altera fpga sdi输出方案_可重构计算:基于FPGA可重构计算的理论与实践 1.器件架构 译文(四)...

注:原文版权归作者所有,本翻译仅为爱好所作,与任职单位无关。
原作者信息:
Mark L. Chang
Electrical and Computer Engineering
Franklin W. Olin College of Engineering
1.5 案例研究 Case studies
在阅读了前文后,FPGA 对读者而言,应该不再只是一个神奇的计算黑匣子了。读者掌握了构成现代商用 FPGA 的组件的概念以及这些组件是如何组合在一起工作的。在本节中,我们将更进一步,通过学习 Altera Stratix 和Xilinx Virtex II Pro 两种实际的商业架构,将本章前面介绍的思想与具体的工业界实现联系起来,从而巩固理论抽象内容。
请注意,虽然这些器件代表了近来的 FPGA 技术,但它们并不是各自厂商的最新一代器件。(译注:即使是在成书的 2008 年)之所以选择它们而不是更先的器件,部分原因是在编写本文时产商提供的文档。通常情况下,在产品刚刚发布后,不会提供详细的体系结构信息,并且可能后续也不会提供,这取决于厂商。(译注:就译者熟悉的 Xilinx 而言,在产品发布后,其架构手册可以在官网获取)
最后,本文讨论的器件实际上比所描述的要复杂得多。现代器件进行计算的各种方式,实现的无数硬件和软件功能,创建强大和高效的设计,每一个都是一个更为庞大的话题。所以,如果对某个部分特别感兴趣,我们建议你深入器件的相关手册来了解。
译注:本书成书于十多年前(2008),所列举的 FPGA 架构难免陈旧。考虑到尽管 FPGA 架构多年来发生了许多变化,但了解过去的架构对于初识 FPGA 的结构还是有很大帮助的。译者后续有机会也会写一些文章来讨论更加现代的 FPGA 架构所做的改进。
1.5.1 Altera Stratix
我们首先来看 Altera Stratix (译注:Altera 已被 Intel 收购,该型号也更名为 Intel Stratix) FPGA 。本文大部分信息基于 2005 年 7 月版的 Altera Stratix 器件手册改变(可在 http://www.altera.com 访问)。
Stratix 是一款基于 SRAM 的岛式( island-sytle ) FPGA,包含许多异构计算单元。基本逻辑结构是逻辑阵列块(Logic array block, LAB),每个 LAB 由 10 个逻辑单元(Logic element,LE)组成。 LAB 通过一个多级互连结构将逻辑、存储和其他类型的资源整合在一起,以行和列两个维度在器件上展开。以 TriMatrix 结构提供专用存储资源,包括三种存储块大小——M512、M4K 以及 M-RAM ——每种内存块都有不同的属性。DSP 逻辑块则提供了额外的计算资源,可以高效地执行乘法和累加运算。这些资源在图 1.12 中的高层次框图中给出。

逻辑架构
架构中最小的逻辑单元是 LE,内部结构如图 1.13 所示。LE 的总体结构与此前介绍的 FPGA 基本结构非常相似:一个 4-LUT 函数生成器和一个保存状态的可编程寄存器。在 Altera LE 中,可以看到用于驱动互连结构(图 1.12 右侧)的额外组件,LE 中包括可编程寄存器置位或复位的逻辑、多个可编程时钟之间的选通逻辑、以及传播进位链。

因为 LE 是一种在器件中可能出现数万次的简单结构,Altera 将多个 LE 组织为一个 LAB 。 LAB 是一个更高层次上的基本结构,布置于二维逻辑阵列中,通过路由结构相连接。每个 LAB 由 10 个 LE 组成,内部包括 LE 的进位链逻辑 、 LAB 范围内的控制信号和一些 LE 间的互连线路。在当时 Altera 最大的器件 EP1S80 中, LAB 阵列共有 101 行和 91 列,总共拥有 79040 个 LE。之所以实际 LE 数量比该阵列上限要少(101 x 91 x 10),是由于该阵列中还包括 TriMatrix 存储结构和 DSP块 。
如图 1.14 所示, LAB 架构的关键理论上在于互联结构。其中,本地互连结构(local interconnect)允许同一个 LAB 中的多个 LE 间无需使用通用互联结构(general interconnect),即可传递信号。 而相邻 LAB 、RAM 块 以及 DSP 块之间则也可以使用本地互联结构中的直接连线相通信。最后,通用互联结构(包括水平或者垂直的通道)也可以驱动本地互联结构所连接的模块。上述高自由度的互联性,是 Stratix 结构多层、丰富的布线结构在底层的体现。
Stratix 架构中有三种类型的存储块—M512、M4K 和 M-RAM,统称为 TriMatrix 存储。这些块之间最大的区别是它们在单个器件中的容量大小和数量。一般来说,它们可以配置为多种使用模式,包括单端口 RAM、双端口 RAM、移位寄存器、FIFO 和 ROM 表。这些存储器具有可选的奇偶校验位,可选的连接至寄存器的输入和输出端口。
M512 RAM 块一般组织为 32×18bit 存储器;M4K RAM 块为 128×36bit 存储器;M-RAM 块为 4K×144bit 存储器。此外,根据用户的需要,存储块可以配置多种不同的位宽。阵列中不同大小的存储器可在器件上高效地映射为各类大小可变的存储单元。在 EP1S80 上,总共有超过 700 万个存储比特可供使用,分别为 767 个 M512 块、364 个M4K 块和 9 个M-RAM 块。

此外,Altera Stratix 架构中的逻辑单元还包括 DSP 块。每个器件都有两列 DSP 模块,用于实现数字信号处理类功能,如有限脉冲响应(FIR)和无限脉冲响应(IIR)滤波器和快速傅立叶变换(FFT),而无需使用 LE 中的通用逻辑资源来实现这些应用中所需的乘法和累加运算。
每个 DSP 单元可由用户配置为支持单个 36 位乘法,或者支持 4 个 18 位乘法,再或者 9 个 9 位乘法。实现乘法运算的同时还具有累加功能。在 EP1S80 器件中,总共有 22 个 DSP 块。
互联架构
Altera Stratix 架构提供了一个称为 MultiTrack 的互连系统,使用不同长度的连线,连接前文所讨论过的所有逻辑单元,这些连线的长度是固定的。沿着行的方向,即水平维度上的连线资源包括逻辑块(LABs、BRAM 和 DSP)之间的左向、右向直接连接,以及长度分别为 4、8 和 24 单位的连线,分别从左至右横穿 4、8 或 24 个块。

图1.15 展示了单个 LAB 层面上的 R4 (译注:从左至右跨越 4 个 LAB ,故名 R4,row 4)互联结构。所示的 R4 互连从左到右跨越 4 个块。在 Stratix 架构中各个逻辑块的相对大小允许 R4 互连在单个方向上跨越四个 LAB 、三个 LAB 和一个M512 RAM、两个 LAB 和一个 M4K RAM 或者两个 LAB 和一个 DSP 块。
这一结构对于每行中的每个 LAB 都是相同的(原注:即每个 LAB 都有自己的一组专用的 R4 互连驱动左右的逻辑块)。R4 互连可以通过垂直方向上的 C4 和 C16 (译注:垂直方向上,以 column 的形式跨越 4 个 LAB ,故名 C4,column 4)互连将信号传播到不同的行。此外,C4 还可以通过 R24 互连,有效地进行信号的长距离传输。
R8 互连结构上与 R4 互连相同,不同在于跨越 8 个而不是 4 个逻辑块,并且 R8 只能连接到 R8 和 C8 互连。根据设计,单个 R8 互连比两个 R4 互连连接在一起的速度更快。以此类推,R24 互连提供了最快的远距离信号传输。R24 同样与 R4 和 R8 互连结构类似,但不与 LAB 本地互连结构直接连接。R24 只与每 4 个 LAB 连接的行或者列互联结构连接,因此,只能通过 R4 和 C4 互联与 LAB 本地互连进行通信。R24 与除 L8 (译注:R8?)外的所有互连结构连接。
在列方向,即垂直维度上,连线资源与行方向非常相似。包括直接连接的 LUT 链(LUT chain)和寄存器链(FF chain),以及长度为 4、8 和 16 单位的互连结构,分别从上至下连接 4、8 或 16 个逻辑块。
在垂直方向的路由资源中,LUT 链和寄存器链起到了水平方向中的本地互联的作用。LUT 链将一个 LE 的组合输出直接连接到其下方的那个 LE 的快速输入端口,无需使用通用布线资源。寄存器链将一个 LE 的寄存器输出连接到另一个 LE 的寄存器输入,以实现快速移位寄存器。
最后,尽管本节的讨论以 LAB 为中心进行,但是所有的逻辑块都使用类似于 LAB 本地连接的接口直接连接到 MultiTrack 的行与列互联结构。同时,这些接口也支持其他逻辑块与相邻 LAB 的直接相连,进行快速通信。
1.5.2 Xilinx Virtex II Pro
Xilinx Virtex II Pro FPGA 在 Altera Stratix 之后推出与出货,是 Xilinx 在 2002 年和 2003 年的大部分时间里的旗舰产品。本节提供的信息大部分改编自 Xilinx Virtexii Pro 2005 年 10 月版 Virtex II Pro X™ 平台FPGA手册 的第二章(功能描述)(可从 http://www.xilinx.com 网站获取)。
Virtex-II Pro 也是一种基于 SRAM 的岛式 FPGA,具有多个通过复杂路由矩阵互连的异构计算单元。基本逻辑块是可配置逻辑块(configurable logic block,CLB),包括 4 个 slice (译注:slice 中包括 LUT 以及 FF)和 2 个三态输出缓存。片上的 CLB 以行和列的阵列形式在器件上展开,并通过分段、分层互连将所有资源连接在一起。专用存储块,SelectRAM+(译注:该名称现已不再使用,存储块在 7 系列中就朴实地叫 BRAM,Ultrascale 系列增加了 ultra BRAM),分布于整个器件的各个位置。此外,由专用的 18×18 位乘法器块提供额外的计算资源。
逻辑架构
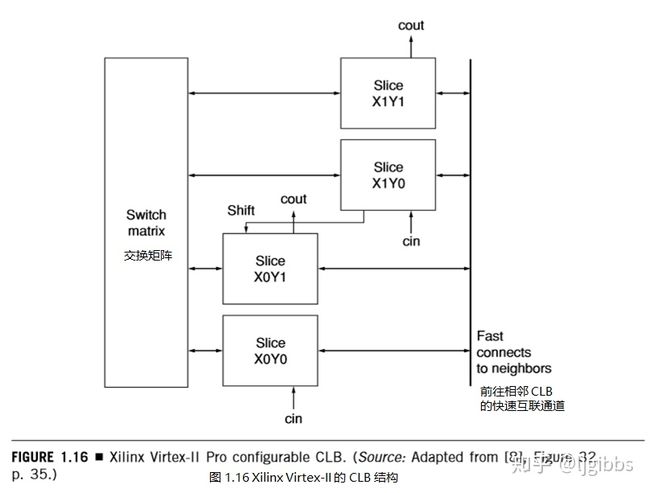
从互连结构的角度来看,最小的逻辑单位是 CLB。其结构如图 1.16 所示,由四个相同的 slice 组成(译注:7 系列中 CLB 由两类 slice 组成,详情可查阅 7 系列架构手册),呈两列分布,每列有独立的进位链和一个公共的移位链。每个 slice 通过可配置的交换机矩阵连接至通用路由结构,并通过快速本地互连与 CLB 中的其他 slice 相连接。
每个 slice 主要包括两个 4-LUT 函数生成器、两个用于保持逻辑状态的可编程寄存器、快速进位链。此外还包括额外的多路复用器(MUXFx 和 MUXF5),允许将 slice 配置为最多 8 输入的选择器。一些 slice 中的其他逻辑门提供了额外的功能,包括一个用于在单个 slice 上完成 2 位全加器的异或门,用于提高 slice 中乘法器实现性能的与门,以及用于实现乘积累加链的或门。
在最大的 Virtex II Pro 器件 XC2VP100 中,有 120 行和 94 列 CLB 的阵列。相当于 44096 个独立 slice 和 88192 个 4-LUT,与最大容量的 Stratix 器件相当。除了这些通用可配置的逻辑资源外,Virtex II Pro 还提供 SelectRAM+ 形式的专用 RAM 块。其在整个器件中被组织成多个列结构,每个块 SelectRAM+ 提供18 Kb 时钟独立的、真双端口同步 RAM。它支持多种配置,包括各种位宽/大小比的单端口或双端口 RAM。在最大的器件中,有 444 个SelectRAM+ 块,组织为 16 列,共 8183808 bit 存储空间。
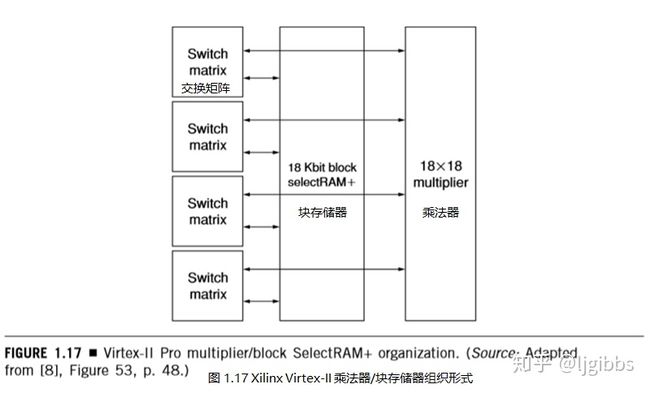
补充通用逻辑资源的是 18×18 位二进制补码有符号乘法器块。与 Altera Stratix 中的 DSP 块一样,这些乘法器结构是为 DSP 类型的运算而设计的,包括 FIR、IIR、FFT 等,这些运算通常需要乘法累加结构。每个 18×18 乘法器块都与一个 18Kb 的块 SelectRAM+ 直接相连,如图 1.17 所示。乘法器/块 SelectRAM+ 存储器相连的结构,配合基于 LUT 的累加器,可以实现高效的乘法累加结构。同样,在 Virtex II Pro 最大容量的器件中,与 block SelectRAM+ 一样,有 16 列产生总共 444 个 18×18 位乘法器块。
最后,Virtex II Pro 具有一个已经被应用到新产品中的独特功能,也同样可以在竞争对手 Altera 的产品线中找到。(译注:那有什么独特的呢。。译者猜测这里的独特指的是 Xilinx 使用 PowerPC 硬核,而 Altera 以软核为主?并不确定)与乘法器和块 SelectRAM+ 结构类似,Xilinx 在 FPGA 芯片中嵌入了多达四个 IBM PowerPC405-D5 cpu 核心。这些核心最高工作频率可达 300MHz 以上,并通过专用接口逻辑与周围的 CLB 结构、block SelectRAM+和通用互连结构进行通信。片上存储器(Onchip Memory ,OCM)控制器允许 PowerPC 核心在没有片外存储器的情况下,使用片上块 SelectRAM+ 作为指令和数据存储器。
完整并标准化的处理器的存在,使在单个 FPGA 上实现独特的片上系统成为可能,因为处理器可以在底层与 FPGA 的其他逻辑资源进行通信。例如,CPU 核心可以执行既不是时间关键的,也不适合在 LUT 中实现的内部控制任务。
互联架构
Xilinx Virtex II Pro 提供了一个分段的、分层的路由结构,通过一个交换矩阵块连接到异构的逻辑资源。布线资源(主动互连)在物理上分布于交换逻辑块之间,水平和垂直两个方向上,看起来与 Altera Stratix 互连结构截然不同。

图 1.18 显示了任意两个相邻交换矩阵行或列之间可用的路由资源,交换矩阵块以黑色显示。这些布线资源在图中自上而下包括:
- 24 条跨越器件高和宽两条边的长走线。
- 120 条 hex 线,在所有四个方向上,连接相隔距离为三或者六的逻辑块。
- 40 条 double 线,从四个方向上,连接相隔距离为 2 的逻辑块。
- 16 条直连路线,通往所有邻近的逻辑块(9 邻近)。
- 每个 CLB 中连接 LUT 输入和输出的 8 条快速连接线。
1.6 总结 Summary
本章介绍了 FPGA 的基本工作原理。具体地,我们介绍了查找表计算的基本思想,说明了应用对专用计算逻辑的需求,并描述了常见的逻辑块间互连策略。我们学习了这些器件如何保持通用性和可编程性的同时,通过专用硬件逻辑块提供性能。我们研究了许多编程和存储用户定义配置信息的方法。最后,我们将理论与两个流行的商业架构联系起来,分别是 Altera Stratix 和 Xilinx Virtex II Pro 架构。
现在我们已经介绍了可重构计算的基础技术,之后我们将开始基于 FPGA 建立可编程器件与系统。以下章节将讨论如何有效地利用空间进行并行计算,而不是顺序地进行,以及将用户特定设计转换到配置数据所需的算法。最后,我们将研究一些成功利用可重构计算能力的应用领域。
参考文献 References
[1] J. Rose, A. E. Gamal, A Sangiovanni-Vincentelli. Architecture of field-programmable gate arrays. Proceedings of the IEEE 81(7), July 1993.
[2] P. Chow, et al. The design of an SRAM-based field-programmable gate array—Part 1: Architecture. IEEE Transactions on VLSI Systems 7(2), June 1999.
[3] H. Fan, J. Liu, Y. L. Wu, C. C. Cheung. On optimum switch box designs for 2-D FPGAs. Proceedings of the 38th ACM/SIGDA Design Automation Conference (DAC), June 2001.
[4] ———-. On optimal hyperuniversal and rearrangeable switch box designs. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 22(12), December 2003.
[5] H. Schmidt, V. Chandra. FPGA switch block layout and evaluation. IEEE International Symposium on Field-Programmable Gate Arrays, February 2002.
[6] Xilinx, Inc. Xilinx XC4000E and XC4000X Series Field-Programmable Gate Arrays, Product Specification (Version 1.6), May 1999.
[7] Altera Corp. Altera Stratix™ Device Handbook, July 2005.
[8] Xilinx, Inc. Xilinx Virtex-II Pro™ and Virtex-II Pro™ Platform FPGA Handbook, October 2005.