训练的时候内存一直在增加,最后内存爆满,被迫中断。
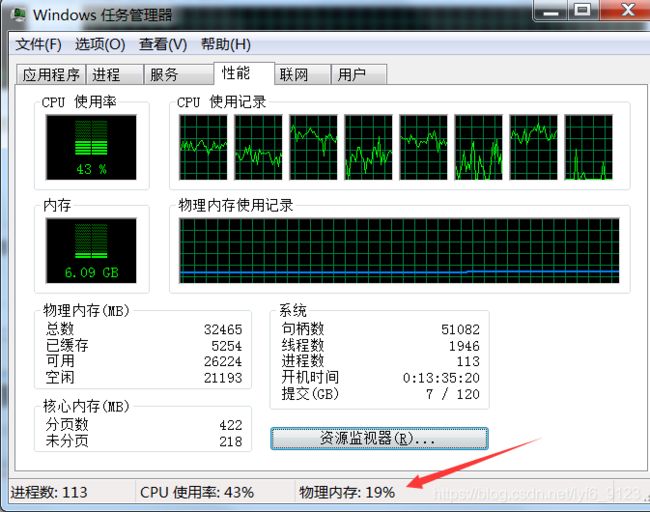
后来换了一个电脑发现还是这样,考虑是代码的问题。
检查才发现我的代码两次存了loss,只有一个地方写的是loss.item()。问题就在loss,因为loss是variable类型。
要写成loss_train = loss_train + loss.item(),不能直接写loss_train = loss_train + loss。否则就会发现随着epoch的增加,占的内存也在一点一点增加。
算是一个小坑吧,希望大家还是要仔细。
补充:pytorch神经网络解决回归问题(非常易懂)
对于pytorch的深度学习框架
在建立人工神经网络时整体的步骤主要有以下四步:
1、载入原始数据
2、构建具体神经网络
3、进行数据的训练
4、数据测试和验证
pytorch神经网络的数据载入,以MINIST书写字体的原始数据为例:
import torch
import matplotlib.pyplot as plt
def plot_curve(data):
fig=plt.figure()
plt.plot(range(len(data)),data,color="blue")
plt.legend(["value"],loc="upper right")
plt.xlabel("step")
plt.ylabel("value")
plt.show()
def plot_image(img,label,name):
fig=plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307,cmap="gray",interpolation="none")
plt.title("{}:{}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
def one_hot(label,depth=10):
out=torch.zeros(label.size(0),depth)
idx=torch.LongTensor(label).view(-1,1)
out.scatter_(dim=1,index=idx,value=1)
return out
batch_size=512
import torch
from torch import nn #完成神经网络的构建包
from torch.nn import functional as F #包含常用的函数包
from torch import optim #优化工具包
import torchvision #视觉工具包
import matplotlib.pyplot as plt
from utils import plot_curve,plot_image,one_hot
#step1 load dataset 加载数据包
train_loader=torch.utils.data.DataLoader(
torchvision.datasets.MNIST("minist_data",train=True,download=True,transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader=torch.utils.data.DataLoader(
torchvision.datasets.MNIST("minist_data",train=True,download=False,transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=False)
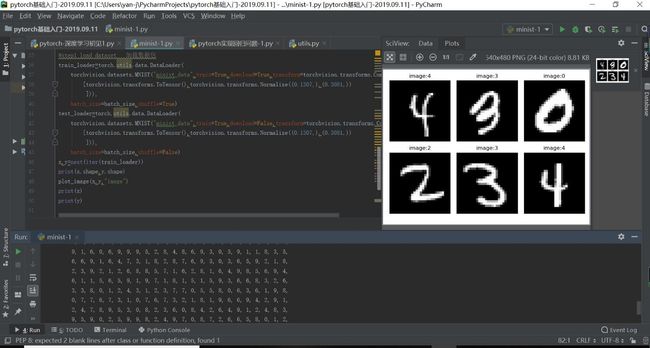
x,y=next(iter(train_loader))
print(x.shape,y.shape)
plot_image(x,y,"image")
print(x)
print(y)
以构建一个简单的回归问题的神经网络为例,
其具体的实现代码如下所示:
import torch
import torch.nn.functional as F # 激励函数都在这
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = x.pow(2) + 0.2 * torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
class Net(torch.nn.Module): # 继承 torch 的 Module(固定)
def __init__(self, n_feature, n_hidden, n_output): # 定义层的信息,n_feature多少个输入, n_hidden每层神经元, n_output多少个输出
super(Net, self).__init__() # 继承 __init__ 功能(固定)
# 定义每层用什么样的形式
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 定义隐藏层,线性输出
self.predict = torch.nn.Linear(n_hidden, n_output) # 定义输出层线性输出
def forward(self, x): # x是输入信息就是data,同时也是 Module 中的 forward 功能,定义神经网络前向传递的过程,把__init__中的层信息一个一个的组合起来
# 正向传播输入值, 神经网络分析出输出值
x = F.relu(self.hidden(x)) # 定义激励函数(隐藏层的线性值)
x = self.predict(x) # 输出层,输出值
return x
net = Net(n_feature=1, n_hidden=10, n_output=1)
print(net) # net 的结构
"""
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
"""
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 传入 net 的所有参数, 学习率
loss_func = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差)
for t in range(100): # 训练的步数100步
prediction = net(x) # 喂给 net 训练数据 x, 每迭代一步,输出预测值
loss = loss_func(prediction, y) # 计算两者的误差
# 优化步骤:
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
import matplotlib.pyplot as plt
plt.ion() # 实时画图something about plotting
for t in range(200):
prediction = net(x) # input x and predict based on x
loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if t % 5 == 0: # 每五步绘一次图
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。