11-redis哨兵:redis哨兵主备切换的数据丢失问题:异步复制、集群脑裂
1、哨兵的介绍
sentinal,中文名是哨兵
哨兵是redis集群架构中非常重要的一个组件,主要功能如下
(1)集群监控,负责监控redis master和slave进程是否正常工作
(2)消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
(3)故障转移,如果master node挂掉了,会自动转移到slave node上
(4)配置中心,如果故障转移发生了,通知client客户端新的master地址
哨兵本身也是分布式的,作为一个哨兵集群去运行,互相协同工作
(1)故障转移时,判断一个master node是宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题
(2)即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身是单点的,那就很坑爹了
目前采用的是sentinal 2版本,sentinal 2相对于sentinal 1来说,重写了很多代码,主要是让故障转移的机制和算法变得更加健壮和简单
-
哨兵的核心知识
(1)哨兵至少需要3个实例,来保证自己的健壮性
(2)哨兵 + redis主从的部署架构,是不会保证数据零丢失的,只能保证redis集群的高可用性
(3)对于哨兵 + redis主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练
-
为什么redis哨兵集群只有2个节点无法正常工作?
哨兵集群必须部署2个以上节点
如果哨兵集群仅仅部署了个2个哨兵实例,quorum=1(quorum=1:设置选举数,有1个哨兵认为master宕机,则进行故障转移操作)
+----+ +----+
| M1 |---------| R1 |
| S1 | | S2 |
+----+ +----+
Configuration: quorum = 1
master宕机,s1和s2中只要有1个哨兵认为master宕机就可以还行切换,同时s1和s2中会选举出一个哨兵来执行故障转移
同时这个时候,需要majority,也就是大多数哨兵都是运行的,2个哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2个哨兵都运行着,就可以允许执行故障转移
但是如果整个M1和S1运行的机器宕机了,那么哨兵只有1个了,此时就没有majority来允许执行故障转移,虽然另外一台机器还有一个R1,但是故障转移不会执行
-
经典的3节点哨兵集群
+----+
| M1 |
| S1 |
+----+
|
+----+ | +----+
| R2 |----+----| R3 |
| S2 | | S3 |
+----+ +----+
Configuration: quorum = 2,majority
如果M1所在机器宕机了,那么三个哨兵还剩下2个,S2和S3可以一致认为master宕机,然后选举出一个来执行故障转移
同时3个哨兵的majority是2,所以还剩下的2个哨兵运行着,就可以允许执行故障转移
redis哨兵主备切换的数据丢失问题:异步复制、集群脑裂
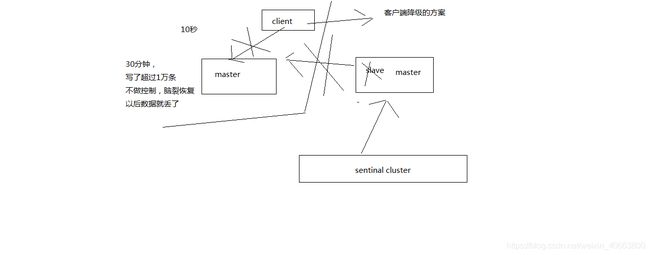
1、两种数据丢失的情况
主备切换的过程,可能会导致数据丢失
- (1)异步复制导致的数据丢失
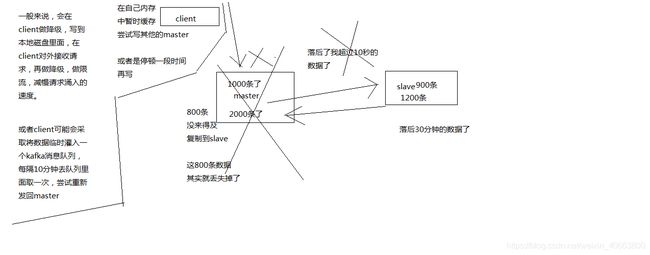
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了
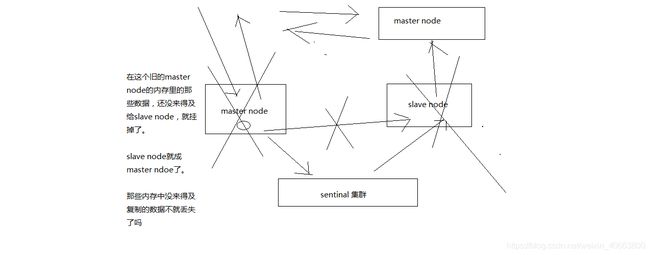
- (2)脑裂导致的数据丢失
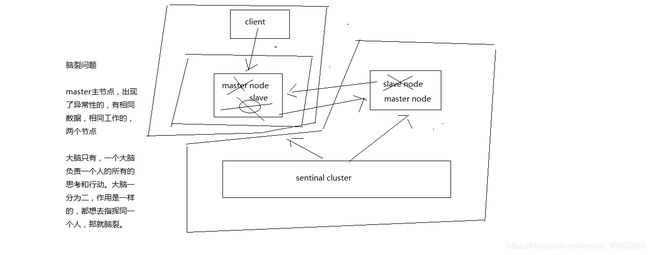
脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着
此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master
这个时候,集群里就会有两个master,也就是所谓的脑裂
此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了
因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据
2、解决异步复制和脑裂导致的数据丢失
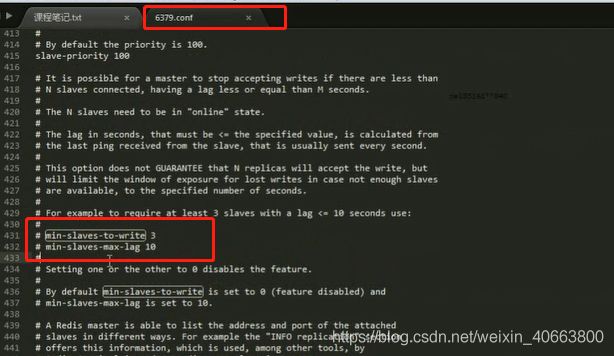
# 在redis的主节点的配置文件中进行配置
min-slaves-to-write 1
min-slaves-max-lag 10 两个参数的意思:
要求至少有1个slave,数据复制和同步的延迟不能超过10秒
如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了
上面两个配置可以减少异步复制和脑裂导致的数据丢失
- (1)减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内
- (2)减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求
这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失
上面的配置就确保了,如果跟任何一个slave丢了连接,在10秒后发现没有slave给自己ack,那么就拒绝新的写请求
因此在脑裂场景下,最多就丢失10秒的数据