爬虫数据解析与提取
爬虫数据解析与提取
- 前言
- 正则表达式
-
- 语法列表
- 语法案例
- Xpath规则运用
-
- xpath规则
- Xpath谓语条件(Predicates)
- xpath轴
- CSS选择器规则与运用
-
- BeautifulSoup4模块
- JsonPath规则与运用
- json规则
- python中运行js
- 内容不全,暂不想写
前言
进行爬虫数据解析与提取方法

- 爬虫数据四大解析规则:正则表达式规则、Xpath规则、CSS选择器规则、JsonPath规则
- 前端的三大语法:HTML、CSS、JavaScript
正则表达式
语法列表
- 普通字符语法
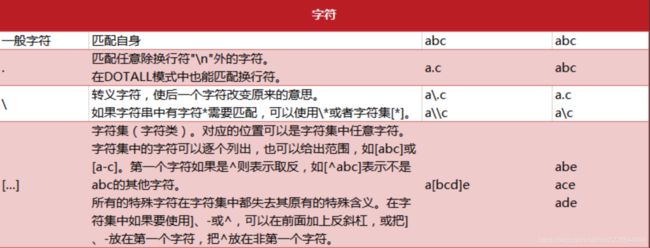
- 预定义字符集语法

- 数量词语法


- 边界匹配语法

- 逻辑分组语法

- 特殊构造语法

语法案例
import re
# re.match(表达式语法, 匹配的字符串)
"**** 1.1 一般字符 ****"
pattern = "python"
re.match(pattern, "python") # python
re.match(pattern, "python2.7") # python
"**** 1.2 . 万能匹配字符 ****"
pattern = "python."
re.match(pattern, "python2") # python2
re.match(pattern, "python3") # python3
re.match(pattern, "python3.7") # python3
re.match(pattern, "python\n") # None (无法匹配)
re.match(pattern, "python\n", re.S) # python\n
"**** 1.3 \ 正则转义字符 ****"
pattern = "\.\*\?\+\^\$"
re.match(pattern, ".*?+^$abcd") # .*?+^$
# 匹配一个反斜线字符\
# 字符串中表示单个反斜线
len("\\") # 1
pattern = "\\\\" # 正则中表示单个反斜线
re.match(pattern, "\\") # \
# r作用:将字符串转为纯正则模式,忽略字符串对其的干扰
pattern = r"\\" # 正则中表示单个反斜线
re.match(pattern, "\\") # \
"**** 1.4 中括号字符集里的特殊符号将失去所有特殊含义,除了\ ****"
pattern = "[.*?+^$]"
re.match(pattern, "*")
re.match(pattern, "$")
# 但当位于首位的^、作为连字符的-、]具备单独的含义
re.match("[a-z]", str1) # 只匹配小写字母
re.match("[^a-z]", str2) # 只匹配非小写字母
re.match("[\^a-z]", str3) # 只匹配以小写字母或^
re.match("[a\-z]","-") # 只匹配a、-、z 这三个字母
re.match("[\]]","]") # 只匹配"]"
#---------------------------------------
re.match("\d+\.\d{2,6}", "3.1415926") # 3.141592
re.match("\d+\.\d{2,6}?", "3.1415926") # 3.14
#---------------------------------------
# \b相当于\w和\W的边界,可以用来匹配出单词;\B则常用来判断单词的连贯性
re.match(r"\w\W\w", "q q") # q q
re.match(r"\w\b\W\b\w", "q q") # q q
re.match(r"\w+\b\W+\b\w+", "hello-world") # hello-world
re.match(r"\w+\b\W+\b\w+", "hello - -- -world") # hello - -- -world
# 注意:必须使用r,将字符串变为正则模式,因为\b在普通字符串中也是具有含义的
re.match(r"Tom\B[A-Z][a-z]+", "TomCruise") # 可以匹配
re.match(r"Tom\B[A-Z][a-z]+", "Tom Cruise") # 无法匹配
#---------------------------------------
"**** 6.1 (?aiLmsux) 作用:替换flags参数 ****"
re.match(r"(?i)ABCD", "abcd") # abcd
re.match(r"ABcd", "abcd", flags=re.I) # abcd
"**** 6.2 (?:...) 作用:进行匹配,但不计入分组 ****")
re.match(r"(ab)(cd)", "abcd").group(1) # ab
re.match(r"(?:ab)(cd)", "abcd").group(1) # cd
"**** 6.3 (?imsx-imsx:...) 作用:为组内设置或去除flags效果 ****"
# Python3.6新增正则语法
re.match(r"(?i:AB)cd", "abcd") # abcd
re.match(r"(?-i:AB)cd", "abcd", flags=re.I) # 无法匹配
re.match(r"(?s-i:AB)cd", "abcd", flags=re.I) # 无法匹配
# 注意不能在内部即开启又关闭同一模式,如:i-i、imsx-imsx都是错误的
"**** 6.4 (?#...) 作用:添加注释 ****")
re.match(r"(?#这是注释)abcd", "abcd")
"**** 6.5 (?=...) 作用:向右正向断言匹配,后面如果是 ****"
# 后面如果是cd就匹配
re.match(r"\w+(?=cd)", "abcd") # 可以匹配 abcd
re.match(r"\w+(?=cd)", "abcf") # 无法匹配
"**** 6.6 (?!...) 作用:向右反向断言匹配,后面如果不是 ****"
# 后面如果不是cd就匹配
re.match(r"ab(?!cd)\w+", "abcd") # 无法匹配
re.match(r"ab(?!cd)\w+", "abcf") # 可以匹配 abcf
"**** 6.7 (?<=...) 作用:向左正向断言匹配,前面如果是 ****"
# 前面如果是ab就匹配
re.match(r"\w+(?<=ab)cd", "abcd") # 可以匹配 abcd
re.match(r"\w+(?<=ab)cd", "afcd") # 无法匹配
"**** 6.8 (?
# 后面如果不是ab就匹配
re.match(r"\w+(?, "abcd") # 无法匹配
re.match(r"\w+(?, "afcd") # 可以匹配 afcd
"**** 6.9 (?(id/name)yes-pattern|no-pattern) 作用:如果给定组存在,则使用yes规则,否则使用no规则 ****")
re.match(r"(<){0,1}abcd(?(1)>|)", "" ) # 可以匹配 ) # 无法匹配
re.match(r"(<){0,1}abcd(?(1)>|)", "abcd") # 可以匹配 abcd
python正则模块
re模块
Xpath规则运用
xpath学习文档
xpath规则

Xpath谓语条件(Predicates)
函数调用
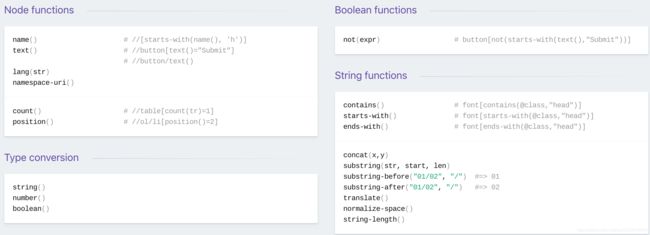
运算操作

索引操作

链式谓语

嵌套谓语

xpath轴


CSS选择器规则与运用
css选择器
BeautifulSoup4模块
bs4文档
JsonPath规则与运用

- pip install jsonpath
json规则
jsonpath基础语法

jsonpath运算符

jsonpath函数(Python中jsonpath模块暂不支持该语法)

- jsonpath数据解析: Python中使用jsonpath模块时,必须将json字符串转换为python内置对象,如对象–>字典,数组–>列表。 因为python中需要使用json.loads或load方法将json数据进行简单转换。
python中运行js
Python中执行JS代码,通常两个库: js2py、pyexecjs
import js2py
js2py.eval_js('console.log( "Hello World!" )')
# 'Hello World!'
func_js = '''
function add(a, b) {
return a + b
}
'''
add = js2py.eval_js(func_js)
print(add(1,2))
# 3