【Module】【论文复现】CSPNet

前言:这篇文章是由台湾学者Chien-Yao Wang等人在CVPR2019上发表的。文章提出了跨阶段局部网络(CSPNet),以缓解以往的工作需进行大量推理计算的问题。在当前风靡一时的YOLOv4目标检测网络中,也引用了CSPNet作为骨干网络。作者已将代码开源:
https://github.com/WongKinYiu/CrossStagePartialNetworks
一、提出背景
随着卷积神经网络结构变得更深更宽,CNN显示出了它特别强大的功能。但是,扩展神经网络的体系结构通常会带来更多的计算,这使大多数人无法负担诸如目标检测之类的计算量繁重的任务。
由此,提出了跨阶段局部网络(CSPNet),用来缓解以往工作需要从网络架构角度进行大量推理计算的问题,作者还把这个问题归结为网络优化中的重复梯度信息。
以DenseNet为例分析
DenseNet的单个Dense Block网络结构如下:

正向传播:
x 1 = w 1 ∗ x 0 x_1 = w_1 * x_0 x1=w1∗x0 x 2 = w 2 ∗ [ x 0 , x 1 ] x_2 = w_2 * [x_0,x_1] x2=w2∗[x0,x1] … … … x k = w k ∗ [ x 0 , x 1 , … , x k − 1 ] x_k =w_k * [x_0, x_1,…,x_{k-1}] xk=wk∗[x0,x1,…,xk−1]
其中, ∗ * ∗ 代表卷积操作; [ x 0 , x 1 , … , x k − 1 ] [x_0, x_1,…,x_{k-1}] [x0,x1,…,xk−1]代表 concat 操作; w i w_i wi代表第 i i i 个Dense Layer的权重; x i x_i xi代表第 i i i 个Dense Layer的输出。
由此,提出了跨阶段局部网络(CSPNet)。在这项工作中,作者研究了最先进的方法,比如ResNet、ResNeXt和DenseNet的计算负担。进一步将开发的高效组件与上述网络融合,使上述网络可以部署在cpu和移动gpu上,而不会牺牲性能。反向传播:
w 1 ′ = f ( w 1 , g 0 ) w_1^{'} = f(w_1 , g_0) w1′=f(w1,g0) w 2 ′ = f ( w 2 , g 0 , g 1 ) w_2^{'} = f(w_2 , g_0,g_1) w2′=f(w2,g0,g1) w 3 ′ = f ( w 3 , g 0 , g 1 , g 2 ) w_3^{'} = f(w_3 , g_0,g_1,g_2) w3′=f(w3,g0,g1,g2) … … … w k ′ = f ( w k , g 0 , g 1 , g 2 , … , g k − 1 ) w_k^{'} = f(w_k , g_0,g_1,g_2,…,g_{k-1}) wk′=f(wk,g0,g1,g2,…,gk−1)
其中 f f f 是权重更新函数, g i g_i gi 为传播到较密集层的梯度, w i w_i wi代表第 i i i 个Dense Layer的权重。
不难看出,有大量的梯度信息被重复使用来更新不同Dense Layer的权重,可能会导致Dense Layer反复学习复制梯度的信息,使计算量增大且冗余。
二、CSPNet细节
设计CSPNet的主要目的:使该体系结构能够实现更丰富的梯度组合,同时减少计算量。方法:通过将基础层的特征图划分为两个部分,然后通过提出的跨阶段层次结构将它们合并,可以实现此目标。
2.1、CSP DenseNet
上面我们讨论了DenseNet的正向传播和反向传播,也从公式中看出了这种Concat大量feature map的方式虽然会学习到更多的语义信息,但是同样在反向传播中也会由于特征重用而造成大量的梯度信息被重复使用,这样子可能会导致Dense Layer反复学习梯度的信息,使计算量增大且冗余。那么让我们再来看看CSPNet应用到DenseNet中(CSP DenseNet)又会怎么样呢?
先看下CSP DenseNet的单个Dense Block网络结构:

正向传播:
x k = w k ∗ [ x 0 ′ ′ , x 1 , … , x k − 1 ] x_k = w_k * [x_0^{''},x_1,…,x_{k-1}] xk=wk∗[x0′′,x1,…,xk−1] x T = w T ∗ [ x 0 ′ ′ , x 1 , … , x k − 1 , x k ] x_T = w_T * [x_0^{''},x_1,…,x_{k-1}, x_k] xT=wT∗[x0′′,x1,…,xk−1,xk] x U = w U ∗ [ x 0 ′ , x T ] x_U =w_U * [x_0^{'},x_T] xU=wU∗[x0′,xT]
其中, ∗ * ∗ 代表卷积操作; [ x 0 ′ ′ , x 1 , … , x k − 1 ] [x_0^{''},x_1,…,x_{k-1}] [x0′′,x1,…,xk−1]代表 concat 操作; w i w_i wi代表第 i i i 个Dense Layer的权重; x i x_i xi代表第 i i i 个Dense Layer的输出。CSPDenseNet的一个阶段由Partial Dense Block和Partial Transition Layer组成。
1、在Partial Dense Block中,如下图将Base Layer(上一层的输出) x 0 x_0 x0分成 x 0 ′ , x 0 ′ ′ x_0^{'}, x_0^{''} x0′,x0′′ 两个部分,其中 x 0 ′ x_0^{'} x0′ 直接连接到阶段的末端,而 x 0 ′ ′ x_0^{''} x0′′ 则送入一个Dense Block。
2、一个局部过渡层的所有步骤如下:将Dense Block输出 [ x 0 ′ ′ , x 1 , x 2 , … , x k ] [x_0^{''}, x_1, x_2, …,x_k] [x0′′,x1,x2,…,xk] 送入下一个Transition ,输出 X T X_T XT, 再与第一部分的 x 0 ′ x_0^{'} x0′进行concat, 送入另一个Transition, 最终输出 x U x_U xU。
下图就可以很好的描述这个过程:

反向传播:
w k ′ = f ( w k , g 0 ′ ′ , g 1 , g 2 , … , g k − 1 ) w_k^{'} = f(w_k , g_0^{''},g_1,g_2,…,g_{k-1}) wk′=f(wk,g0′′,g1,g2,…,gk−1) w T ′ = f ( w T , g 0 ′ ′ , g 1 , g 2 , … , g k − 1 , g k ) w_T^{'} = f(w_T , g_0^{''},g_1,g_2,…,g_{k-1},g_{k}) wT′=f(wT,g0′′,g1,g2,…,gk−1,gk) w U ′ = f ( w U , g 0 ′ , g T ) w_U^{'} = f(w_U , g_0^{'},g_T) wU′=f(wU,g0′,gT)
其中 f f f 是权重更新函数, g i g_i gi 为传播到较密集层的梯度, w i w_i wi代表第 i i i 个Dense Layer的权重。
可以看出,在更新梯度时,对于 x 0 ′ x_0^{'} x0′和 x 0 ′ ′ x_0^{''} x0′′,双方都不含有另一部分的重复梯度信息。
解释:
如上面式一式二 x 0 ′ ′ x_0^{''} x0′′的梯度信息( g 0 ′ ′ , g 1 , g 2 , … , g k − 1 , g k g_0^{''},g_1,g_2,…,g_{k-1},g_{k} g0′′,g1,g2,…,gk−1,gk 和 式三 x 0 ′ x_0^{'} x0′的梯度信息( g 0 ′ , g T g_0^{'},g_T g0′,gT)不相同,双方都不含有另一部分的重复梯度信息。
总结:CSPDenseNet 继承了DenseNet特征重用的特点,同时通过阶段梯度流的方法来避免过多的重复梯度信息。这种思想是通过设计分层特征融合策略和使用局部过渡层来实现的。
2.2、Partial Dense Block
Partial Dense Block执行步骤:将Base Layer(上一层的输出) x 0 x_0 x0分成 x 0 ′ , x 0 ′ ′ x_0^{'}, x_0^{''} x0′,x0′′ 两个部分,其中 x 0 ′ x_0^{'} x0′ 直接连接到阶段的末端,而 x 0 ′ ′ x_0^{''} x0′′ 则送入一个Dense Block。
设计局部稠密块的目的是:
- 增加梯度路径: 通过分块归并策略,可以使梯度路径的数量增加一倍。由于采用了跨阶段策略,可以减轻使用显式特征图copy进行拼接所带来的弊端;
- 每一层的平衡计算:通常,DenseNet基层的通道数远大于生长速率。由于在局部稠密块中,参与稠密层操作的基础层通道仅占原始数据的一半,可以有效解决近一半的计算瓶颈;
- 减少内存流量
2.3、Partial Transition Layer
Partial Transition Layer执行步骤:
- 在Partial Dense Block中,如下图将Base Layer(上一层的输出) x 0 x_0 x0分成 x 0 ′ , x 0 ′ ′ x_0^{'}, x_0^{''} x0′,x0′′ 两个部分,其中 x 0 ′ x_0^{'} x0′ 直接连接到阶段的末端,而 x 0 ′ ′ x_0^{''} x0′′ 则送入一个Dense Block。
- 一个局部过渡层的所有步骤如下:将Dense Block输出 [ x 0 ′ ′ , x 1 , x 2 , … , x k ] [x_0^{''}, x_1, x_2, …,x_k] [x0′′,x1,x2,…,xk] 送入下一个Transition ,输出 X T X_T XT, 再与第一部分的 x 0 ′ x_0^{'} x0′进行concat, 送入另一个Transition, 最终输出 x U x_U xU。
设计Partial Dense Block的目的是使梯度组合的差异最大。局部过渡层是一种层次化的特征融合机制,它利用梯度流的聚合策略来防止不同的层学习重复的梯度信息。在这里,作者设计了两个CSPDenseNet变体来展示这种梯度流截断是如何影响网络的学习能力的。
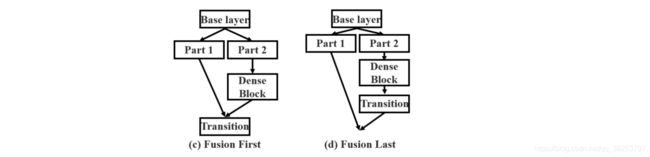
如上图中的 © 和 (d) 展示了两种不同的融合策略:
- Fusion First:是将两部分生成的feature map进行拼接,然后进入过渡层。如果采用这种策略,将会损失大量的梯度信息。
- Fusion Last:对于fusion last策略,来自稠密块的输出将经过过渡层,然后与来自Part1的feature map进行连接。如果采用这种策略,由于梯度流被截断,梯度信息将不会被重用。
作者对这两种策略的实验结果:

从上图可以看出,如果采用Fusion Last策略进行图像分类,计算成本明显下降,但Top-1的准确率仅下降0.1%。另一方面,CSP (fusion first)策略确实有助于显著降低计算成本,但Top-1的准确率显著下降1.5%。
总结:通过使用跨阶段的分割和合并策略,我们能够有效地减少信息集成过程中重复的可能性。如果能够有效地减少重复的梯度信息,那么网络的学习能力将会得到很大的提高。
三、CSPNet的改进效果
相应地,基于CSPNet的目标检测器在不同改进方面的效果如下:
- 由于CSPNet能够提升CNN的学习能力,因此可以使用更小的模型来达到更好的准确性。作者提出的模型在COCO的AP50可以达到50%,GTX1080ti 达到109 fps。
- 由于CSPNet可以显著降低计算瓶颈,精确FusionModel (EFM)可以有效降低所需的内存带宽,作者提出的方法可以在Nvidia Jetson TX2上以49 fps的速度COCO AP50实现42%。
- 由于CSPNet可以有效地减少大量的内存流量,作者提出的方法可以在Intel Core i9-9900K上以52 fps的速度COCO AP50实现40%。
作者的实验结果如下:
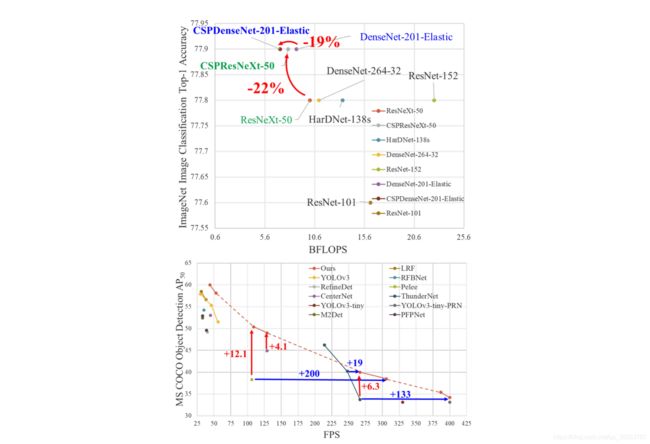
总结:从实验结果来看,分类问题中,使用CSPNet可以降低计算量,但是准确率提升很小;在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能力,同时也降低了计算量。
四、Pytorch实现
4.1、CSPDenseNet
import torch
from torch import Tensor
from typing import List
from collections import OrderedDict
from torch import nn
import torch.utils.checkpoint as cp
import torch.nn.functional as F
class _Transition(nn.Sequential):
def __init__(self,
num_input_features: int,
num_output_features: int):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_features,
num_output_features,
kernel_size=1,
stride=1,
bias=False))
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class _DenseLayer(nn.Module):
"""DenseBlock中的内部结构 DenseLayer: BN + ReLU + Conv(1x1) + BN + ReLU + Conv(3x3)"""
def __init__(self,
num_input_features: int,
growth_rate: int,
bn_size: int,
drop_rate: float,
memory_efficient: bool = False):
"""
:param input_c: 输入channel
:param growth_rate: 论文中的 k = 32
:param bn_size: 1x1卷积的filternum = bn_size * k 通常bn_size=4
:param drop_rate: dropout 失活率
:param memory_efficient: Memory-efficient版的densenet 默认是不使用的
"""
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(in_channels=num_input_features,
out_channels=bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False))
self.drop_rate = drop_rate
self.memory_efficient = memory_efficient
def bn_function(self, inputs: List[Tensor]) -> Tensor:
# 第一个DenseBlock inputs: 最后会生成 [16,32,56,56](输入) + [16,32,56,56]*5
# concat_features=6个List的shape分别是: [16,32,56,56](输入)、[16,32,56,56]、[16,64,56,56]、[16,96,56,56]、[16,128,56,56]、[16,160,56,56]、[16,192,56,56]
concat_features = torch.cat(inputs, 1) # 该DenseBlock的每一个DenseLayer的输入都是这个DenseLayer之前所有DenseLayer的输出再concat
# 之后的DenseBlock中的append会将每一个之前层输入加入inputs 但是这个concat并不是把所有的Dense Layer层直接concat到一起
# 注意:这个concat和之后的DenseBlock中的concat非常重要,理解这两句就能理解DenseNet中密集连接的精髓
bottleneck_output = self.conv1(self.relu1(self.norm1(concat_features))) # 一直是[16,128,56,56]
return bottleneck_output
@staticmethod
def any_requires_grad(inputs: List[Tensor]) -> bool:
"""判断是否需要更新梯度(training)"""
for tensor in inputs:
if tensor.requires_grad:
return True
return False
@torch.jit.unused
def call_checkpoint_bottleneck(self, inputs: List[Tensor]) -> Tensor:
"""
torch.utils.checkpoint: 用计算换内存(节省内存)。 详情可看: https://arxiv.org/abs/1707.06990
torch.utils.checkpoint并不保存中间激活值,而是在反向传播时重新计算它们。 它可以应用于模型的任何部分。
具体而言,在前向传递中,function将以torch.no_grad()的方式运行,即不存储中间激活值 相反,前向传递将保存输入元组和function参数。
在反向传播时,检索保存的输入和function参数,然后再次对函数进行正向计算,现在跟踪中间激活值,然后使用这些激活值计算梯度。
"""
def closure(*inp):
return self.bn_function(inp)
return cp.checkpoint(closure, *inputs)
def forward(self, inputs: Tensor) -> Tensor:
if isinstance(inputs, Tensor): # 确保inputs的格式满足要求
prev_features = [inputs]
else:
prev_features = inputs
# 判断是否使用memory_efficient的densenet and 是否需要更新梯度(training)
# torch.utils.checkpoint不适用于torch.autograd.grad(),而仅适用于torch.autograd.backward()
if self.memory_efficient and self.any_requires_grad(prev_features):
# torch.jit 模式下不合适用memory_efficient
if torch.jit.is_scripting():
raise Exception("memory efficient not supported in JIT")
# 调用efficient densenet 思路:用计算换显存
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
# 调用普通的densenet 永远是[16,128,56,56]
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output))) # 永远是[16,32,56,56]
if self.drop_rate > 0:
new_features = F.dropout(new_features,
p=self.drop_rate,
training=self.training)
return new_features
class _Csp_Transition(torch.nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Csp_Transition, self).__init__()
self.add_module('norm', torch.nn.BatchNorm2d(num_input_features))
self.add_module('relu', torch.nn.ReLU(inplace=True))
self.add_module('conv', torch.nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
class _Csp_DenseBlock(torch.nn.Module):
def __init__(self,
num_layers,
num_input_features,
bn_size,
growth_rate,
drop_rate,
memory_efficient=False,
transition=False):
"""
:param num_layers: 当前DenseBlock的Dense Layer的个数
:param num_input_features: 该DenseBlock的输入Channel,开始会进行拆分,最后concat 每经过一个DenseBlock都会进行叠加
叠加方式:num_features = num_features // 2 + num_layers * growth_rate // 2
:param bn_size: 1x1卷积的filternum = bn_size*k 通常bn_size=4
:param growth_rate: 指的是论文中的k 小点比较好 论文中是32
:param drop_rate: dropout rate after each dense layer
:param memory_efficient: If True, uses checkpointing. Much more memory efficient
:param transition: 分支需不需Transition(csp transition) stand/fusionlast=True fusionfirst=False
"""
super(_Csp_DenseBlock, self).__init__()
self.csp_num_features1 = num_input_features // 2 # 平均分成两部分 第一部分直接传到后面concat
self.csp_num_features2 = num_input_features - self.csp_num_features1 # 第二部分进行正常卷积等操作
trans_in_features = num_layers * growth_rate
for i in range(num_layers):
layer = _DenseLayer(
num_input_features=self.csp_num_features2 + i * growth_rate, # 每生成一个DenseLayer channel增加growth_rate
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
self.transition = _Csp_Transition(trans_in_features, trans_in_features // 2) if transition else None
def forward(self, x):
# x = [B, C, H, W]
# 拆分channel, 每次只用一半的channel(csp_num_features1)会继续进行卷积等操作 另一半(csp_num_features2)直接传到当前DenseBlock最后进行concat
features = [x[:, self.csp_num_features1:, ...]] # [16,32,56,56](输入) [16,32,56,56]*6
for name, layer in self.named_children():
if 'denselayer' in name: # 遍历所有denselayer层
# new_feature: 永远是[16,32,56,56]
new_feature = layer(features)
features.append(new_feature)
dense = torch.cat(features[1:], 1) # 第0个是上一DenseBlock的输入,所以不用concat
# 到这里分支DenseBlock结束
if self.transition is not None:
dense = self.transition(dense) # 进行分支(csp transition)Transition
return torch.cat([x[:, :self.csp_num_features1, ...], dense], 1)
class Csp_DenseNet(torch.nn.Module):
def __init__(self,
growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
transitionBlock=True,
transitionDense=False,
bn_size=4,
drop_rate=0,
num_classes=1000,
memory_efficient=False):
"""
:param growth_rate: DenseNet论文中的k 通常k=32
:param block_config: 每个DenseBlock中Dense Layer的个数 121=>(6, 12, 24, 16)
:param num_init_features: 模型第一个卷积层(Dense Block之前的唯一一个卷积)Conv0 的channel = 64
:param transitionBlock: 分支需不需要Transition transitionDense: 主路需不需要transition
transitionBlock=True + transitionDense=True => stand
transitionBlock=False + transitionDense=True => fusionfirst
transitionBlock=True + transitionDense=False => fusionlast
:param bn_size: 1x1卷积的filternum = bn_size*k 通常bn_size=4
:param drop_rate: dropout rate after each dense layer 默认为0 不用的
:param num_classes: 数据集类别数
:param memory_efficient: If True, uses checkpointing. Much more memory efficient 默认为False
"""
super(Csp_DenseNet, self).__init__()
self.growth_down_rate = 2 if transitionBlock else 1 # growth_down_rate这个变量好像没用到
self.features = torch.nn.Sequential(OrderedDict([
('conv0', torch.nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', torch.nn.BatchNorm2d(num_init_features)),
('relu0', torch.nn.ReLU(inplace=True)),
('pool0', torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _Csp_DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
transition=transitionBlock
)
self.features.add_module('denseblock%d' % (i + 1), block)
# 每执行了一个Dense Block就要对下一个Dense Block的输入进行更新(channel进行了叠加)
# 这里num_features变换是代码的最核心的部分
# num_features:每个DenseBlock的输出
# 如果支路用了transition: num_features=(上一个DenseBlock输出//2 + num_layers * growth_rate) // 2
# 因为只要经过transition输出都会变为原来的一半
# 如果支路没有用transition: num_features=上一个DenseBlock输出//2 + num_layers * growth_rate
num_features = num_features // 2 + num_layers * growth_rate // 2 if transitionBlock\
else num_features // 2 + num_layers * growth_rate
# 主路需不需要transition(常见的DenseNet的那种transition)
if (i != len(block_config) - 1) and transitionDense:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
self.features.add_module('norm5', torch.nn.BatchNorm2d(num_features))
self.classifier = torch.nn.Linear(num_features, num_classes)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, torch.nn.BatchNorm2d):
torch.nn.init.constant_(m.weight, 1)
torch.nn.init.constant_(m.bias, 0)
elif isinstance(m, torch.nn.Linear):
torch.nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = torch.nn.functional.relu(features, inplace=True)
out = torch.nn.functional.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def _csp_densenet(growth_rate, block_config, num_init_features, model='fusionlast', **kwargs):
"""
:param growth_rate: DenseNet论文中的k 通常k=32
:param block_config: 每个DenseBlock中Dense Layer的个数 121=>(6, 12, 24, 16)
:param num_init_features: 模型第一个卷积层(Dense Block之前的唯一一个卷积)Conv0 的channel
:param model: 模型类型 有stand、fusionfirst、fusionlast三种
:param **kwargs: 不定长参数 通常会传入 num_classes
transitionBlock: 分支需不需要Transition transitionDense: 主路需不需要transition
transitionBlock=True + transitionDense=True => stand
transitionBlock=False + transitionDense=True => fusionfirst
transitionBlock=True + transitionDense=False => fusionlast
"""
if model == 'stand':
return Csp_DenseNet(growth_rate, block_config, num_init_features,
transitionBlock=True, transitionDense=True, **kwargs)
if model == 'fusionfirst':
return Csp_DenseNet(growth_rate, block_config, num_init_features,
transitionBlock=False, transitionDense=True, **kwargs)
if model == 'fusionlast':
return Csp_DenseNet(growth_rate, block_config, num_init_features,
transitionBlock=True, transitionDense=False, **kwargs)
raise ('please input right model keyword')
def csp_densenet121(growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
def csp_densenet161(growth_rate=48, block_config=(6, 12, 36, 24),
num_init_features=96, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
def csp_densenet169(growth_rate=32, block_config=(6, 12, 32, 32),
num_init_features=64, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
def csp_densenet201(growth_rate=32, block_config=(6, 12, 48, 32),
num_init_features=64, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
if __name__ == '__main__':
"""测试模型"""
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 可以输入变量model='stand/fusionfirst/fusionlast(默认)'自己选择三种模型
model = csp_densenet121(num_classes=5, model='fusionlast')
print(model)
Reference
论文csdn1: link.
论文csdn2: link.
github代码: link.
zhihu代码: link.
csdn代码: link.