python数据分析与挖掘实战---5.1.4 决策树:ID3算法
ID3算法简介及基本原理
ID3算法基于信息嫡来选择最佳测试属性。它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少不同取值就将样本集划分为多少子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的拆分,从而得到较小的决策树。
设S是s个数据样本的集合。假定类别属性具有m个不同的值:C(i = 1,2…,m)。设s
是类C中的样本数。对一个给定的样本,它总的信息嫡为。
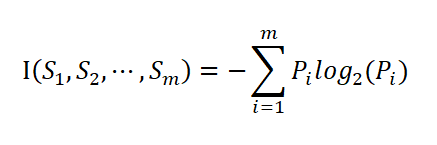
其中,Pi是任意样本属于Ci的概率,一般可以用。估计。
设一个属性A具有k个不同的值{a₁,a₂,···,ak},利用属性A将集合S划分为个子集{S₁,
S₂,···,Sa},其中S包含了集合S中属性A取a值的样本。若选择属性A为测试属性,则这些
子集就是从集合S的节点生长出来的新的叶节点。设Sij是子集Sj中类别为Ci的样本数,则
根据属性A划分样本的信息嫡值为
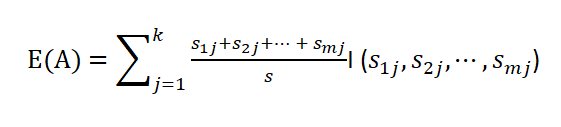
其中,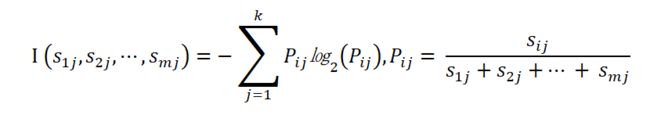
是子集Sj中类别为Ci的样本的概率。
最后,用属性A划分样本集S后所得的信息增益(Gain)为
Gain(A) = I(s₁,s₂,···,s_m) - E(A)
挺懵的,看例子先好了
餐饮案例
T餐饮企业作为大型连锁企业,生产的产品种类比较多,另外涉及的分店所处的位置也不同,数目比较多。对于企业的高层来讲,了解周末和非周末销量是否有大的区别,以及天气、促销活动这些因素是否能够影响门店的销量等信息至关重要。因此,为了让决策者准确了解和销量有关的一系列影响因素,需要构建模型来分析天气、是否周末和是否有促销活动对销量的影响,下面以单个门店为例来进行分析。
对于天气属性,数据源中存在多种不同的值,这里将那些属性值相近的值进行类别整合。如天气为“多云”,“多云转晴”,“晴”这些属性值相近,均是适宜外出的天气,不会对产品销量有太大的影响,因此将它们归为一类,天气属性值设置为“好”。同理,对于“雨”,“小到中雨”等天气,均是不适宜外出的天气,因此将它们归为一类,天气属性值设置为“坏”。
对于是否周末属性,周末则设置为“是”,非周末则设置为“否”。
对于是否有促销活动属性,有促销则设置为“是”,无促销则设置为“否”。
产品的销售数量为数值型,需要对属性进行离散化,将销售数据划分为“高”和“低”两类。将其平均值作为分界点,大于平均值的划分到类别“高”,小于平均值的划分为“低”类别。
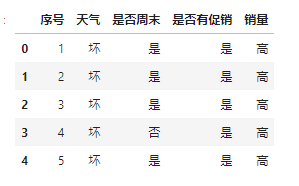
采用ID3算法构建决策树模型的具体步骤如下。
-
根据公式(5-5),计算总的信息嫡。其中,数据中总记录数为34,而销售数量为“高”的数据有18,“低”的有16。

-
根据公式(5-5)和(5-6),计算每个测试属性的信息嫡。
对于天气属性,其属性值有“好”和“坏”两种。其中,天气为“好”的条件下,销售数量为“高”的记录为11,销售数量为“低”的记录为6,可表示为(11,6)﹔天气为“坏”的条件下,销售数量为“高”的记录为7,销售数量为“低”的记录为10,可表示为(7,10)。
则天气属性的信息嫡计算过程如下。
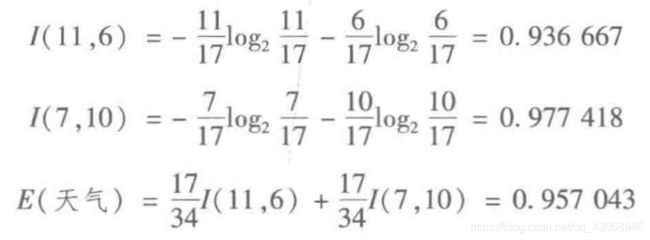
对于是否周末属性,其属性值有“是”和“否”两种。其中,是否周末属性为“是”的条件下,销售数量为“高”的记录为11,销售数量为“低”的记录为3,可表示为(11,3);是否周末属性为“否”的条件下,销售数量为“高”的记录为7,销售数量为“低”的记录为13,可表示为(7,13)。则节假日属性的信息嫡计算过程如下。
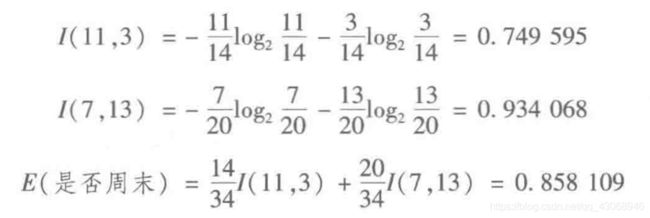
对于是否有促销属性,其属性值有“是”和“否”两种。其中,是否有促销属性为“是”的条件下,销售数量为“高”的记录为15,销售数量为“低”的记录为7,可表示为(15,7);其中,是否有促销属性为“否”的条件下,销售数量为“高”的记录为3,销售数量为“低”的记录为9,可表示为(3,9)。则是否有促销属性的信息嫡计算过程如下。

根据公式(5-7),计算天气、是否周末和是否有促销属性的信息增益值。

-
到此我是否可以认为简介中的S是总数据,s是行数,C代表例子中建立模型的目标属性"销量",前面对数据进行了处理,"销量"的值只有“高”,“低”,属性A是数据属性或者说数据列名
已知模型结果

经过第一轮之后是否周末选为了测试属性,得到“是”,“否”两个子样本集,其中,
”否“子集中:
天气属性,其中,天气为“好”的条件下,销售数量为“高”的记录为5,销售数量为“低”的记录为6,可表示为(5,6)﹔天气为“坏”的条件下,销售数量为“高”的记录为2,销售数量为“低”的记录为7,可表示为(2,7)。则天气属性的信息嫡计算过程如下
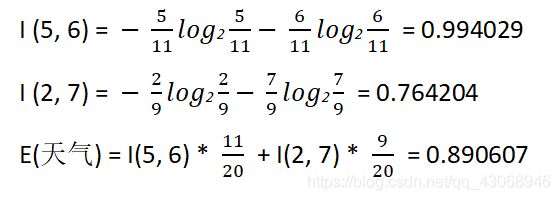
否有促销属性,其中,是否有促销属性为“是”的条件下,销售数量为“高”的记录为6,销售数量为“低”的记录为6,可表示为(6,6);其中,是否有促销属性为“否”的条件下,销售数量为“高”的记录为1,销售数量为“低”的记录为7,可表示为(1,7)。则是否有促销属性的信息嫡计算过程如下。
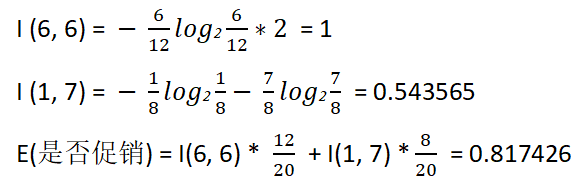
数据总量为20,销售数量为”高“的数据有7,为”低“的数据有13
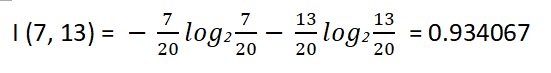
计算天气和是否有促销属性的信息增益值。

同理计算其他叶节点(手算麻烦,不算了。。。)
代码实现
import pandas as pd
from sklearn import tree
data = pd.read_excel('./chapter5/data/sales_data.xls')
data.head()
# 数据是类别标签,将它转换成数据:用1表示‘好’‘是’‘高’,-1表示‘坏’‘否’‘低’
data.set_index('序号', inplace = True)
data[data == '好'] = 1
data[data == '是'] = 1
data[data == '高'] = 1
data[data != 1] = -1
x = data.iloc[:, :3].values.astype(int)
y = data.iloc[:, 3].values.astype(int)
源代码是使用as_matrix函数,在0.23.0版本不能使用了,改为values
AttributeError: ‘DataFrame’ object has no attribute ‘as_matrix’
dtc = tree.DecisionTreeClassifier(criterion = 'entropy') # 建立决策树模型,基于信息熵
dtc.fit(x, y)
with open('tree.dot', 'w') as f:
#f = tree.export_graphviz(dtc, feature_names = x.columns, out_file = f)
fig, ax = plt.subplots(figsize = (12,8))
tree.plot_tree(dtc, feature_names = data.columns, ax =ax, ) # sklearn 0.23版本自带了决策树的可视化方法
源代码是用的GraphViz,需要装软件

可以看到”是否周末的”熵值“是0.998,符合上面的计算
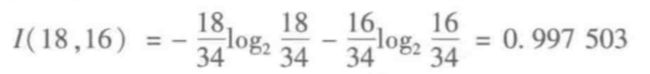
然后周末“否”子集的“熵值”是0.934,和我自己手算结果一致

看来方法没错