基于PyQt5的网络工具
介绍
事情是这样的,我在刷网络安全题的时候,发现有一些题目是要发送POST请求到URL,我在网上查了一下关于POST请求的发送方法,发现大都是要我用什么hackbar。但我这人闲的慌,就用Python随便写了个小脚本完成了题目。然后我就想,写一个GUI界面的工具,这样就用起来更舒服(说白了就是贱的慌)。然后在我简单的把请求工具写出来后,又手欠写了几个小功能。
下载地址
CSDN:https://download.csdn.net/download/realmels/16867516
建议先下载源代码,以配合下文。
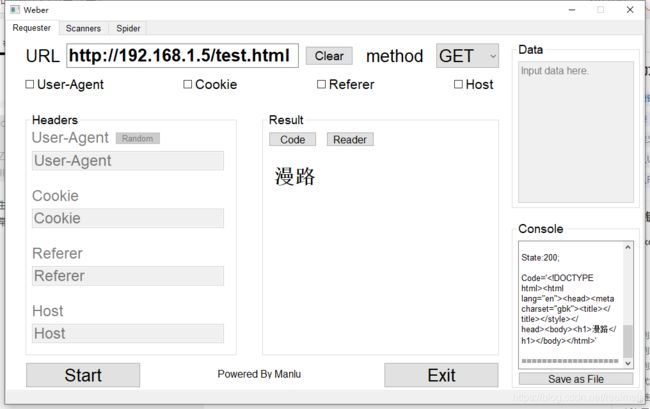
界面设置
这边我是用PyQt5做的项目,所以GUI绘制用的是designer,设计出来的界面大概就是这个样子
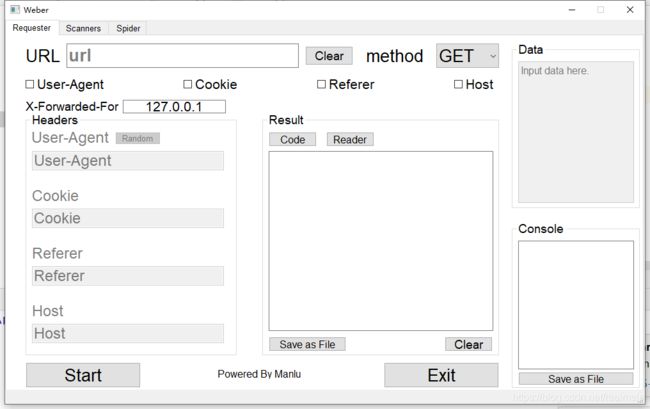
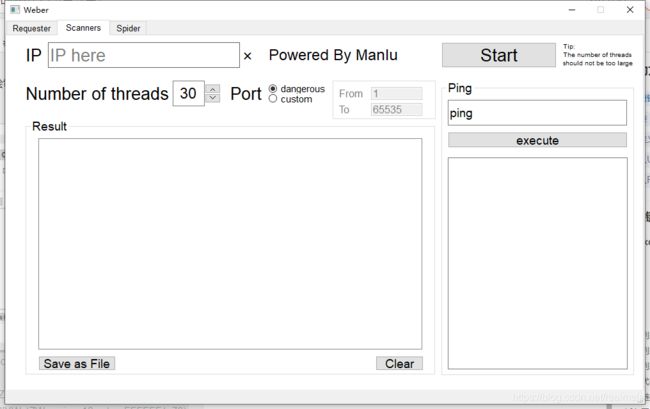
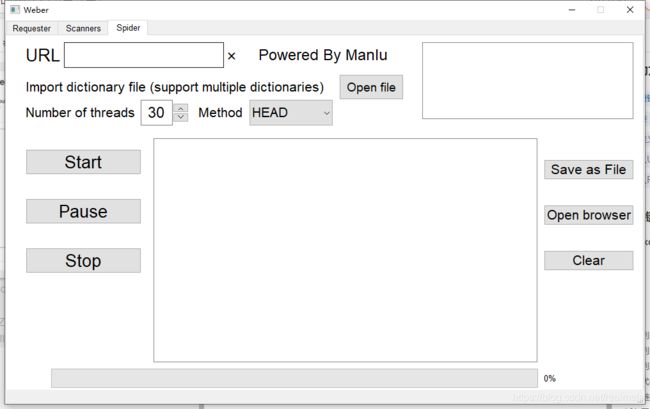
界面的绘制方法在我的博客里讲的很清楚,可以自行学习,同时在源代码中也有 .ui文件,里面是我的详细布局
布局完成之后用PyUIC工具将其转换为 .py文件,项目结构大概就是这样
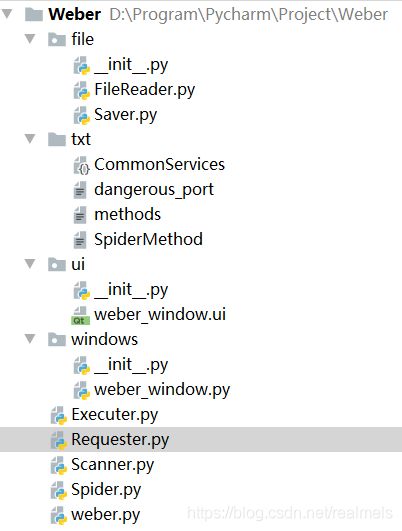
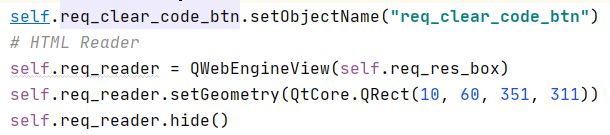
还有一个很重要的事情,在weber_window.py文件中的
self.req_clear_code_btn.setObjectName("req_clear_code_btn")
下一行,加上以下代码
self.req_reader = QWebEngineView(self.req_res_box)
self.req_reader.setGeometry(QtCore.QRect(10, 60, 351, 311))
self.req_reader.hide()
大概就是这样
此时在QWebEngineView那里,显示找不到,导入即可
![]()
以上操作在我上传的源代码中已完成
前置准备
这里用到了非常多的第三方库,建议创建一个文件,然后将以下内容放进去完成下载。
创建文件install.bat
pip install PyQt5 -i https://mirrors.aliyun.com/pypi/simple/
pip install pyqt5-tools -i https://mirrors.aliyun.com/pypi/simple/
pip install PyQtWebEngine -i https://mirrors.aliyun.com/pypi/simple/
pip install fake_useragent -i https://mirrors.aliyun.com/pypi/simple/
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
pip install pywin32 -i https://mirrors.aliyun.com/pypi/simple/
保存之后双击运行,等待下载完成即可
代码讲解
我的源代码大多通俗易懂,结构比较分明,但开发过程中踩了很多坑,还是要拉出来讲一下
编码
在开发过程中最让我头痛的就是编码问题了,读文件需要编码,请求网页要编码,保存文件还要编码。但关于编码问题的解决,网络上的资料大都牛头不对马嘴。

先看爬虫的
位置 ./Requester.Requester
请求网页的结果,如果是以text直接返回内容,很容易出现编码不一致导致的乱码问题

这肯定不行,我在网络上查找了解决方法,居然找到了

请求结果的apparent_encoding属性可以获取网站的编码,先获取二进制数据再进行解码,就可以获取到网页的正常内容
代码如下
r = requests.get(self.url, headers=self.headers, timeout=3)
text = r.content.decode(r.apparent_encoding)
此外关于文件读取的编码问题,在网络上找的方法大都是要我修改文件的编码或用某个第三方库来实现。但是那个第三方库效率低,准确率还低,所以我经过简单的思考,获取文件的二进制数据,再使用常见的编码依次尝试,尝试成功没有报错的即为正确的编码
> 位置 ./file/FileReader.getEncoding
代码
self.encodings=['utf-8','utf-16','gbk','gb2312','ansi']
def getEncoding(self,data):
available=[]
for encoding in self.encodings:
try:
data.decode(encoding)
except UnicodeDecodeError:
pass
else:
available.append(encoding)
if len(available)>=1:
return available[0]
else:
return "Not Found"
在实际开发过程中,有时文件会出现两种编码都匹配的情况,所以这边获取可用编码的列表,将列表的第一项返回
命令执行
在Scanner界面中,有一个执行ping指令的位置,在这边可以使用ping来获取远程主机的存活程度。
在代码中我写了一个QThread子类用于实现命令执行,关于QThread会在下文讲到。命令的执行我原本用的是os模块的popen方法,但在exe的打包过程中发现会报错。在网上查了资料说是popen方法接受的是一个输入流,而无控制台的窗口没有输入流的接收,就会爆出错误。
根据网上的方法,将其封装成一个函数,调用底层进行命令执行。同时还要将返回的文本解码。
位置 ./Executer.Executer.execute_cmd()
关于编码的获取,我还是选择用我已经封装好的getEncoding方法
代码
def execute_cmd(self,cmd):
proc = subprocess.Popen(
cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
stdin=subprocess.PIPE
)
proc.stdin.close()
proc.wait()
text = proc.stdout.read()
encoding=FileReader().getEncoding(text)
result=text.decode(encoding)
proc.stdout.close()
return result
多线程
在PyQt5中的多线程,需要用到QThread模块
关于QThread的使用,有两种方法,第一种就是写一个类,继承QObject对象,将要用的函数写进去,再通过moveToThread方法运行。
我习惯使用第二种方法,写一个类,继承QThread,在里面写上我的函数。
例如在我的命令执行位置,我就使用到了QThread。
位置
./Executer.Executer
./weber.Weber.execute_cmd()
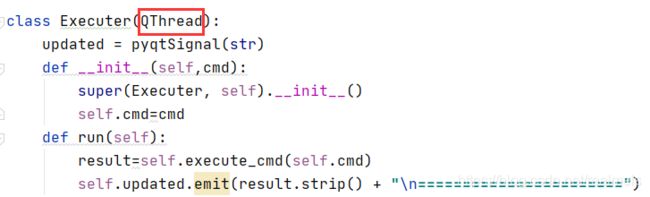
在run函数中是我线程开始后执行的方法,updated用于将线程执行结果与界面交互。
在我的weber.py的命令执行函数位置,有这样的代码
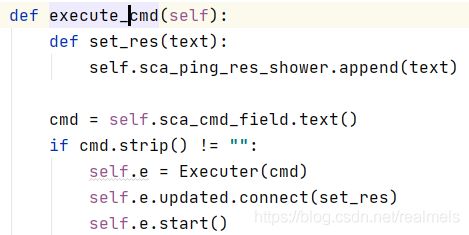
在这里,connect后面连接我的函数,函数的参数就是emit的内容,通过start方法开始线程。这样,在程序运行时,不会因为函数的运行而导致内容卡死。
emit方法虽然比较好用,但我有时还会用另一种方法
位置
./Scanner.ScanThread
./weber.Weber.scan_port()

在这里我传入了一个参数叫做shower,直接将扫描结果放到shower中

在weber.py中
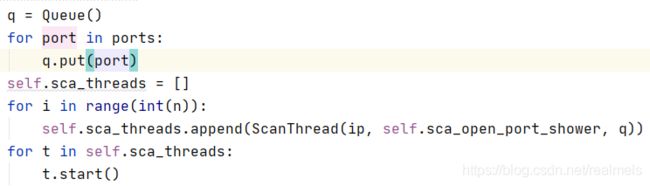
但是注意,如果是QTextEdit的append方法,不能用这种方法,必须使用emit方法。不要问,问就是我也不知道。
端口扫描
端口扫描的原理非常简单,创建一个tcp的socket套接字,绑定ip和端口,尝试连接,连接成功则为开放,连接失败则说明端口关闭。
在扫描时加入多线程可以加快扫描的速度。
位置
./Scanner.ScanThread
./weber.Weber.scan_port()
我在主程序中创建了多个线程,并创建了一个队列,不断从队列中取出端口,进行快速扫描。
目录扫描
在程序中实现了目录扫描的功能。
位置
./Spider.Spider
./weber.Weber.crawl_directory()
原理:导入目录字典,与url拼接,使用爬虫依次访问获取请求状态码,不为404则目录存在。
在这边我使用Head方法可能会更快。
QThread的暂停和关闭
这个问题属实是困扰我很久,在Spider界面中有暂停和停止的功能,可以暂停爬取或者退出爬取。我试图在网上找方法,试了很多方法,都没有太靠谱的,只有线程的关闭找到一个有用的实例,而关闭线程的原理我现在还不知道。
位置
./Spider.Spider.run()
./weber.Weber.pause_crawl()
./weber.Weber.stop_crawl()
关于线程的暂停,我没有找到好的方法,但我是在Spider类中定义了一个变量名为flag,用来反应当前线程的工作状态。0爬取;1暂停;2销毁。
我在check方法中存在对flag判断的代码
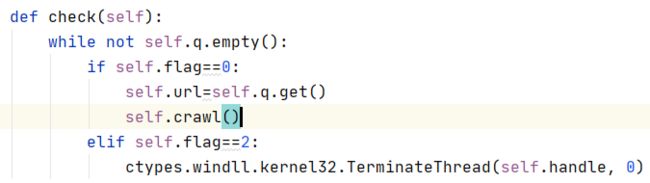
如果flag为1,则进行爬取,如果为2,则销毁自身。这边销毁的代码我也不知道原理是什么,但是有效就行。
在weber.py中,有这样的代码
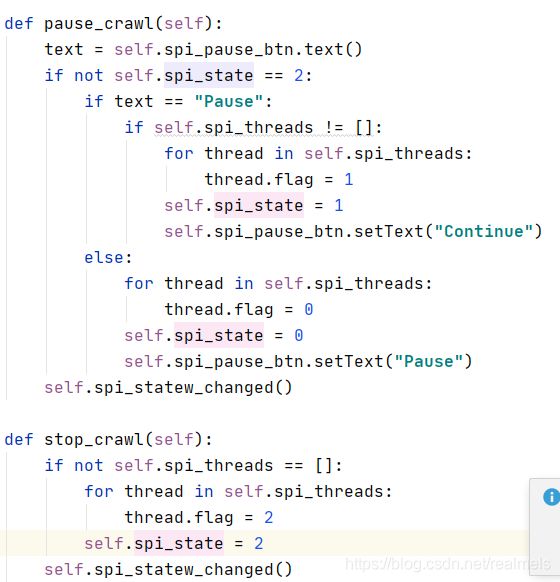
按钮的按下只能改变线程对象的flag,通过flag线程自身做出行动。