的 ,再加上一个表示位置的Positional Encoding ,得到一个张量,去往后面的操作。它进入了这个绿色的block,这个绿色的block会重复 次。这个绿色的block里面有什么呢?
首先是Masked Multi-Head Self-attention,masked的意思是使attention只会attend on已经产生的sequence,这个很合理,因为还没有产生出来的东西不存在,就无法做attention。
输出是: 对应 位置的输出词的概率分布。
输入是: 的输出 和 对应 位置decoder的输出。所以中间的attention不是self-attention,它的Key和Value来自encoder,Query来自上一位置 的输出。
解码:这里要特别注意一下,编码可以并行计算,一次性全部Encoding出来,但解码不是一次把所有序列解出来的,而是像 一样一个一个解出来的,因为要用上一个位置的输入当作attention的query。
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的attention多加了一个mask,因为训练时的output都是Ground Truth,这样可以确保预测第 个位置时不会接触到未来的信息。
包含两个 Multi-Head Attention 层。
第一个 Multi-Head Attention 层采用了 Masked 操作。
第二个 Multi-Head Attention 层的Key,Value矩阵使用 Encoder 的编码信息矩阵 进行计算,而Query使用上一个 Decoder block 的输出计算。
最后有一个 Softmax 层计算下一个翻译单词的概率。
下面详细介绍下Masked Multi-Head Self-attention的具体操作,Masked在Scale操作之后,softmax操作之前。
 图22:Masked在Scale操作之后,softmax操作之前
图22:Masked在Scale操作之后,softmax操作之前
因为在翻译的过程中是顺序翻译的,即翻译完第 个单词,才可以翻译第 个单词。通过 Masked 操作可以防止第 个单词知道第 个单词之后的信息。下面以 "我有一只猫" 翻译成 "I have a cat" 为例,了解一下 Masked 操作。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 "
Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 (
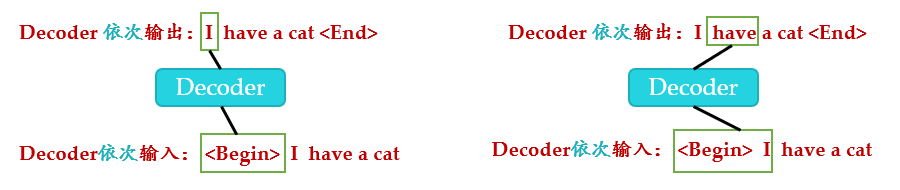 图23:Decoder过程
图23:Decoder过程
注意这里transformer模型训练和测试的方法不同:
测试时:
输入
,解码器输出 I 。 输入前面已经解码的
和 I,解码器输出have。 输入已经解码的
,I, have, a, cat,解码器输出解码结束标志位 ,每次解码都会利用前面已经解码输出的所有单词嵌入信息。
Transformer测试时的解码过程:
训练时:
不采用上述类似RNN的方法 一个一个目标单词嵌入向量顺序输入训练,想采用类似编码器中的矩阵并行算法,一步就把所有目标单词预测出来。要实现这个功能就可以参考编码器的操作,把目标单词嵌入向量组成矩阵一次输入即可。即:并行化训练。
但是在解码have时候,不能利用到后面单词a和cat的目标单词嵌入向量信息,否则这就是作弊(测试时候不可能能未卜先知)。为此引入mask。具体是:在解码器中,self-attention层只被允许处理输出序列中更靠前的那些位置,在softmax步骤前,它会把后面的位置给隐去。
Masked Multi-Head Self-attention的具体操作 如图24所示。
Step1: 输入矩阵包含 "
Step2: 得到 Attention矩阵 ,此时先不急于做softmax的操作,而是先于一个 矩阵相乘,使得attention矩阵的有些位置 归0,得到Masked Attention矩阵 。 矩阵是个下三角矩阵,为什么这样设计?是因为想在计算 矩阵的某一行时,只考虑它前面token的作用。即:在计算 的第一行时,刻意地把 矩阵第一行的后面几个元素屏蔽掉,只考虑 。在产生have这个单词时,只考虑 I,不考虑之后的have a cat,即只会attend on已经产生的sequence,这个很合理,因为还没有产生出来的东西不存在,就无法做attention。
Step3: Masked Attention矩阵进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。得到的结果再与 矩阵相乘得到最终的self-attention层的输出结果 。
Step4: 只是某一个head的结果,将多个head的结果concat在一起之后再最后进行Linear Transformation得到最终的Masked Multi-Head Self-attention的输出结果 。
 图24:Masked Multi-Head Self-attention的具体操作
图24:Masked Multi-Head Self-attention的具体操作
第1个Masked Multi-Head Self-attention的 均来自Output Embedding。
第2个Multi-Head Self-attention的 来自第1个Self-attention layer的输出, 来自Encoder的输出。
为什么这么设计? 这里提供一种个人的理解:
来自Transformer Encoder的输出,所以可以看做句子(Sequence)/图片(image)的内容信息(content,比如句意是:"我有一只猫",图片内容是:"有几辆车,几个人等等")。
表达了一种诉求:希望得到什么,可以看做引导信息(guide)。
通过Multi-Head Self-attention结合在一起的过程就相当于是把我们需要的内容信息指导表达出来。
Decoder的最后是Softmax 预测输出单词。因为 Mask 的存在,使得单词 0 的输出 只包含单词 0 的信息。Softmax 根据输出矩阵的每一行预测下一个单词,如下图25所示。
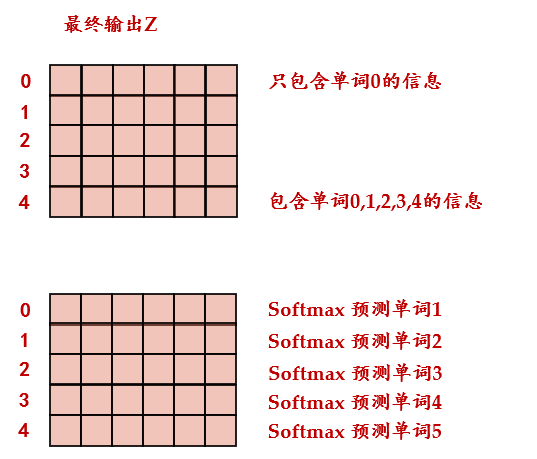 图25:Softmax 根据输出矩阵的每一行预测下一个单词
图25:Softmax 根据输出矩阵的每一行预测下一个单词
如下图26所示为Transformer的整体结构。
 图26:Transformer的整体结构
图26:Transformer的整体结构
2.2 Transformer代码解读:
代码来自:
https://github.com/jadore801120/attention-is-all-you-need-pytorch
ScaledDotProductAttention:
实现的是图22的操作,先令 ,再对结果按位乘以 矩阵,再做 操作,最后的结果与 相乘,得到self-attention的输出。
class ScaledDotProductAttention(nn.Module): ''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1): super().__init__() self.temperature = temperature self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None: attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1)) output = torch.matmul(attn, v)
return output, attn
位置编码 PositionalEncoding:
实现的是式(5)的位置编码。
class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200): super(PositionalEncoding, self).__init__()
# Not a parameter self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid): ''' Sinusoid position encoding table ''' # TODO: make it with torch instead of numpy
def get_position_angle_vec(position): return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0)#(1,N,d)
def forward(self, x): # x(B,N,d) return x + self.pos_table[:, :x.size(1)].clone().detach()
MultiHeadAttention:
实现图13,14的多头self-attention。
class MultiHeadAttention(nn.Module): ''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1): super().__init__()
self.n_head = n_head self.d_k = d_k self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False) self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False) self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False) self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout) self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv) # Separate different heads: b x lq x n x dv q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) k = self.w_ks(k).view(sz_b, len_k, n_head, d_k) v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None: mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
#q (sz_b,n_head,N=len_q,d_k) #k (sz_b,n_head,N=len_k,d_k) #v (sz_b,n_head,N=len_v,d_v)
# Transpose to move the head dimension back: b x lq x n x dv # Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv) q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
#q (sz_b,len_q,n_head,N * d_k) q = self.dropout(self.fc(q)) q += residual
q = self.layer_norm(q)
return q, attn
前向传播Feed Forward Network:
class PositionwiseFeedForward(nn.Module): ''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1): super().__init__() self.w_1 = nn.Linear(d_in, d_hid) # position-wise self.w_2 = nn.Linear(d_hid, d_in) # position-wise self.layer_norm = nn.LayerNorm(d_in, eps=1e-6) self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x))) x = self.dropout(x) x += residual
x = self.layer_norm(x)
return x
EncoderLayer:
实现图26中的一个EncoderLayer,具体的结构如图19所示。
class EncoderLayer(nn.Module): ''' Compose with two layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1): super(EncoderLayer, self).__init__() self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None): enc_output, enc_slf_attn = self.slf_attn( enc_input, enc_input, enc_input, mask=slf_attn_mask) enc_output = self.pos_ffn(enc_output) return enc_output, enc_slf_attn
DecoderLayer:
实现图26中的一个DecoderLayer,具体的结构如图19所示。
class DecoderLayer(nn.Module): ''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1): super(DecoderLayer, self).__init__() self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward( self, dec_input, enc_output, slf_attn_mask=None, dec_enc_attn_mask=None): dec_output, dec_slf_attn = self.slf_attn( dec_input, dec_input, dec_input, mask=slf_attn_mask) dec_output, dec_enc_attn = self.enc_attn( dec_output, enc_output, enc_output, mask=dec_enc_attn_mask) dec_output = self.pos_ffn(dec_output) return dec_output, dec_slf_attn, dec_enc_attn
Encoder:
实现图26,19左侧的Encoder:
class Encoder(nn.Module): ''' A encoder model with self attention mechanism. '''
def __init__( self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v, d_model, d_inner, pad_idx, dropout=0.1, n_position=200):
super().__init__()
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx) self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position) self.dropout = nn.Dropout(p=dropout) self.layer_stack = nn.ModuleList([ EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout) for _ in range(n_layers)]) self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, src_seq, src_mask, return_attns=False):
enc_slf_attn_list = []
# -- Forward
enc_output = self.dropout(self.position_enc(self.src_word_emb(src_seq))) enc_output = self.layer_norm(enc_output)
for enc_layer in self.layer_stack: enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask) enc_slf_attn_list += [enc_slf_attn] if return_attns else []
if return_attns: return enc_output, enc_slf_attn_list return enc_output,
Decoder:
实现图26,19右侧的Decoder:
class Decoder(nn.Module): ''' A decoder model with self attention mechanism. '''
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
# -- Forward dec_output = self.dropout(self.position_enc(self.trg_word_emb(trg_seq))) dec_output = self.layer_norm(dec_output)
for dec_layer in self.layer_stack: dec_output, dec_slf_attn, dec_enc_attn = dec_layer( dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask) dec_slf_attn_list += [dec_slf_attn] if return_attns else [] dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns: return dec_output, dec_slf_attn_list, dec_enc_attn_list return dec_output,
整体结构:
实现图26,19整体的Transformer:
class Transformer(nn.Module): ''' A sequence to sequence model with attention mechanism. '''
def __init__( self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx, d_word_vec=512, d_model=512, d_inner=2048, n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200, trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True):
super().__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
self.encoder = Encoder( n_src_vocab=n_src_vocab, n_position=n_position, d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner, n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v, pad_idx=src_pad_idx, dropout=dropout)
self.decoder = Decoder( n_trg_vocab=n_trg_vocab, n_position=n_position, d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner, n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v, pad_idx=trg_pad_idx, dropout=dropout)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p)
assert d_model == d_word_vec, \ 'To facilitate the residual connections, \ the dimensions of all module outputs shall be the same.'
self.x_logit_scale = 1. if trg_emb_prj_weight_sharing: # Share the weight between target word embedding & last dense layer self.trg_word_prj.weight = self.decoder.trg_word_emb.weight self.x_logit_scale = (d_model ** -0.5)
if emb_src_trg_weight_sharing: self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx) trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
enc_output, *_ = self.encoder(src_seq, src_mask) dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask) seq_logit = self.trg_word_prj(dec_output) * self.x_logit_scale
return seq_logit.view(-1, seq_logit.size(2))
产生Mask:
def get_pad_mask(seq, pad_idx): return (seq != pad_idx).unsqueeze(-2)
def get_subsequent_mask(seq): ''' For masking out the subsequent info. ''' sz_b, len_s = seq.size() subsequent_mask = (1 - torch.triu( torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool() return subsequent_mask
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
用于产生Encoder的Mask,它是一列Bool值,负责把标点mask掉。
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
用于产生Decoder的Mask。它是一个矩阵,如图24中的Mask所示,功能已在上文介绍。
3 Transformer+Detection:引入视觉领域的首创DETR
论文名称:End-to-End Object Detection with Transformers
论文地址:
https://arxiv.org/abs/2005.12872arxiv.org
3.1 DETR原理分析:
网络架构部分解读
本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。
目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图27所示。
 图27:DETR结合CNN和Transformer的结构,并行实现预测
图27:DETR结合CNN和Transformer的结构,并行实现预测
网络的主要组成是CNN和Transformer,Transformer借助第1节讲到的self-attention机制,可以显式地对一个序列中的所有elements两两之间的interactions进行建模,使得这类transformer的结构非常适合带约束的set prediction的问题。DETR的特点是:一次预测,端到端训练,set loss function和二分匹配。
文章的主要有两个关键的部分。
第一个是用transformer的encoder-decoder架构一次性生成 个box prediction。其中 是一个事先设定的、比远远大于image中object个数的一个整数。
第二个是设计了bipartite matching loss,基于预测的boxex和ground truth boxes的二分图匹配计算loss的大小,从而使得预测的box的位置和类别更接近于ground truth。
DETR整体结构可以分为四个部分:backbone,encoder,decoder和FFN,如下图28所示,以下分别解释这四个部分:
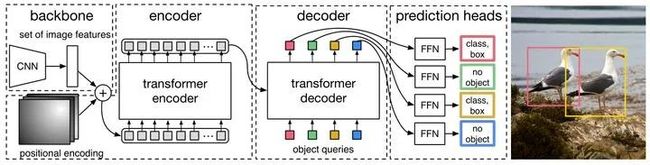 图28:DETR整体结构
图28:DETR整体结构
1 首先看backbone: CNN backbone处理 维的图像,把它转换为 维的feature map(一般来说 或 ),backbone只做这一件事。
2 再看encoder: encoder的输入是 维的feature map,接下来依次进行以下过程:
通道数压缩: 先用 convolution处理,将channels数量从 压缩到 ,即得到 维的新feature map。
转化为序列化数据: 将空间的维度(高和宽)压缩为一个维度,即把上一步得到的 维的feature map通过reshape成 维的feature map。
位置编码: 在得到了 维的feature map之后,正式输入encoder之前,需要进行 Positional Encoding 。这一步在第2节讲解transformer的时候已经提到过,因为在self-attention中需要有表示位置的信息,否则你的sequence = "A打了B" 还是sequence = "B打了A"的效果是一样的。但是transformer encoder这个结构本身却无法体现出位置信息。也就是说,我们需要对这个