CV笔记03:自监督GAN(ss-gan)
无需标注数据,利用辅助性旋转损失的自监督GANs,-- 对抗+自监督的无监督方式

《通过辅助旋转损失进行的自监督GAN》CVPR 2019
论文速看
0.摘要
- 目前自然图像合成主要是条件GAN,但是其缺点是需要标注数据。
- 我们利用两种流行的无监督学习技术,
对抗训练和自我监督,并朝着缩小有条件GAN和无条件GAN之间的差距迈出了一步。 - 我们允许网络在代表学习的任务上进行协作,同时相对于经典GAN博弈具有对抗性。
- 自监督的作用是鼓励鉴别器学习在训练过程中不会忘记的有意义的特征表示。
- 做了实验,我们的东西很牛逼。
1.介绍
- GAN是无监督生成模型。
- 训练GAN具有挑战性,通常使用交替的随机梯度下降训练,该下降通常不稳定并且缺乏理论上的保证。
- 训练不稳定的一个主要因素是生成器和判别器在非平稳环境中学习,随着样本分布的变化,鉴别器会发生遗忘。
- 调节以便生成器和鉴别器都可以访问标记的数据。在监督信息的基础上增加鉴别器,会鼓励鉴别器学习更稳定的表示法,以防止灾难性遗忘。
- 我们的目标是表明人们可以在不需要标签数据的情况下恢复调节的好处。 为了确保判别器学习到的表示更加稳定和有用,我们向判别器添加了辅助的,自我监督的损失。
- 我们介绍了一种新颖的模型-
自我监督GAN-在这种模型中,生成器和鉴别器在表示学习的任务上进行协作,并在生成任务上进行竞争。
贡献:
我们提出了一种将对抗训练与自我监督学习相结合的无监督生成模型。 我们的模型恢复了条件GAN的优势,但不需要标记数据。 特别是,在相同的训练条件下,自我监督的GAN弥补了无条件模型与有条件模型之间自然图像合成的空白。 在这种情况下,鉴别器表示的质量将大大提高,这在迁移学习的背景下可能会引起另外的关注。 该模型的大规模实施在无条件IMAGENET生成上产生了可喜的结果,这一任务被认为是艰巨的。 我们认为,这项工作是朝着高质量,完全无监督的自然图像合成方向迈出的重要一步。
6.结论和展望
- 从解决判别器遗忘出发,我们提出了一种将对抗性学习和自我监督学习相结合的深度生成模型。 可以在图像合成任务上匹配等效的条件GAN,而无需访问标记的数据。
有监督、无监督、自监督
这三个监督都比较常见,但容易搞混
机器学习的常用方法,主要分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。
有监督(有人教),无监督(没人教)
监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。在人对事物的认识中,我们从孩子开始就被大人们教授这是鸟啊、那是猪啊、那是房子啊,等等。我们所见到的景物就是输入数据,而大人们对这些景物的判断结果(是房子还是鸟啊)就是相应的输出。当我们见识多了以后,脑子里就慢慢地得到了一些泛化的模型,这就是训练得到的函数,从而不需要大人在旁边指点的时候,我们也能分辨的出来哪些是房子,哪些是鸟。监督学习里典型的例子就是KNN、SVM。
无监督学习(也有人叫非监督学习)则是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中很多处都用到了无监督学习。比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么叫做朦胧派,什么叫做写实派,但是至少我们能把他们分为两个类)。无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
自监督学习(self-supervised learning)可以被看作是机器学习的一种“理想状态”,模型直接从无标签数据中自行学习,无需标注数据。
(1) 自监督学习的核心,在于如何自动为数据产生标签。例如输入一张图片,把图片随机旋转一个角度,然后把旋转后的图片作为输入,随机旋转的角度作为标签。再例如,把输入的图片均匀分割成3*3的格子,每个格子里面的内容作为一个patch,随机打乱patch的排列顺序,然后用打乱顺序的patch作为输入,正确的排列顺序作为label。类似这种自动产生的标注,完全无需人工参与。
(2) 自监督学习如何评价性能?自监督学习性能的高低,主要通过模型学出来的feature的质量来评价。feature质量的高低,主要是通过迁移学习的方式,把feature用到其它视觉任务中(分类、分割、物体检测…),然后通过视觉任务的结果的好坏来评价。目前没有统一的、标准的评价方式。
(3) 自监督学习的一个研究套路。前面说到,自监督学习的核心是如何给输入数据自动生成标签。之前的很多工作都是围绕这个核心展开的。一般的套路是:首先提出一个新的自动打标签的辅助任务(pretext task,例如:旋转图片、打乱patch顺序),用辅助任务自动生成标签,然后做实验、测性能、发文章。每年都有新的辅助任务被提出来,自监督学习的性能也在不断提高,有的甚至已经接近监督学习的性能。总体上说,或者是提出一种完全新的辅助任务,或者是把多个旧的辅助任务组合到一起作为一个“新”的辅助任务。
论文解读
主要idea
利用辅助损失解决GAN不稳定的问题;用旋转分类将辅助分类器对label的需求去掉,使图片可以直接对自己标注类别。

判别器的遗忘
判别器可以看作是一个简单的分类器,区分出真、假两种类型。为了实现这个目的,直觉上,判别器必须很好的理解输入图片。具体来说,判别器需要学会如何从输入图片中提取出好的feature,帮助其完成分类任务。
实际上,GAN这种独特的训练模式,对判别器来说,不是很友好。由于生成器在训练过程中在不断地更新,导致判别器的输入,也在不断的更新。对于不同分布的输入图片,判别器可能会学出来不同的策略来提取feature。例如,假设生成器刚开始只学会了如何生成总体轮廓结构为真的sample(细节纹理还没学会),此时判别器可能只会从轮廓结构方面对真假进行判断。随着训练的不断进行,生成器不断的更新,不同时刻的可能偏重的重点不一样,导致生成的图片的分布不一样,最后导致判别器提取feature的策略可能也不一样。
从判别器的角度来看,它要不断地“忘掉”已经学到的提取feature的方法,不断地学习新的提取feature的方法。似乎也不能完全怪判别器,因为在旧分布图片集上学到的feature提取方法,在新分布图片集上,可能已经不再适用了, 所以只能“忘掉”。这可能是GAN不稳定的一个重要原因。
作者做的两个实验也很有意思,清晰明了。

第一个实验分别用不同迭代时刻的判别器作为feature提取器,在ImageNet上训练一个分类器,比较判别分类器的性能,实验结果如上图。
蓝色表示GAN的测试结果,绿色表示添加了自监督学习任务的方法。从实验结果可以看出,从500k开始,蓝色表示的判别器似乎开始“健忘”,性能也开始下降。说明判别器学到的feature提取方法很不稳定。
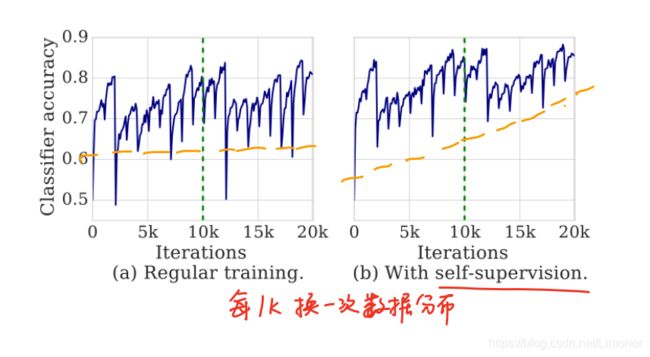
第二个实验在CIFAR10上训练一个分类器,训练的时候,依次用CIFAR10中的10个类来训练,每个类训练1k个iterations。左图表示GAN的测试结果,右图表示添加了自监督学习任务的方法。
从左边的实验结果可以看出,每次训练图片的类型发生变化时,分类器的性能明显下降。10k个iterations后,看上去像是从头开始学习,之前学到的方法好像已经全部“忘掉”了。
所以我们要解决判别器遗忘这件事,就有了将辅助手段添加到GAN中引导判别器的训练。解决的思路是让判别器有记忆,或者说去影响判别器的训练过程。
网络结构
自监督背后的主要思想是预测旋转图像的角度或者相关图像块的位置,然后从结果网络提取表征。
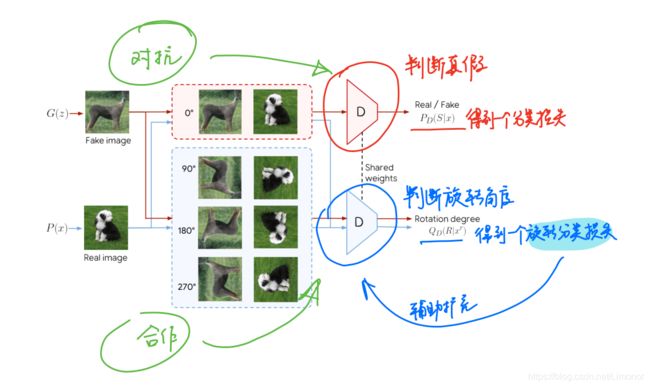
作者采用了基于图像旋转的自监督学习方法。此方法主要将图像旋转,然后将图像旋转的角度作为人工标注。如上图,红色判别器的任务和普通的GAN模型中的一样,判断图片来自真实数据还是生成器生成的假数据,得到一个分类损失 P D ( S ∣ x ) P_D(S\mid x) PD(S∣x) 。蓝色判别器的任务是将不同旋转角度的图片进行分类,真和假的图片都会被旋转90°, 180°, 270°,得到一个旋转分类损失 Q D ( R ∣ x r ) Q_D(R\mid x^r) QD(R∣xr) 。
具体操作是取Discriminator倒数第二层的输出,作为feature,加上一个Linear层,预测出旋转的类型。
合作对抗训练
该模型最大的特点是在表征学习(旋转角度分类任务)上让判别器和生成器协同,在判断True/Fake任务上又让二者回归原始的GAN中进行对抗。
首先生成器生成的图像是直立的,也就是0°的图像,这些图像之后会被旋转送入判别器。这样做是为了使生成器生成的图像更加偏向真实图像,以便于在旋转之后更容易判断出旋转角度。然后,判别器判别旋转角度时,只使用真实图片。换句话说,判别器的参数更新只基于真实数据的旋转分类损失。这样做也是为了使生成器生成的图像在旋转之后更易于检测。结果就是,生成器生成的图片非常有利于旋转检测,因为生成的图片和真实的图片共享特征,它们都有适用于旋转检测的特征。
在实际的操作中,作者利用了单一判别器网络,它包括两个部分来计算分类损失 P D ( S ∣ x ) P_D(S\mid x) PD(S∣x) 和旋转分类损失 Q D ( R ∣ x r ) Q_D(R\mid x^r) QD(R∣xr) 。所有的图片一共有四个角度,**没有经过旋转的图片用于让判别器判断真假;而经过旋转的图片用于让判别器判断旋转角度。**生成器的目标是生成能与观测图像匹配的图像,这些观测图像的在特征空间的判别器的表征是能够用来检测旋转角度。
当 α > 0 \alpha >0 α>0 时,对于真实数据分布下的 P G = P d a t a P_G=P_{data} PG=Pdata 的收敛是不能保证的,但是呢,在训练期间,将 α \alpha α 退火接近 0 是能得到保证。
损失函数
对于真假训练的value function不变:
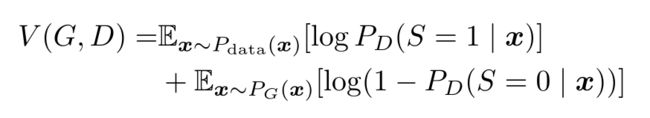
V ( G , D ) V(G,D) V(G,D) 也就是原始GAN函数。
而在此基础上,作者增加了分类判别器(也就是旋转判别器):
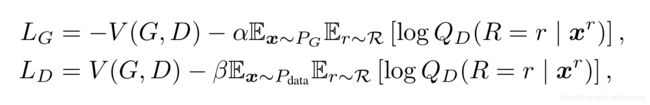
r r r 代表旋转角度,包括0,90,180,270, x r x^r xr 代表图像 x x x 的旋转角度。
代码
GitHub地址:https://github.com/zhangqianhui/Self-Supervised-GANs
这篇论文是采用tf 1.版本写的,淘汰的地方跳过。
项目核心就是Model.py这个程序,在Model.py程序中,一共就只定义了一个SSGAN的类,但足足有500多行。
class SSGAN(object):
# 定义一堆参数
def __init__(self, flags, data):
pass
# 定义一些loss
def build_model_GAN(self):
pass
# 计算精确度
def Accuracy(self, pred, y):
pass
# 判别器loss
def loss_dis(self, d_real_logits, d_fake_logits):
pass
# 由角度旋转图像
def Rotation_by_R_label(self, image, r):
pass
# 打印出所有旋转角度的图像
def Rotation_ALL(self, images):
pass
# 生成器loss
def loss_gen(self, d_fake_logits):
pass
# hinge loss 铰链损失(判别器)
def loss_hinge_dis(self, d_real_logits, d_fake_logits):
pass
# 铰链损失(生成器)
def loss_hinge_gen(self, d_fake_logits):
pass
# KL散度
def kl_loss_compute(self, logits1, logits2):
pass
# 已有训练好的模型,进行测试
def test2(self):
pass
# 整个训练过程
def train(self):
pass
# 定义判别器,输出一个sigmoid结果
def discriminate(self, x_var, resnet=False, reuse=False):
pass
# 定义生成器,一层层卷积激活函数,最后tanh出来
def generate(self, z_var, batch_size=64, resnet=False, is_train=True,
reuse=False):
pass
def _init_inception(self):
pass
定义判别器的函数部分,可以看出生成器和判别器都是在tf.variable_scope空间作用域里面创建的
def discriminate(self, x_var, resnet=False, reuse=False):
"""
x_var代表输入,discriminate()函数被应用在build_model_GAN()中,其输入值为输入图片
resnet是作者定义的一个布尔值,表示是否使用残差架构
reuse是tensorflow中为了节约变量存储空间,通过共享变量作用域(variable_scope)来实现共享变量的方式
"""
print x_var.shape
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables() # 如果重复使用变量,创建独立的空间
if resnet == False: # 如果不使用残差结构
# 现在基本用leakyRelu挺广泛的
conv1 = lrelu(conv2d(x_var, spectural_normed=self.sn,
iter=self.iter_power, output_dim=64,
kernel=3, stride=1, name='dis_conv1_1'))
conv2 = lrelu(conv2d(conv1, spectural_normed=self.sn,
iter=self.iter_power,
output_dim=128, name='dis_conv2_2'))
conv3 = lrelu(conv2d(conv2, spectural_normed=self.sn,
iter=self.iter_power,
output_dim=256, name='dis_conv3_2'))
conv4 = lrelu(conv2d(conv3, spectural_normed=self.sn,
iter=self.iter_power,
output_dim=512, kernel=1, name='dis_conv4'))
# num_rotation是旋转角度(0,90,180,270)
# 把conv4 reshape成[batch数*旋转角度,-1] -1占位符
conv4 = tf.reshape(conv4, [self.batch_size*self.num_rotation, -1])
#for D
# 计算出全连接的一个输出gan_logits
gan_logits = fully_connect(conv4, spectural_normed=self.sn,
iter=self.iter_power,
output_size=1, scope='dis_fully1')
if self.ssup: # 如果使用自监督学学习
rot_logits = fully_connect(conv4, spectural_normed=self.sn,
iter=self.iter_power,output_size=4,
scope='dis_fully2')
rot_prob = tf.nn.softmax(rot_logits)
else: # 使用残差结构
# 用自己定义的残差块函数配置
re1 = Residual_D(x_var, spectural_normed=self.sn, output_dims=128,
residual_name='re1', down_sampling=True, is_start=True)
re2 = Residual_D(re1, spectural_normed=self.sn, output_dims=128,
residual_name='re2', down_sampling=True)
re3 = Residual_D(re2, spectural_normed=self.sn, output_dims=128,
residual_name='re3')
re4 = Residual_D(re3, spectural_normed=self.sn, output_dims=128,
residual_name='re4')
re4 = tf.nn.relu(re4)
# gsp
# 以axis=[1, 2]来减少re4的张量
gsp = tf.reduce_sum(re4, axis=[1, 2])
gan_logits = fully_connect(gsp, spectural_normed=self.sn,
iter=self.iter_power,
output_size=1, scope='dis_fully1')
if self.ssup: # 使用残差+使用自监督学习
rot_logits = fully_connect(gsp, spectural_normed=self.sn,
iter=self.iter_power,
output_size=4, scope='dis_fully2')
rot_prob = tf.nn.softmax(rot_logits)
#tf.summary.histogram("logits", gan_logits)
if self.ssup: # 自监督返回sigmoid(gan_logits), gan_logits, rot_logits, rot_prob
return tf.nn.sigmoid(gan_logits), gan_logits, rot_logits, rot_prob
else: # 非自监督返回sigmoid(gan_logits), gan_logits
return tf.nn.sigmoid(gan_logits), gan_logits
生成器和判别器都用到自己的残差块
def Residual_G(x, output_dims=256, kernel=3, strides=1, spectural_normed=False,
up_sampling=False, residual_name='resi'):
with tf.variable_scope('residual_{}'.format(residual_name)):
def short_cut(x):
x = upscale(x, 2) if up_sampling else x
return x
x = tf.nn.relu(batch_normal(x, scope='bn1'))
conv1 = upscale(x, 2) if up_sampling else x
conv1 = conv2d(conv1, output_dim=output_dims,
spectural_normed=spectural_normed,
kernel=kernel, stride=strides, name="conv1")
conv2 = conv2d(tf.nn.relu(batch_normal(conv1, scope='bn2')),
output_dim=output_dims,
spectural_normed=spectural_normed,kernel=kernel,
stride=strides,
name="conv2")
resi = short_cut(x) + conv2 # 关键的加法
return resi
def Residual_D(x, output_dims=256, kernel=3, strides=1, spectural_normed=True,
down_sampling=False, residual_name='resi', is_start=False):
with tf.variable_scope('residual_{}'.format(residual_name)):
def short_cut(x):
x = avgpool2d(x, 2) if down_sampling else x
x = conv2d(x, output_dim=output_dims, spectural_normed=spectural_normed,
kernel=1,
stride=1, name='conv')
return x
if is_start:
conv1 = tf.nn.relu(conv2d(x, output_dim=output_dims,
spectural_normed=spectural_normed,
kernel=kernel,
stride=strides, name="conv1"))
conv2 = tf.nn.relu(conv2d(conv1, output_dim=output_dims,
spectural_normed=spectural_normed,
kernel=kernel,
stride=strides, name="conv2"))
conv2 = avgpool2d(conv2, 2) if down_sampling else conv2
else:
conv1 = conv2d(tf.nn.relu(x), output_dim=output_dims,
spectural_normed=spectural_normed, kernel=kernel,
stride=strides,
name="conv1")
conv2 = conv2d(tf.nn.relu(conv1), output_dim=output_dims,
spectural_normed=spectural_normed, kernel=kernel,
stride=strides,
name="conv2")
conv2 = avgpool2d(conv2, 2) if down_sampling else conv2
resi = short_cut(x) + conv2
return resi
总结
这篇文章不难,主要是思路独特清晰,利用图片自身旋转代替分类,再用这个分类损失辅助GAN解决GAN训练的问题,非常巧妙。
一些启发
自监督学习是一类方法的总称,其主要目的是通过解决替代的任务来学习高维的语义表征。广泛的应用在视频领域、机器人领域和图像领域。例如有论文提出通过旋转图像来预测其旋转角度,这种方法看上去简单但是却能产生有用的表征,比如由上往下的图像分类任务上。
除了能试着预测旋转角度,还可以编辑给定的图像和要求网络去预测被编辑的部分。还有其他的替代的任务,包括图像修复、通过一张灰度图像预测颜色通道和预测监督的聚类。最近还有通过现代神经结构进行自监督学习。
同时作者指出对一些工作能起到促进的作用,首先使用最好的自监督结构应用在判别器上,并且优化取得可能更好的表征,其次自监督GAN可以应用在半监督条件下,可以用小部分的标注数据用于微调模型。最终可能应用一下的方法,在非条件图像生成中,比如使用自注意力,正交正则化和规范化和采样截断来取得更好的表现。
小补充:为什么简简单单的旋转就这么有用呢?
站在我们人类的角度,我们看到这张图片,我们能一眼分辨出这是旋转0度的直立的图片。

因为我们理解图片,我们知道下面是地,上面蓝色的是天,树是直立得长在地上的,所以我们能判断出他的旋转角度。
这样,我们让机器去学习去判断,当模型能够判断出它的旋转角度,说明它的feature map包含了丰富的图片语义信息,也就是说,模型能看懂图片了。

旋转角度,只是一种标签数据的形式。预测旋转角度,只是一种手段。