基于多特征地图和深度学习的实时交通场景分割
https://www.toutiao.com/a6623529829402673667/
2018-11-14 09:58:33
Ⅰ.介绍
交通场景分割是智能车辆在检测障碍物、规划路径和自主导航中的基本任务。语义分割,也称为图像分析或图像理解[1],旨在将图像划分为预定义的非重叠区域并将其转换为抽象语义信息。近年来,随着计算机硬件特别是图形处理单元(GPU)的快速发展,大规模标记数据的出现,深度卷积神经网络(CNNs)在图像分类和目标检测中的应用迅速发展,并已成为当前主流的图像分割方法。最近,大多数研究都致力于通过使网络更深更广来提高语义分割的准确性。然而,增加参数往往以牺牲计算机的内存为代价,并导致网络速度较慢。因此,如何在保证实时功能的前提下提高准确性是深度学习中最重要的任务之一。
深度传感器的出现使得可以获得深度信息,其包含比RGB图像更多的位置信息。将深度图应用于图像语义分割有两种方法:一种是将原始深度图像和RGB图像组合成四通道RGB-D图像作为CNN输入[2] - [4];另一种是将包含更丰富深度信息和RGB图像的图像分别输入到两个CNN中[5] - [7]。具体地,借助于关于深度图像中提供的对象关系的丰富信息,两种方法都可以实现比仅使用RGB图像更好的性能。但是,将数据输入两个CNN会增加导致网络速度变慢的参数数量。因此,在本文中,为了提高精度,将视差、高度和角度图(DHA)与RGB图像融合成6通道RGB-DHA图并直接用作输入数据。
本文着重于构建一个性能良好的快速功能语义分割网络,特别是对于驾驶员更关心的道路目标。因此,提出了一种新的网络架构,然后添加深度图及其导出的高度和范数角度图来训练网络以获得更高的精度。主要工作如下:
- 一个名为D-AlexNet网络的完全卷积神经网络是基于AlexNet [8]开发的,它具有一个包含多个卷积层的简单结构,以提高网络的前向速度。
- D-AlexNet实现2.2x +参考加速,并将参数减少39倍以上。
- 6通道RGB-DHA地图可以在语义分割中获得比仅使用RGB图像作为输入更好的结果,尤其是用于识别交通场景中的道路目标,例如行人和汽车。
Ⅱ. 相关工作
A.RGB语义分割
完全卷积网络(FCN)[9]用卷积层替换传统神经网络的最后一个完全连接层,这为FCN应用于语义分割奠定了基础。由L.C.Chen等人提出的Deeplab [10]通过使用孔算法减小步幅和条件随机场来微调网络获得了更好的结果。 SegNet [11],[12]通过使用编码器 - 解码器结构从较高层恢复具有来自较低层的空间信息的特征图来实现像素级语义分割。在[13],[14]中,使用多尺度特征集合来提高性能。 PSPNet [15]通过聚合上下文信息来完成预测。
在现有硬件上实时执行分段。一些方法已被用于加速网络。 SegNet [12]通过减少网络中的层数来提高前向速度。 A. Chaurasia等。 [16]直接将编码器块链接到相应的解码器以减少处理时间。 Z. Hengshuang等[17] 提出了基于压缩PSPNet的图像级联网络,该网络在适当的标签指导下包含多分辨率分支,以产生实时推断。
B.具有深度信息的语义分割
与单个RGB图像相比,深度图包含更多位置信息,这有利于语义分割。在[18]中,原始深度图像被简单地视为单通道图像,然后应用CNN来提取室内语义分割的特征。在[5]中,深度信息被用作三个通道:水平视差、地面高度和范数角。Qi等人 [19]提出了一个3D图形神经网络(3DGNN),它建立了k-最近邻图,并最终提升了预测。上述工作证明,使用更多特征信息作为训练网络的输入有助于提高语义分割的准确性。
III.网络体系结构
一般而言,使用更深层的网络结构将得到更好的语义分割,尽管它通常以牺牲具有许多训练参数和更长的运行时间为代价,这不能满足智能驾驶的实时要求。为了直观地解决这个问题,我们认为减少网络参数和简化网络模型可以加速网络,而且,添加深度信息可以提高网络性能。由AlexNet [8]和N. Hyeonwoo [20]提出的基于VGG16网络的编码器 - 解码器网络架构的推动,我们提出的深度完全卷积神经网络架构如图1所示,包括11个卷积层、3个汇集层、3个上采样层和1个softmax层。
在新的网络结构中,AlexNet通过以下方式进行修改,使其适用于像素级语义分段任务:
- 为了使网络适应不同大小的图像,删除了AlexNet的完整连接层。然后,第一卷积层的步幅从4变为1,最大汇集层的内核大小从3×3变为2×2。
- 实验结果表明,卷积层中包结构的存在不能提高最终语义分割的准确性。因此,我们删除了第二、第四和第五卷积数据包并删除了两个LRN层。
- 内部协变量的存在将增加深度网络训练的难度。 本文在每个卷积层和ReLU层之间添加了批量归一化层来解决这个问题。
- 所有卷积层的卷积核被统一为3×3大小,卷积核输出的数量为96。
参考Z.D.Matthew等人使用的上采样方法[21],我们在汇集过程中记录每个汇集窗口的最大特征值位置,并将其置于上采样过程中的相应位置。解码器是编码器的镜像结构,除了其内核大小为1×1的第六个卷积层。解码器网络的输出是K个特征映射,然后将其馈送到softmax层以产生K通道类概率图,其中K是类的数量。分割的结果是图像的每个像素对应于具有最大预测概率的类。
Ⅳ.多特征地图
与使用原始深度信息学习深度网络相比,DHA图像可以包含更丰富的图像特征信息。该过程包括以下步骤。
A.水平视差图
从Cityscapes数据集获得的左图像和右图像可用于生成具有立体匹配算法的视差图。根据匹配程度,立体视觉匹配算法可以分为三类:局部匹配算法、半全局匹配算法和全局匹配算法。全局匹配算法获得最高的匹配精度和最差的实时性能。局部匹配算法是最快的,但其匹配精度非常低。
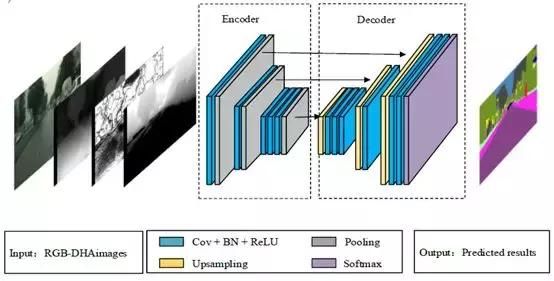
图1. D-AlexNet网络的结构
半全局匹配算法可以更好地匹配精度和实时计算需求,因此本文选择此方法来获取视差图。
M. Dongbo [22]提出的边缘保持平滑方法用于通过优化粗略视差图并使视差值更连续来提高分割精度。
B. 地面以上的高度
基于所获得的视差图,可以通过等式(1)和(2)获得对应于图像坐标系中的P'(u,v)像素的世界坐标系中的P(x,y,z)点,
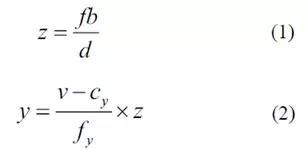
其中x和y是世界坐标系中点P的坐标,z是点P和相机之间的距离,f和b分别是摄像机的焦距和两个摄像机的基线长度,fy和Cy是相机的内部参数,y是像素的高度。由于摄像机的安装不能保证与地平面完全平行,因此需要进行校正。选择视差图中的地面区域的一部分,并且使用最小二乘法来拟合地面。通过假设拟合的地平面方程是Y = aX + bZ + c,a,b和c的值可以通过等式(3)获得。在校正地之后,可以通过等式(4)获得实际像素高度。
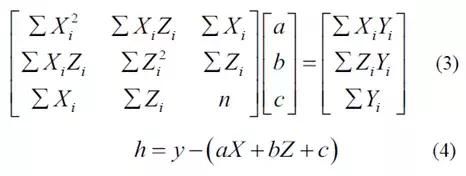
在高度图中,天空、建筑物和树对应于较大的高度值,而诸如车辆和行人的较重要的对象对应于相对较小的高度值。为了突出重要目标,使用等式(5)来变换对应于每个像素的高度值,以生成高度值在0到255之间的高度图像。
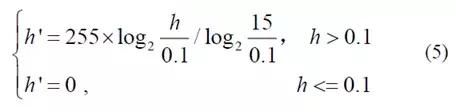
C.曲面法线
对于城市交通场景,一般来说,路面是水平的,物体的表面,如建筑物、交通标志、车辆等是垂直的。根据这些特征,可以使用算法在尽可能多的点上找到与局部估计的表面法线方向最对齐或最正交的方向。因此,为了利用这种结构,由G . Saurabh等人提出的算法[ 5 ]用于确定重力方向。
最后,通过计算像素法线方向和预测重力方向之间的角度,可以获得所需的角度信息。
V. 实验与分析
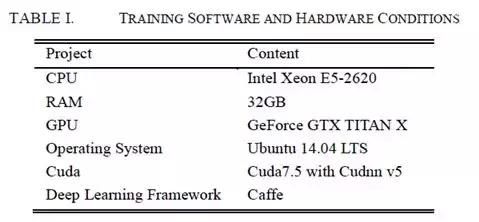
实验是在Caffe学习平台上进行的。此外,我们的所有实验都是在表I所示的软件和硬件上进行的。
A.数据集和评估指标
我们将我们的系统应用于最近的城市场景理解数据——城市风景,其中包含5000幅精细和20000幅粗注释图像。此外,数据集提供由立体相机捕获的左视图和右视图,从而提供获得视差图和深度图的机会。在这篇论文中,选择了5000幅经过精细注释的图像,并将其分成训练、验证和测试集。这些集合分别包含2,975,500和1,525幅图像。图像大小被转换为200×400,以缩短训练时间并减少内存消耗。为了标记重要的交通信息,交通场景分为11种类别包括道路、道路边界、建筑物、电线杆、交通标志、树木、草坪、天空、人、汽车、自行车或摩托车,全局准确率和网络转发时间都被用于评估。
B.训练过程
在训练过程中,卷积层的权重以与AlexNet相同的方式初始化,以及H.Kaiming等人使用的方法[23]用于初始化批量标准化层的重量。交叉熵被用作训练网络和计算损失值的损失函数。在反向传播阶段,采用随机梯度下降来优化网络权重。初始学习率和动量分别设定为0.01和0.9。另外,将重量衰减设定为0.0005以防止网络过度拟合。值得注意的是,为了保持数据的纯度并简化培训过程,我们在没有数据增加的情况下训练我们的网络,并且没有使用其他数据集的预训练模型。
对于每300个培训时间,我们对验证集进行了准确性评估并保存了快照。基于RGB-DHA图像的验证准确度,训练损失值曲线如图2所示。更多迭代可能意味着更高的准确度。但是,当准确度和损失开始收敛时,停止训练是可行的。因此,对网络进行了10000次迭代训练,选择具有最高精度的Caffe模型作为最终用于场景分割的模型。
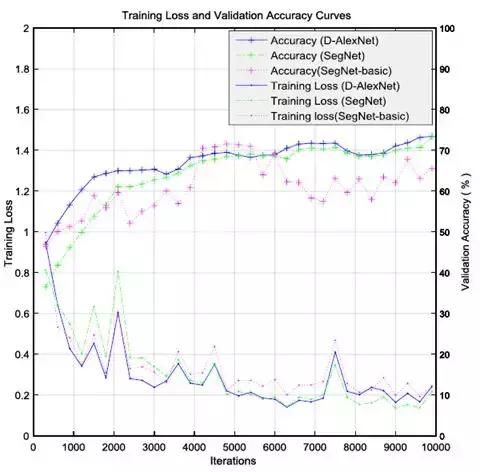
图2.不同网络的训练损失和准确度曲线。
C.比较和分析
我们首先评估了我们提出的网络如何有效地加速语义分割,将SegNet [11]和SegNet-basic [12]作为基线。当将RGB图像和RGB-DHA图像作为输入数据时,网络的性能结果如表II所示。我们提出的网络结构比SegNet快2.2倍,比SegNet-basic快1.8倍。从图2和表II中我们可以发现,我们提出的架构可以通过竞争性分段结果获得更好的实时结果。此外,对于每个网络帧,使用RGB-DHA图像获得的验证精度高于使用RGB图像获得的验证精度,这也表明更多特征信息对于改善网络性能是有用的。
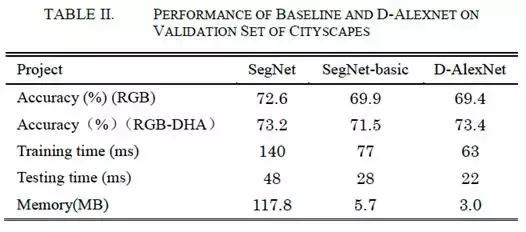
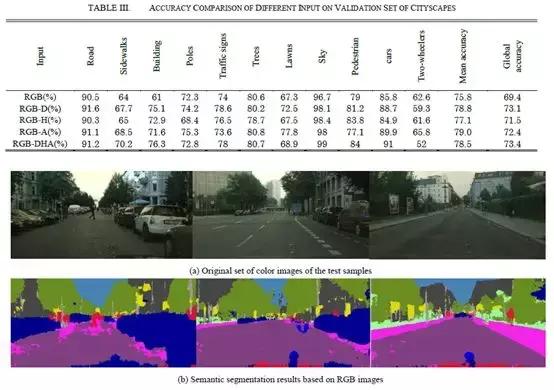
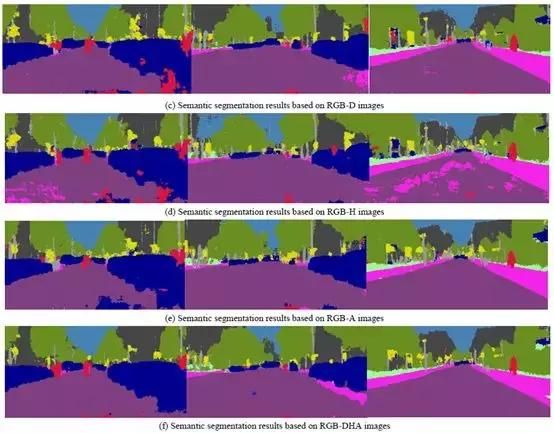
图3.测试集中的语义分段结果示例
了进一步了解每个特征图中的效率增益,我们首先将从第4节获得的三个特征图与RGB图像合并为4通道图像,然后将所有3个特征图像与RGB图像合并为6通道图像。之后,4通道和6通道图像都被用作训练网络的输入数据。测试结果如表Ⅲ所示,从中可以得出结论:与基于3通道图像的图像相比,基于4通道和6通道图像的分割精度明显提高。在相同的训练参数下,从RGB-D,RGB-H,RGB-A和RGB-DHA图像获得的全局精度比从原始RGB图像获得的全局精度分别为3.7%、2.1%、3%和4%。 以RDB-DHA 6通道图像为输入,我们提出的系统最终实现了73.4%的分割精度。
图3显示了我们的网络模型的测试集上的语义分段结果,分别以3通道,4通道和6通道作为输入。如图所示,基于RGB图像获得的分割结果有时是粗糙的,并且在道路上或在不同类别的边界轮廓周围存在许多错误分类的像素。例如,在图3(b)的左图中,路面中的许多像素被错误分类为人行道。基于四通道图像的效果通常比基于RGB三通道图像的效果更好,并且RGB-DHA图像可以进一步提高分割精度,其显示更少的错误分类点。
此外,当使用RGB-DHA图像作为净输入时,诸如行人和汽车的道路目标比使用RGB图像作为净输入具有更高的分段精度。例如,行人段准确度从79%上升到84%,汽车段精度从85.8%上升到91%。一些细节比较如图4所示。可以看出,图4(c)和图4(f)中的行人和汽车具有比图4(b)和图4(e)更清晰的轮廓,这将有助于不同道路目标的行为分析。
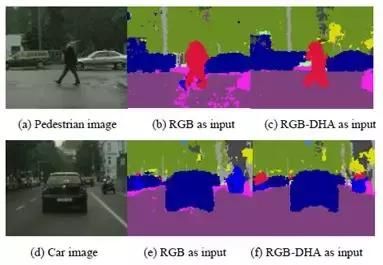
图4.行人和汽车的详细比较示例。
VI.结论
本文提出了一种基于新型深度完全卷积网络(D-AlexNet)和多特征映射(RGB-DHA)的交通场景语义分割方法。对于Titan X GPU上的每个400×200分辨率图像,网络可以实现22ms的良好实时性能。从原始RGB图像获得视差图、高度图和角度图,并融合成6通道图像以训练网络。实验表明,与使用RGB图像作为输入相比,使用多特征图作为网络的输入可以实现4%更高的分割精度。在未来,我们将重点关注更高效的深度网络,以联合语义分割,目标跟踪和参数识别。
致谢
作者要感谢郑仁成博士对富有成果的讨论所做的贡献。
REFERENCES
[1] W. Fan, A. Samia, L. Chunfeng and B.Abdelaziz, “Multimodality semantic segmentation based on polarization and colorimages,” Neurocomputing, vol. 253, pp. 193-200, Aug. 2017.
[2] L. Linhui, Q. Bo, L. Jing, Z. Weina andZ. Yafu, “Traffic scene segmentation based on RGB-D image and deep learning(Periodical style—Submitted for publication),” IEEE Transactions on IntelligentTransportation Systems, submitted for publication.
[3] F. David, B. Emmanuel, B. Stéphane, D,Guillaume, G. Alexander et al, “RGBD object recognition and visual texture classification for indoorsemantic mapping,” in IEEE International Conference on Technologies forPractical Robot Applications, Woburn, 2012, pp. 127-132.
[4] H. Farzad, S. Hannes, D. Babette, T.Carme and B. Sven, “Combining semantic and geometric features for object classsegmentation of indoor scenes,” IEEE Robotics & Automation Letters, vol. 2,no. 1, pp. 49-55, Jan. 2017.
[5] G. Saurabh, G. Ross, A. Pablo and M. Jitendra,“Learning rich features from RGB-D images for object detection andsegmentation,” Lecture Notes in Computer Science, vol. 8695 LNCS, no. PART 7,pp. 345-360, 2014.
[6] G. Yangrong and C. Tao, “Semanticsegmentation of RGBD images based on deep depth regression (Periodicalstyle—Submitted for publication),” Pattern Recognition Letters, submitted forpublication.
[7] E. David and F. Rob, “Predicting Depth,Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture,”in Proceedings of the IEEE International Conference on
Computer Vision, Santiago, Feb. 2015, pp.2650-2658.
[8] K. Alex, S. Ilya and H. E. Geoffrey,“ImageNet classification with deep convolutional neural networks,” Communicationsof the ACM, vol. 60, no. 6, pp. 84-90, June 2017.
[9] S. Evan, L. Jonathan and D. Trevor, “Fullyconvolutional networks for semantic segmentation,” IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 39, no. 4, pp. 640-651, Apr. 2017.
[10] L. C. Chen, G. Papandreou, I. Kokkinos,K. Murphy and A. L. Yuille, “Deeplab: semantic image segmentation with deep convolutional nets, atrousconvolution, and fully connected CRFs (Periodical style—Submitted forpublication),” IEEE Transactions on Pattern Analysis and Machine Intelligence,submitted for publication.
[11] V. Badrinarayanan, A. Handa and R.Cipolla. “Segnet: a deep convolutional encoder-decoder architecture for robustsemantic pixel-wise labelling,” Computer Science, May 2015.
[12] V. Badrinarayanan, A. Kendall and R.Cipolla, “Segnet: a deep convolutional encoder-decoder architecture for scenesegmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence,vol. 39, no. 12, pp. 2481-2495, Dec. 2017.
[13] F. Xia, P. Wang, L. C. Chen and A. L.Yuille, “Zoom better to see clearer: human and object parsing with hierarchicalauto-zoom net,” in European Conference on Computer Vision, Switzerland, 2016,pp.648-663.
[14] C. Liang-Chieh, Y. Yi, W. Jiang, X. Weiand Y. L. Alan, “Attention to scale: Scale-aware semantic image segmentation,”in Proceedings of the IEEE Computer Society Conference on Computer Vision and PatternRecognition, Las Vegas, July 2016, pp. 3640-3649.
[15] Z. Hengshuang, S. Jianping, Q. Xiaojuan,W. Xiaogang and J. Jiaya,“Pyramid scene parsing network,” in the IEEE Conference on ComputerVision and Pattern Recognition, Honolulu, 2017, pp. 2881-2890.
[16] A. Chaurasia, and E. Culurciello,“Linknet: exploiting encoder representations for efficient semanticsegmentation,” arXiv preprint arXiv: 1707.03718, 2017.
[17] Z. Hengshuang, Q. Xiaojuan, S. Xiaoyong,S. Jianping and J. Jiaya,“ICNet for Real-Time Semantic Segmentation on High-Resolution Images,”arXiv preprint, arXiv:1704.08545, 2017.
[18] H. Caner, M. Lingni, D. Csaba and C. Daniel.“FuseNet: Incorporating depth into semantic segmentation via fusion-based CNNarchitecture,” in 13th Asian Conference on Computer Vision, Taipei, Nov. 2016,vol. 10111 LNCS, pp. 213-228.
[19] Q. Xiaojuan, L.Renjie, J. Jiaya, F.Sanja and U. Raquel, “3D Graph Neural Networks for RGBD Semantic Segmentation,”in IEEE International Conference on Computer Vision, Venice, Oct, 2017, pp. 5209-5218.
[20] N. Hyeonwoo, H. Seunghoon and H.Bohyung, “Learning deconvolution network for semantic segmentation,” inProceedings of the IEEE International Conference on Computer Vision, Santiago,Feb. 2015, pp. 1520-1528.
[21] Z. D. Matthew and F. Rob, “Visualizingand Understanding Convolutional Networks,” in 13th European Conference onComputer Vision. Sep. 2014, Vol. 8689 LNCS, no. PART 1, pp. 818-833.
[22] M. Dongbo, C. Sunghwan, L. Jiangbo, H.Bumsub, S. Kwanghoon and D. N. Minh, “Fast global image smoothing based onweighted least squares,” IEEE Transactions on Image Processing, vol. 23, no.12, pp. 5638-5653, Dec. 2014.
[23] H. Kaiming, Z. Xiangyu, R. Shaoqing andS. Jian. “Delving deep into rectifiers: Surpassing human-level performance onimagenet classification,” in Proceedings of the IEEE International Conference onComputer Vision, Santiago, Dec. 2015, pp. 1026-1034.