记一次hadoop大数据课设准备工作--hadoop集群搭建(三个结点)+Spark安装
【未完待续…】
本次课设所使用的操作系统是华为的openEluer。
主节点部署
创建hadoop用户
创建用户:
sudo useradd -m hadoop -s /bin/bash
设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
密码统一设置为Aaaa1111@
hadoop 用户增加管理员权限,方便部署:
sudo adduser hadoop sudo
用hadoop用户登录
su - hadoop #切换当前用户为用户hadoop
分别运行上面命令后,系统中创建一个用户名为hadoop的用户,该用户拥有管理员权限,并使用hadoop用户登录当前系统。
安装最新版本的Java
更新软件列表
sudo yum update
安装openjdk-8-jdk
sudo yum install openjdk-8-jdk
查看Java版本,如下:
java -version
安装好 OpenJDK 后,需要找到相应的安装路径
update-alternatives --config java
我们输出的路径为

取绝对路径:
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
接着配置 JAVA_HOME 环境变量,先新建一个profile.d/my_env.sh:
vi /etc/profile.d/my_env.sh
添加如下内容(注意 = 号前后不能有空格)并保存:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
让该环境变量生效
source /etc/profile
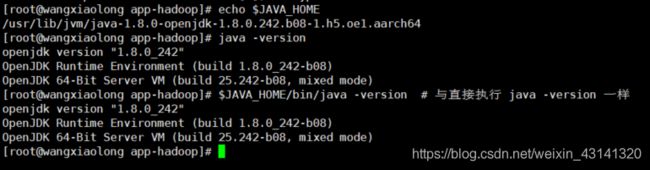
设置好后我们来检验一下是否设置正确:
echo $JAVA_HOME # 检验变量值
java -version
$JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
Hadoop下载与环境配置
先下载:(如果速度慢可以先下载到本地,然后拖过去)
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0-aarch64.tar.gz
解压:
sudo tar -zxvf hadoop-3.3.0-aarch64.tar.gz -C /root/apps
cd /root/apps
sudo mv hadoop-3.3.0 hadoop #重命名为hadoop
sudo chown -R hadoop ./hadoop #修改文件权限
配置Hadoop环境
vi /etc/profile.d/my_env.sh
将如下内容添加到该文件中:
export HADOOP_HOME=/root/apps/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
激活环境:
source /etc/profile
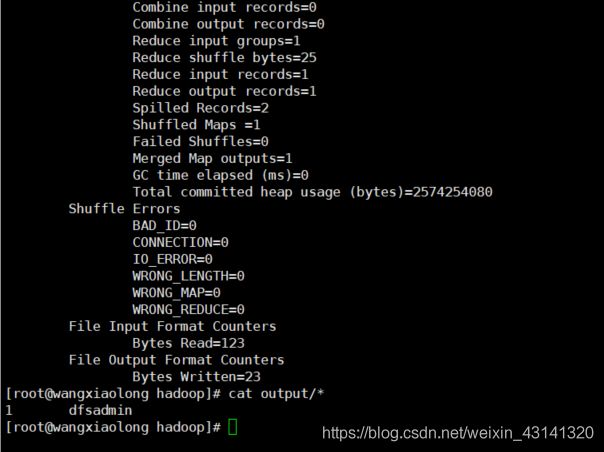
使用单机实例测试一下
进入 /tool/apps/hadoop/ 目录,运行以下命令后,查看运行结果,并分析结果。
cd /root/apps/hadoop/
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+'
cat output/*
输出如下:
Hadoop集群部署
集群配置之前,先把主节点的部分配置好,然后直接分发给从节点即可。从节点只需要下载jdk,hadoop(甚至可以将hadoop分发给从节点),其他不需要配置。
部署规划:
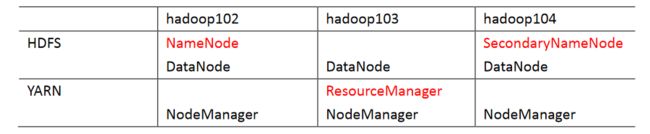
需要配置的文件
需要配置的文件均在这个目录下:
/root/apps/hadoop/etc/hadoop
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://wangxiaolong:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/root/apps/hadoop/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>rootvalue>
property>
configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>wangxiaolong:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>huangzhenyi:9868value>
property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enablename>
<value>truevalue>
property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policyname>
<value>NEVERvalue>
property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.best-effortname>
<value>falsevalue>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
description>
property>
configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>guojiataovalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://wangxiaolong:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>wangxiaolong:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>wangxiaolong:19888value>
property>
configuration>
hadoop-env.sh
将你配置环境变量时的jdk路径放进去即可,比如我的是JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
yarn-env.sh
将你配置环境变量时的jdk路径放进去即可,比如我的是JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
mapred-env.sh
将你配置环境变量时的jdk路径放进去即可,比如我的是JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
wokers
这个文件在之前的版本中是slaves文件,后来改成了workers。
添加结点的主机名:
wangxiaolong
guojiatao
huangzhenyi