【知识图谱系列】基于Random Propagation的深度图神经网络
作者:CHEONG
公众号:AI机器学习与知识图谱
研究方向:自然语言处理与知识图谱
本文介绍一篇基于Random Propagation的深度图神经网络模型Grand(NIPS 2020),介绍Grand模型核心点和模型思路,完整汇报ppt获取请关注公众号回复关键字:Grand
一、Background
Knowledge1、Over-fitting:在CNN卷积神经网络中,若CNN网络结构过于复杂过于Deep,且数据量有限的情况下,便会出现Over-fitting问题,Over-fitting就是指模型对于训练数据过度学习,学习到训练数据本身而不是训练数据的规律,导致无法在测试集上准确预测的情况。
Knowledge2、Over-Smoothing:在GNN图神经网络中,由于图本身结构上节点与节点之间相互连接的特性,并且图神经网络一般是通过邻域汇聚或随机游走的方式进行表征学习,因此当图网络一旦变深,便会出现Over-Smoothing问题,Over-Smoothing指的是随着图神经网络加深,学习到的节点表征越来越相似,以至于无法区分,模型效果也将大幅下降。且在图网络中一般2 Layers时效果最佳。因此如何在DeepGNN中既能学到更深层次信息又能避免Over-Smoothing显得至关重要。
Knowledge3、DeepGNN的必要性: 通常对于少标签半监督节点分类任务,或是少特征半监督节点分类任务,DeeperGNN便较为重要,在特征较少时,便想通过多跳传递能学到更多有效信息。
二、Motivation
当前图神经网络模型大多存在以下三个问题,为了解决这三大问题本文提出了Grand Random Neural Network
Problem1、深度图神经网络存在Over-Smoothing问题,随着GNN层数堆叠使得节点表征无法区分,最近研究表明:在Propagation过程中耦合non-linear transformation操作会加剧Over-Smoothing问题(解决策略:Random Propagation Strategy);
Problem2、固定邻居的Propagation操作会使得每个节点高度依赖它的多跳邻居,导致节点表征更容易受到潜在数据噪音误导,降低模型的鲁棒性(解决策略:解耦Transformation和Propagation);
Problem3、在半监督学习中,之前针对GNN标准的训练方法很容易过度拟合稀缺的标签信息,因此如何在半监督学习中充分利用大量未标记数据便是一个关注点(解决策略:Data Augmentation Methods for Consistency Regularized Training)。
三、Method
为了解决上述提及的问题,本文提出Grand模型,两个主要的创新点:
1、Random Propagation for Graph Data Augmentation;
2、Consistency Regularized Training。
接下来我们先通过模型图来快速理解一下Grand模型运行流程,然后再从公式角度详细分析一下Grand模型的两大创新点。
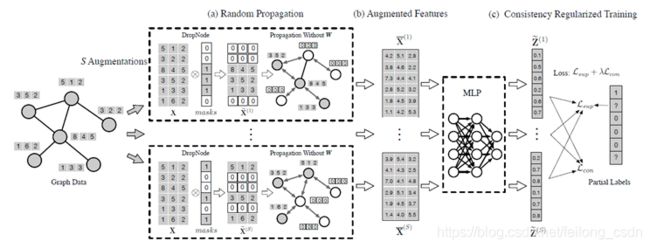
上图是Grand模型图,按照顺序讲解一下模型各个步骤的具体操作:
> S Augmentation:第一步对GraphData进行S次数据增强;
> Random propagation:对每一份数据增强后的数据进行随机的DropNode,这里仔细看模型图,DropNode不是将图中节点直接丢掉,而是对某些节点特征随机进行mask操作,然后再进行Propagation without W,这里为什么是without W?就是上面问题2中提到的,在Propagation操作过程中不引入non-linear transformation操作;
> Augmented Features:将S份数据Propagation之后的得到的S份新数据分别进行两层MLP操作,这里的MLP操作指的便是Transformation操作。对此有疑问的可参考另一篇详细介绍了解耦Transformation和Propagation操作对DeepGNN Over-Smoothing问题的影响。
> Consistency Regularized Training:考虑到S份数据分别的预测结果可能有较大偏差,因此引入Consistency Regularized Training来控制S次Inference的结果尽可能相近。
1、Random Propagation
Grand模型对Propagation操作处理方式如下两个公式所示,其中X ̃是经过DropNode后的节点初始特征,A ̂是经过归一化后的邻接矩阵,先进行K次的Propagation操作得到A ̂^0,A ̂^1,…,A ̂^K,然后取平均后和X ̃进行特征汇聚操作。

2、Consistency Regularized Training
Grand模型训练时Loss除了常规使用的交叉熵损失函数L_sup外,引入S份数据增强的原因,为了增强模型的鲁棒性还引入了Consistency Regularization Loss,下面提供了L_sup和L_con 具体计算公式,其中Y_i是真实值,〖Z ̃_i〗^((s))是第s次数据的预测值,Z ̅_i则表示S次预测值得平均值,因此L_sup就是简单的交叉熵求和,L_con则控制每次预测结果尽可能相近。

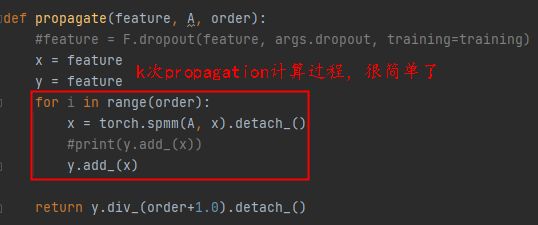
四、Code
1、Grand模型实现思路也很简单,核心代码如下图所示,官网提供代码获取地址:
https://github.com/THUDM/GRAND

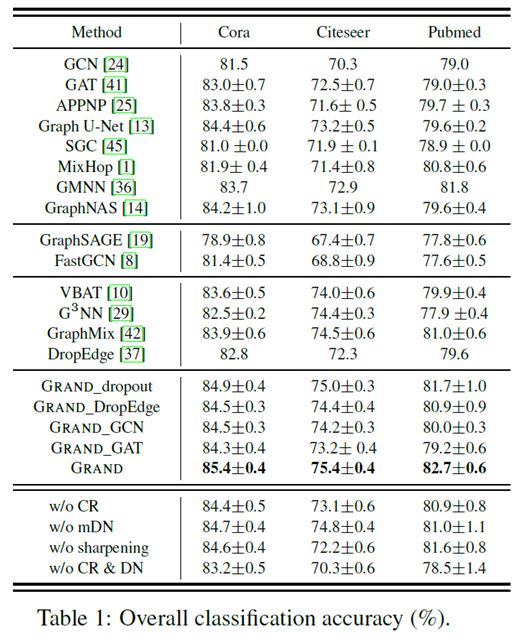
五、Conclusion
1、Grand模型在三份引文数据Cora,Citeseer和Pubmed上都取得了SOTA效果,证明了方案的有效性。
六、往期精彩
【知识图谱系列】Over-Smoothing 2020综述
【知识图谱系列】自适应深度和广度图神经网络模型
【知识图谱系列】知识图谱多跳推理之强化学习
【知识图谱系列】知识图谱的神经符号逻辑推理
【知识图谱系列】知识图谱表示学习综述 | 近30篇优秀论文串讲
【知识图谱系列】探索DeepGNN中Over-Smoothing问题
【知识图谱系列】动态时序知识图谱EvolveGCN
【知识图谱系列】多关系神经网络CompGCN
【面经系列】八位硕博大佬的字节之旅
各大AI研究院共35场NLP算法岗面经奉上
【机器学习系列】机器学习中的两大学派
干货 | Attention注意力机制超全综述
干货 | NLP中的十个预训练模型
干货|一文弄懂机器学习中偏差和方差
FastText原理和文本分类实战,看这一篇就够了
Transformer模型细节理解及Tensorflow实现
GPT,GPT2,Bert,Transformer-XL,XLNet论文阅读速递
机器学习算法篇:最大似然估计证明最小二乘法合理性
Word2vec, Fasttext, Glove, Elmo, Bert, Flair训练词向量教程+数据+源码
汇报完整版ppt可通过关注公众号后回复关键词:Grand 来获得,有用就点个赞呗!