模型调参经验-LR、SVM、RF、GBDT、Xgboost、LightGBM
会调包其实是基础,过程中还能加深对模型的理解,发散优化的思路。总结一下sklearn和tensorflow两个框架中主流模型的调参经验,不定期补充。
LR
penalty,选择正则化方式:
主要为解决过拟合问题,一般penalty选择L2正则化就够了。但是如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化。另外,如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。
penalty参数的选择会影响我们损失函数优化算法的选择。newton-cg, lbfgs和sag这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear通吃L1正则化和L2正则化。
solver,选择loss函数的优化算法:
1、liblinear:开源liblinear库实现,内部使用坐标轴下降法。
2、lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化。
3、 newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
4、sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候,SAG是一种线性收敛算法,这个速度远比SGD快。
sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择,其次两个牛顿法。但是sag不能用于L1正则化,所以当样本量大,又需要L1正则化的话就要做取舍。
liblinear也有自己的弱点,对于多元逻辑回归常见的one-vs-rest(OvR)和many-vs-many(MvM),liblinear只支持OvR。而MvM一般比OvR分类相对准确一些,所以如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear,也意味着不能使用L1正则化。
综上,liblinear支持L1和L2,只支持OvR做多分类,“lbfgs”, “sag” “newton-cg”只支持L2,支持OvR和MvM做多分类。
multi_class,分类方式选择:
有 ovr和multinomial两个值可以选择,默认是 ovr。multinomial即前面提到的many-vs-many(MvM)。
OvR的思想是多元逻辑回归,都可以看成二元。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
综上,OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。
class_weight,类型权重参数:
用于标示分类模型中各种类型的权重,不输入则所有类型的权重一样。
选择balanced让类库自己计算类型权重,计算方法为:总样本数/(总类别数*每个类的样本数向量)。即某种类型样本量越多,则权重越低,样本量越少,则权重越高。
或者我们自己输入各个类型的权重,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。
可以解决的问题为,1.误分类的代价很高,我们可以适当提升代价高那一类的权重。2.样本不均衡,提升样本量少的类别的权重。
sample_weight,样本权重参数:
在调用fit函数时,通过sample_weight来自己调节每个样本的权重。
样本不平衡,造成样本不是总体样本的无偏估计,从而可能导致模型预测能力下降。
遇到这种情况,我们可以通过调节类别和样本的权重来尝试解决。如果上面两种方法都用到了,那么样本的真正权重是class_weight*sample_weight。
关于LR,工程界的共识是: 特征离散化可以得到更好的效果。
总结下原因:
1.离散特征在工程上容易设计,计算的时候计算逻辑简单。比如工程实现可以直接对离散特征的特征编号+取值做hash,来当作他最终的特征id,逻辑简单粗暴。
2.离散化后,做分段,对异常数据有比较好的鲁棒性,比如年龄,>30岁为1,那么有异常数据哪怕是300岁,取值也不会有多大的问题。当然有人可能质疑,我用连续特征也会归一化,那么请看第三点
3.特征分段离散化后,每一个取值都有一个单独的权重,能提升表达能力。比如一个连续值特征0-1, 可能0-0.2部分的差异度要小于0.8-1的差异度,而如果用连续特征,两者公用一个权重,那这里就体现不出来
4.离散化后,可以对特征进行交叉组合,引入非线性因素。这个非常重要!
引入一些离散的id属性,比如广告id,可以直接学习到这个广告的“好坏”,然后一般往往会拿id和一些其他的属性做组合。
离散化的弱点:
分段后,可能原本很接近的两个连续值被离散到两个不同的阈值,会带来不好的影响。第二,分段的确会屏蔽掉一些差异化因素。
SVM
SVM模型有两个非常重要的参数C与gamma。
其中 C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差。
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。
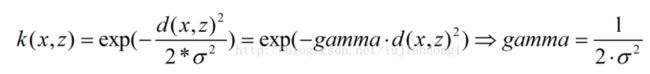
如果gamma设的太大, δ \delta\, δ 会很小, δ \delta\, δ 很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
rbf实际是记忆了若干样例,在sv中各维权重重要性等同。线性核学出的权重是feature weighting作用或特征选择 。
SVM.svc参数
C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本,default C = 1.0; 相当于惩罚松弛变量,C越大,松弛变量接近0,即对误分类的惩罚增大,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel:参数选择有RBF, Linear, Poly, Sigmoid, 默认的是"RBF";
degree:if you choose ‘Poly’ in param 2, this is effective, degree决定了多项式的最高次幂;
gamma:核函数的系数(‘Poly’, ‘RBF’ and ‘Sigmoid’), 默认是gamma = 1 / n_features;
coef0:核函数中的常数项,‘RBF’ and 'Poly’有效;
probablity: 是否采用概率估计?(默认false);
shrinking:是否进行启发式;
tol:停止训练的误差值大小,默认为1e-3;
cache_size: 制定训练所需要的内存(以MB为单位);
class_weight: 每个类所占据的权重,不同的类设置不同的惩罚参数C, 缺省的话自适应;
verbose: 是否启用详细输出。跟多线程有关;
max_iter: 最大迭代次数,default = 1, -1为无限制;
decision_function_shape : ‘ovo’ 一对一, ‘ovr’ 多对多, default=None;
random_state :用于概率估计的数据重排时的伪随机数生成器的种子。
属性:
svc.n_support_:各类各有多少个支持向量
svc.support_:各类的支持向量在训练样本中的索引
svc.support_vectors_:各类所有的支持向量
RF
其实,对于基于决策树的模型,调参的方法都是大同小异。一般都需要如下步骤:
- 首先选择较高的学习率,大概0.1附近,这样是为了加快收敛的速度。这对于调参是很有必要的。
- 对决策树基本参数调参;
- 正则化参数调参;
- 最后降低学习率,这里是为了最后提高准确率。
在 sklearn中,随机森林的函数模型是:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
参数分析
max_features: 随机森林允许单个决策树使用特征的最大数量。
Python为最大特征数提供了多个可选项。 下面是其中的几个:
Auto/None :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。
sqrt :此选项是每颗子树可以利用总特征数的平方根个。 例如,如果变量(特征)的总数是100,所以每颗子树只能取其中的10个。“log2”是另一种相似类型的选项。
0.2:此选项允许每个随机森林的子树可以利用变量(特征)数的20%。如果想考察的特征x%的作用, 我们可以使用“0.X”的格式。
max_features如何影响性能和速度?
增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。
n_estimators: 在利用最大投票数或平均值来预测之前,你想要建立子树的数量。
较多的子树可以让模型有更好的性能,但同时让你的代码变慢。 你应该选择尽可能高的值,只要你的处理器能够承受的住,因为这使你的预测更好更稳定。
min_sample_leaf: 最小样本叶片大小,很重要。
叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。
调参对随机森林来说,不会发生很大的波动,相比神经网络来说,随机森林即使使用默认的参数,也可以达到良好的结果。
使得模型训练更容易的特征
n_jobs:告诉引擎有多少处理器是它可以使用。
“-1”意味着没有限制,而“1”值意味着它只能使用一个处理器。
random_state:让结果容易复现。 一个确定的随机值将会产生相同的结果,在参数和训练数据不变的情况下。 我曾亲自尝试过将不同的随机状态的最优参数模型集成,有时候这种方法比单独的随机状态更好。
oob_score:随机森林交叉验证方法。 它和留一验证方法非常相似,但这快很多。 这种方法只是简单的标记在每颗子树中用的观察数据。 然后对每一个观察样本找出一个最大投票得分,是由那些没有使用该观察样本进行训练的子树投票得到。(每一列的*数据是没有被选中用于训练决策树的数据,我们称之为决策树的out-of-bag(OOB)样本。)
GBDT
把重要参数分为两类,第一类是Boosting框架的重要参数,第二类是弱学习器即CART回归树的重要参数。
boosting框架参数
n_estimators: 最大的弱学习器的个数。默认100,常与learning_rate一起考虑。
learning_rate: 即每个弱学习器的权重缩减系数ν,也称作步长,默认1。一般来说,可以从一个小一点的ν开始调参。对于同样的训练集拟合效果,较小的ν需要更多的弱学习器的迭代次数。
subsample: 不放回子采样。如果取值小于1,则只有一部分样本会去做拟合,可减少方差,即防止过拟合,但是会增加偏差,因此取值不能太低。
loss: 分类模型和回归模型的损失函数不同。
对于分类模型,可选对数似然损失函数"deviance"和指数损失函数"exponential"。一般来说,推荐使用默认的对数似然损失"deviance"。它对二元分离和多元分类都有比较好的优化。而指数损失函数等价于Adaboost算法。
对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。一般来说,如果数据的噪声不大,用默认的均方差"ls"比较好。否则,推荐用抗噪的损失函数"huber"。另外,需要对训练集进行分段预测时,采用“quantile”。
alpha:这个参数只存在于回归模型,当使用Huber损失"huber"和分位数损失“quantile”时,需要指定分位数的值。默认是0.9,如果噪声大,可适当降低。
弱学习器参数
max_depth:默认值3。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
max_features:构建决策树最优模型时考虑的最大特征数。一般来说,如果样本特征数不多,比如小于50,用默认的"None"就可以了,如果特征数非常多,我们可以灵活使用’sqrt’等来控制划分时考虑的最大特征数,以控制决策树的生成时间。
min_samples_leaf:叶子节点含有的最少样本,小于则剪枝,默认是1。 如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
min_samples_split:叶子节点可分的最小样本数,默认是2。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
max_leaf_nodes :最大叶子节点数,可防止过拟合,默认是"None”,即不限制。如果特征不多,可以不考虑这个值,否则,可以加以限制,具体的值可通过交叉验证得到。
min_impurity_decrease :节点划分的最小不纯度。限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。一般不推荐改动默认值1e-7。
criterion :表示节点的划分标准,'gini’等。
min_weight_fraction_leaf:叶子节点最小的样本权重和,小于则剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重。
调整顺序
- 首先从步长(learning rate)和迭代次数(n_estimators)入手。一般来说,开始选择一个较小的步长来网格搜索最好的迭代次数。
- 找到了一个合适的迭代次数,再开始对决策树进行调参。首先对决策树最大深度max_depth和内部节点再划分所需最小样本数min_samples_split进行网格搜索。定下来最大树深。
- 再对内部节点再划分所需最小样本数min_samples_split和叶子节点最少样本数min_samples_leaf一起调参。
- 再对最大特征数max_features、子采样的比例subsample进行网格搜索。
- 基本得到所有调优的参数后,可以减半步长,最大迭代次数加倍来增加模型的泛化能力,防止过拟合。
Xgboost
XGBoost在基于梯度提升的框架下,其对目标函数进行二阶泰勒展开,使用了二阶导数加快了模型收敛速度,并使用正则化的目标函数,控制模型的复杂度。不仅如此,XGBoost算法借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,同时在进行完一次迭代后,会将叶子节点的权重乘上缩减系数,削弱每棵树的影响,让后续迭代有更大的学习空间。
特征权重和缺失值补充设置:
dtrain = xgb.Dmatrix(data,label=label,missing = 0,weight=w)
eta:learning_rate, 相当于学习率。
gamma:xgboost的优化loss的gamma,T(叶结点个数)的正则化系数,起到预剪枝的作用。

max_depth:树的深度,越深越容易过拟合。
min_child_weight:新分裂出来的一个叶子节点,只有当叶子节点上hession矩阵的和大于这个值时才会分裂,也起到了预剪枝的作用。
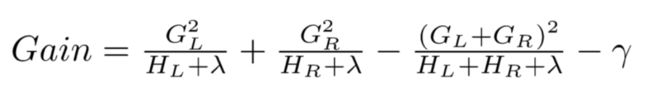
subsample:训练时,对训练数据进行采样,来自随机森林的做法。
colsample_bytree, colsample_bylevel, colsample_bynode:每颗树/每层/每个节点分裂时,是否对特征进行采样,同样来自随机森林的做法。
lambda:L2正则。
alpha:L1正则。
eval_metric:校验数据所用评价指标。
LightGBM
提高精确度的两个最重要参数:
max_depth :设置树深度,深度越大可能过拟合。
num_leaves:因为 LightGBM 使用的是 leaf-wise 的算法,因此在调节树的复杂程度时,使用的是 num_leaves 而不是 max_depth。大致换算关系:num_leaves = 2^(max_depth),但是它的值的设置应该小于 2^(max_depth),否则可能会导致过拟合。
调节这两个参数降低过拟合:
min_data_in_leaf:是一个很重要的参数, 也叫min_child_samples,它的值取决于训练数据的样本个数和num_leaves。将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合。
min_sum_hessian_in_leaf:也叫min_child_weight,使一个结点分裂的最小海森值之和(Minimum sum of hessians in one leaf to allow a split. Higher values potentially decrease overfitting)。
这两个参数都也可降低过拟合:
feature_fraction参数来进行特征的子抽样。这个参数可以用来防止过拟合及提高训练速度。
bagging_fraction+bagging_freq参数必须同时设置,bagging_fraction相当于subsample样本采样,可以使bagging更快的运行,同时也可以降拟合。bagging_freq默认0,表示bagging的频率,0意味着没有使用bagging,k意味着每k轮迭代进行一次bagging。
正则化参数
lambda_l1(reg_alpha), lambda_l2(reg_lambda),用于降低过拟合,两者分别对应l1正则化和l2正则化。
learning_rate与n_estimators
使用较高的学习速率可以让收敛更快,但是准确度肯定没有细水长流来的好。使用较低的学习速率,以及更多的决策树n_estimators来训练数据,尝试进一步的优化分数。