Python爬取大量英雄联盟壁纸(多线程,小白版)
爬取链接
代码
import requests
import threading
import shutil
import re
import os
class myThread(threading.Thread):
def __init__(self,word,page,urls,down_localhost):
threading.Thread.__init__(self)
self.word=word
self.page=page
self.urls=urls
self.down_localhost=down_localhost
def run(self):
self.down_localhost = self.down_localhost + '\\' + word + str(self.page)
if not os.path.exists(self.down_localhost):
os.makedirs(self.down_localhost)
for url in self.urls:
download(readUrlTwo(url), self.down_localhost)
print("第%s页 下载成功" % self.page)
def readUrlOne(url):
pattern = re.compile(r'', re.S)
results = re.findall(pattern, requests.get(url).text)
return results
def readUrlTwo(url):
pattern = re.compile(r') , re.S)
response = requests.get(url);
results = re.search(pattern, response.text)
return results.group(1)
def download_jpg(image_url,image_localhost):
response=requests.get(image_url,stream=True)
if response.status_code==200:
with open(image_localhost,'wb') as f:
response.raw.deconde_content=True
shutil.copyfileobj(response.raw,f)
def download(url,path):
filename=os.path.basename(url)
imgpath=os.path.join(path,filename)
print("开始下载 %s"%url)
download_jpg(url,imgpath)
print("下载完成 %s"%url)
down_loaclhost='E:\BaiduNetdiskDownload';
word=input('输入下载内容')
word1 = re.sub('\s', '%20', word)
number=input('输入现在页数')
number=int(number)
for page in range(1,number+1):
url = 'https://wallhaven.cc/search?q=' + word1 + '&page=' + str(page);
urls=readUrlOne(url)
thread=myThread(word,page,urls,down_loaclhost)
thread.start()
, re.S)
response = requests.get(url);
results = re.search(pattern, response.text)
return results.group(1)
def download_jpg(image_url,image_localhost):
response=requests.get(image_url,stream=True)
if response.status_code==200:
with open(image_localhost,'wb') as f:
response.raw.deconde_content=True
shutil.copyfileobj(response.raw,f)
def download(url,path):
filename=os.path.basename(url)
imgpath=os.path.join(path,filename)
print("开始下载 %s"%url)
download_jpg(url,imgpath)
print("下载完成 %s"%url)
down_loaclhost='E:\BaiduNetdiskDownload';
word=input('输入下载内容')
word1 = re.sub('\s', '%20', word)
number=input('输入现在页数')
number=int(number)
for page in range(1,number+1):
url = 'https://wallhaven.cc/search?q=' + word1 + '&page=' + str(page);
urls=readUrlOne(url)
thread=myThread(word,page,urls,down_loaclhost)
thread.start()
运行截图
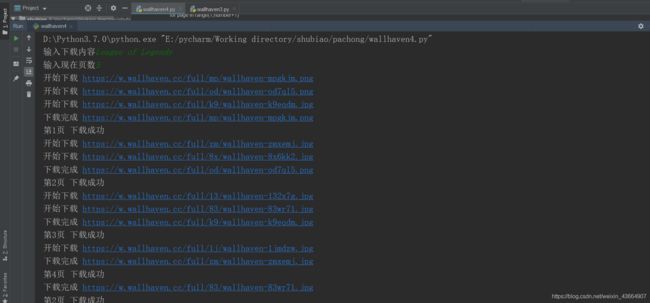
爬取几页就是几个线程,暂时没有设置线程最大数,后期会涉及实现。