论文阅读:Fully Convolutional Networks for Panoptic Segmentation
标题:用于全景分割的全卷积网络
作者:Yanwei Li, Hengshuang Zhao, Xiaojuan Qi, Liwei Wang, Zeming Li, Jian Sun, Jiaya Jia
机构:Chinese University of Hong Kong University of Oxford University of Hong Kong MEGVII Technology
论文地址:https://arxiv.org/pdf/2012.00720.pdf
项目地址:https://github.com/yanwei-li/PanopticFCN
摘要
在本文中,我们提出了一种概念上简单,强大且有效的全景图分割框架,称为Panoptic FCN。我们的方法旨在在统一的全卷积网络中表示和预测前景事物(thing)和背景事物(stuff)。Panoptic FCN使用提出的内核生成器(kernel generator)将每个对象实例或填充(stuff )类别编码为特定的内核权重(kernel weight),并通过直接将高分辨率特征卷积来产生预测。使用这种方法,可以在一个简单的生成内核然后分段工作流中分别满足事物和事物的实例感知和语义上一致的属性。在没有额外的框用于定位或实例分离的情况下,所提出的方法在单尺度输入的COCO,Cityscapes和Mapillary Vistas数据集上的性能优于以前的box-based and box-free的方式。
疑问:所谓的kernel generator指的是卷积核的kernel weight的生成吗?感觉有点像deformable conv的操作。
介绍
全景分割的一个主要难点在于:统一表示来自thing和stuff要求的冲突属性(conflicting properties)。实例对象通过instance-aware features区分(比如solo中的位置大小),而stuff则更加偏好于semantically consistent characters(连续性特征)。因此往往两者的模型是分开设计的。因此,需要统一的表示形式来弥合这一差距。
本篇文章提出了Panoptic FCN,一个全卷积框架。
Panoptic FCN的关键思想是在完全卷积的网络结构中用生成的内核统一地表示和预测thing和stuff。
具体设计是包括两个方面:内核生成器(kernel generator)和特征编码器(feature encoder),分别用于内核权重生成和共享特征编码。具体来说,在内核生成器中,我们参考基于点的目标检测器方式,并利用position head分别通过对象中心(object centers)和填充区域(stuff regions)对前景对象(objects)和背景填充物(stuff)进行定位和分类 。 然后,我们从内核头中选择具有相同位置的内核权重来表示相应的实例。 对于上述实例感知和语义一致性,还提出了一个称为内核融合kernel fusion的内核级操作,该操作合并了预测具有相同身份或语义类别的内核权重。 借助特征编码器,该编码器保留了具有细节的高分辨率特征,可以通过直接对生成的内核进行卷积来生成事物的预测。
To this end, kernel generator and feature encoder are
respectively designed for kernel weights generation and shared feature encoding. Specifically, in kernel genera- tor, we draw inspirations from point-based object detec- tors [19, 53] and utilize the position head to locate as well as classify foreground objects and background stuff by ob- ject centers and stuff regions, respectively. Then, we se- lect kernel weights with the same positions from the kernel head to represent corresponding instances. For the instance- awareness and semantic-consistency described above, a kernel-level operation, called kernel fusion, is further pro- posed, which merges kernel weights that are predicted to have the same identity or semantic category. With a naive feature encoder, which preserves the high-resolution feature with details, each prediction of things and stuff can be produced by convolving with generated kernels directly.
Panoptic FCN在没有更多花销的情况下,在效率上优于以前的方法,并且在COCO val和test dev数据集上分别达到44.3%PQ和47.5%PQ。 同时,它在很大程度上超越了所有类似的无盒方法,并在Cityscapes和Mapillary Vistas val 数据集分别为61.4%PQ和36.9%PQ。
疑问:看到这里,应该是用kernel generator来生成对于不同thing和stuff的不同kernel weight,然后利用特征编码器的结果和生成的kernel weight卷积,以生成最后的结果? 下面关注kernel generator是怎么操作的
相关工作
- Panoptic Segmentation
- Instance Segmentation
Box-based:Mask R-CNN , PANet , YOLACT , CenterMask , and PointINS.
Box-free:SGN, SSAP , TensorMask, and SOLO. - Semantic Segmentation
Panoptic FCN
Panoptic FCN在概念上很简单:
- 引入了内核生成器来为具有不同类别的thing和stuff生成内核权重
- 内核融合旨在将来自多个阶段的具有相同标识的内核权重进行合并
- 特征编码器用于对高分辨率特征进行编码

Kernel Generator
Kernel Generator的输入是FPN 中第i阶段的单阶段特征 X i X_i Xi,输出是对于thing L i t h L^{th}_i Lith和stuff L i s t L^{st}_i List的带有位置信息的Kernel weight map G i G_i Gi 。kernel generator模块包含两个部分,如上面的图,其中的position head是用来对定位和分类的,kernel head则是kernel权重生成。
1、Position head
输入是FPN 中第i阶段的单阶段特征 X i X_i Xi,经过堆叠的卷积块进一步编码特征得到 X i ′ X'_i Xi′。
然后根据对象中心(object center)和填充区域(stuff regions)来分别表示每个个体和填充类别的位置。(同一类别的stuff看作一个实例)这样,整个图都可以用区分实例的方法来进行thing和stuff的位置和分类了。
输出:object map L i t h ∈ R N t h × W i × H i L^{th}_i ∈ R^{N_{th}×W_i×H_i} Lith∈RNth×Wi×Hi and stuff map L i s t ∈ R N s t × W i × H i L^{st}_i ∈ R^{N_{st}×W_i×H_i} List∈RNst×Wi×Hi
为了优化这个输出,文章对于ground truth的生成做了处理:
对于类别c中的第k个对象,将正关键点(positive key-points这里的正关键点指的是???)利用高斯核划分到热图(heatmap) Y i t h ∈ [ 0 , 1 ] N t h × W i × H i Y^{th}_i∈[0,1]^{N_{th}×W_i×H_i} Yith∈[0,1]Nth×Wi×Hi的第c个通道上。(也就是说用通道表示类别,不同关键点表示不同的对象)。

这里的 x k − a n d y k − x^-_k and y^-_k xk−andyk−表示第k个对象的center。其中 o k 2 o^2_k ok2 是表示对象尺寸的标准偏差。
o k o_k ok = ( x k / n − [ x k / n ] , y k / n − [ y k / n ] ) (x_k/n-[x_k/n],y_k/n-[y_k/n]) (xk/n−[xk/n],yk/n−[yk/n])
解释1: 在下采样阶段中,(x,y)位置的像素被映射为( [ x / n ] , [ y / n ] [x/n],[y/n] [x/n],[y/n]),而对其还原时,会存在一定精度上的损失,对IOU造成影响,因此,在对其remap到输入尺寸之前,预测位置偏移对角点的位置进行微调。
解释2:因为feature map比原始图像肯定是小的,所以在由feature map映射到原图像位置的时候就存在一定偏移,比如原始图像的位置为(220,220),下采样的比率为3,则对应的feature map的位置就是(73,73),而要映射回去的时候却出现了问题,因为73*3 = 219,所以是有偏移的,这个偏移可以通过网络学习,这样不仅可以消去偏移,而且可以让临近点尽可能忘gt靠拢。注:Heatmap指在目标检测、人脸检测或关键点检测等任务中经常出现的热力图,图上某点的值为[0,1]区间内的小数,通常表示此处有目标(或者人脸)的概率。实际研究中Heatmap可能是某个网络得到的任意一个概率分布图。
而对于stuff regions,通过对one-hot semantic annotation双线性插值到相应大小(???)得到: Y i s t ∈ [ 0 , 1 ] N s t × W i × H i Y^{st}_i ∈ [0, 1]N^{st}×W_i×H_i Yist∈[0,1]Nst×Wi×Hi
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。参考:https://blog.csdn.net/linh47/article/details/79000574?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-11&spm=1001.2101.3001.4242
所以position head的损失优化函数:

2、Kernel head
首先通过将相对坐标直接concatenate到特征 X i X_i Xi来捕获空间位置线索,这与CoordConv中的相似。这样就得到了合并的特征图 X i ′ ′ ∈ R ( C i + 2 ) × W i × H i X''_i∈R^{(C_i+2)}×W_i×H_i Xi′′∈R(Ci+2)×Wi×Hi
然后堆叠的卷积块(如上面的框架流程图所示),从 X i ′ ′ X''_i Xi′′生成核权重图(kernel weight map) G i ∈ R ( C e ) × W i × H i G_i∈R^{(C_e)}×W_i×H_i Gi∈R(Ce)×Wi×Hi
有了从position head预测的 D i t h D^{th}_i Dith和 D i s t D^{st}_i Dist,选择在 G i G_i Gi中具有相同坐标的内核权重来表示相应的实例。例如,假设候选 ( x c , y c ) ∈ D i t h (x_c,y_c)∈D^{th}_i (xc,yc)∈Dith,选择内核权重 G i , : , x c , y c ∈ R C e × 1 × 1 G_i,:,x_c,y_c∈R^{C_e×1×1} Gi,:,xc,yc∈RCe×1×1以生成具有预测类别c的结果。
这个公式没看懂…
3、Kernel Fusion
设计的内核融合操作会在最终实例生成之前合并来自多个FPN阶段的重复内核权重,从而分别确保事物和事物的实例感知和语义一致性。
详细点讲就是:从所有FPN stage得到的kernel weight D t h D^{th} Dth 和 D s t D^{st} Dst,第j个kernel weight K j ∈ R C e × 1 × 1 = A v g P o o l ( G j ′ ) K_j ∈ R^{C_e×1×1} = AvgPool(G'_j) Kj∈RCe×1×1=AvgPool(Gj′)
the candidate set G j ′ G'_j Gj′= { G m : I D ( G m ) = I D ( G j ) G_m : ID(G_m) = ID(G_j) Gm:ID(Gm)=ID(Gj)} includes all the
kernel weights, which are predicted to have the same identity ID with
Gj.
对于对象中心,如果它们之间的余弦相似度超过给定阈值thres,则将内核权重 G m t h G^{th}_m Gmth与 G j t h G^{th}_j Gjth视为相同.而对于sutff,与 G j s t G^{st}_j Gjst共享同一类别c的标记为一个身份ID。
利用所提出的方法,可以将 K t h = K 1 t h , . . . , K m t h ∈ R M × C e × 1 × 1 K^{th} = {K^{th}_1,...,K^{th}_m}∈R^{M×C_e×1×1} Kth=K1th,...,Kmth∈RM×Ce×1×1的每个核权重 K j t h K^{th}_j Kjth视为单个对象的编码,其中对象总数为M 。因此,具有相同标识的内核将合并为单个编码的事物,并且 K t h K^{th} Kth中的每个内核都代表一个单独的对象,这满足了事物的实例感知能力。 同时, K s t = K 1 s t , . . . , K n s t ∈ R N × C e × 1 × 1 K^{st} = {K^{st}_1,...,K^{st}_n}∈R^{N×C_e×1×1} Kst=K1st,...,Knst∈RN×Ce×1×1的核权重 K j s t K^{st}_j Kjst表示对所有第j类像素的编码,其中现有填充数为N。 这种方法将具有相同语义类别的内核融合到单个嵌入中,从而保证了东西的语义一致性。 因此,thing和stuff所要求的属性都可以通过提出的内核融合操作来实现
Feature Encoder
输入:从FPN P2 或者所有Stage融合的高分辨率特征 F h ∈ R C e × W / 4 × H / 4 F_h ∈ R^{C_e×W/4×H/4} Fh∈RCe×W/4×H/4
后续处理和上面的Kernel Generator的Kernel Head类似,加入position信息,用堆叠卷积块进一步采样
输出: F e ∈ R C e × W / 4 × H / 4 F_e ∈ R^{C_e×W/4×H/4} Fe∈RCe×W/4×H/4
融合
每个instance(包括stuff,也看作instance)可以由以下式子得到:
P j = K j ⊗ F j e P_j = K_j ⊗F^e_j Pj=Kj⊗Fje
where Pj denotes the j-th prediction, and ⊗ indicates the convolutional operation. That meansM+N kernel weights generateM+N instance predictions with resolutionW/4× H/4 for the whole image. Consequently,
最后的结果:
Consequently, the panoptic result can be produced with a simple
process [17]
这部分直接看代码吧。
Training and Inference
训练采用了修改后的Dice Loss:

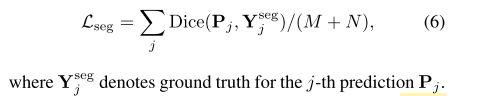

实验结果
Backbone:Resnet-FPN
主要实验数据集:COCO、Cityscopes、Mapillary Vistas
优化策略:SGD
1、加入可变形卷积效果最好,堆叠卷积的conv数量为3时效果最好
2、对于position的加入,即采用不同的坐标,两个方向坐标信息都加入时效果最好
3、对于kernel fusion部分的thres门限值设置,在0.9左右结果差别不大
4、特征编码器的通道数设置,通道数为64和128时结果差不多,最好
5、对于特征编码器的输入,feature的生成方式,FPN-P2、FPN-Summed、Semantic FPN中Semantic FPN最好
6、另外对于dice loss k的设置,3以后没有大变换,7最好
7、对于训练,从1X到2X、3X指标提升较大。这说明多尺度训练效果更好!
8、最后还有一个上限边界分析:采用ground truth的 position和 class,最后的PQ提升22.3个点。



最终的结果可以看出,文章提出方法在当时取得了不错的结果。另外在Cityscopes上的实验是单尺度输入,多尺度应该会提升2、3个点左右,也算还行吧。
虽然现在COCO上已经刷到PQ 50多,Cityscopes PQ 70了…
总结
这篇文章最值得思考的地方应该就是thing和stuff 的一致性表示:将stuff也看成instance。
不过还有很多细节没看懂,还需要多看看论文和代码实现细节。