Python学习笔记29:继承的优缺点
Python学习笔记29:继承的优缺点
- 最近因为一些别的事所以没有继续学习和更新,抱歉了。今天回到学习Python的道路上,我们继续旅途。
- 本系列今后的示例代码都将存放在Github项目:https://github.com/icexmoon/python-learning-notes
从最近的几篇笔记开始,我们开始探索Python中的OOP。
前一篇笔记Python学习笔记28:从协议到抽象基类我们从协议和抽象类两个方面探讨了协议和抽象类在Python中的定位和用途。
今天我们要讨论的是Python中继承的特点,和其中的优缺点。
内建类的继承缺陷
这是一个隐蔽的问题和缺陷,至少在Java或者PHP中我并没有发现类似的问题。
至于我说的是什么,不要着急,我们往下看。
我们创建一个字典类型的子类,并重写__setitem__魔术方法:
class SubDict(dict):
def __setitem__(self, k, v):
v = "sub_item_"+str(v)
super().__setitem__(k, v)
sd = SubDict(one="one")
print(sd)
sd['two']='two'
print(sd)
sd.update(three="three")
print(sd)
# {'one': 'one'}
# {'one': 'one', 'two': 'sub_item_two'}
# {'one': 'one', 'two': 'sub_item_two', 'three': 'three'}
我们分别通过初始化方法、直接对元素赋值、调用update方法进行测试。
其中只有直接对元素赋值成功调用了我们重写的__setitem__,实质上__setitem__魔术方法本来就是对字典元素赋值操作的运算符重载,所以这是个必然结果。
而我们需要关注的是其它两种方式为何没有成功。
有一个事实我们是需要知道的,就是虽然Python的最大特点是让普通的开发者拥有和语言底层开发者一样的语言特性,但是实质上为了优化性能,并非所有的内建组件都用一致性的Python语言开发,比如最常用的组件:字典、列表和字符串,都是使用效率更高的C语言进行编译的可执行模块(对CPython解释器来说)。
这样做的好处显而易见,可以极大地提升性能,并且对普通开发者基本是没有任何影响的,但是在极个别情况下就会发生一些奇怪的现象,比如我们上面展示的那样。
如果你对这些C语言构建的内部组件进行继承并重写某些方法,很可能在调用的时候其行为并不会符合OOP中多态的行为。即父类并不会使用你重写的方法(比如__setitem__),这就是我所说的内建类的继承缺陷。
当然Python官方也给出了解决办法,在需要对此类内建类进行继承的时候,我们不应该直接继承,而是应该继承collections模块中的UserXXX类,这些类是纯Python编写,不存在以上所说的问题。
我们用这种方式改写刚才的示例:
from collections import UserDict
class SubDict(UserDict):
def __setitem__(self, k, v):
v = "sub_item_"+str(v)
super().__setitem__(k, v)
sd = SubDict(one="one")
print(sd)
sd['two']='two'
print(sd)
sd.update(three="three")
print(sd)
# {'one': 'sub_item_one'}
# {'one': 'sub_item_one', 'two': 'sub_item_two'}
# {'one': 'sub_item_one', 'two': 'sub_item_two', 'three': 'sub_item_three'}
现在没问题了,完全符合OOP中的多态含义。
从这其中我们可以看到一种思路,即如何取舍性能和编程语言的一致性表达。
在这里Python是通过额外提供纯Python编写的替代模块来平衡这其中的矛盾。
多重继承
多重继承大概是我从PHP转到Python的过程中接触到的最大的不同,我一开始觉得这种设计相当反人类。但深入了解后我惊奇地发现原来多重继承远比单继承的历史更为长远,远在C和C++时代就开始支持多继承,而之所以Java只支持单继承就是为了避免出现C、C++中的多继承滥用问题,而接口之类的技术反而出现的更晚。
从这类编程历史故纸堆我们就不难看出,多重继承是个类似于双刃剑的东西,很容易被不谨慎的开发者滥用而造成很多问题。
但也并不能一味地抵触和反感,因为OOP、函数式编程等等各种现代语言特性,其出现的根本目的是为了解决代码重用的问题,而多继承在这点上无疑是要比不能重用代码的Java中的接口有用的多。或许Java8出现可实现方法的接口正是出于此类考虑,这好像又是回到了多继承的老路。
我们回到Python本身,多重继承之所以问题多多,最根本的是要解决这样一个问题:如果多个平级父类拥有相同的方法,子类使用哪个?
这种问题称之为“菱形问题”。
菱形问题
我们来看这样一个典型的多继承结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NJjWxL5N-1620727210278)(https://www.hualigs.cn/image/60965267a2c8c.jpg)]
代码我使用EA生成,并且修改了一下:
代码如下:
#######################################################
#
# A.py
# Python implementation of the Class A
# Generated by Enterprise Architect
# Created on: 08-5��-2021 15:22:03
# Original author: 70748
#
#######################################################
class A:
def showMe(self):
print("A's showMe is called")
#######################################################
#
# B.py
# Python implementation of the Class B
# Generated by Enterprise Architect
# Created on: 08-5��-2021 15:22:03
# Original author: 70748
#
#######################################################
from pkg.A import A
class B(A):
def showMe(self):
super().showMe()
print("B's showMe is called")
#######################################################
#
# C.py
# Python implementation of the Class C
# Generated by Enterprise Architect
# Created on: 08-5��-2021 15:22:03
# Original author: 70748
#
#######################################################
from pkg.A import A
class C(A):
def showMe(self):
super().showMe()
print("C's showMe is called")
#######################################################
#
# D.py
# Python implementation of the Class D
# Generated by Enterprise Architect
# Created on: 08-5��-2021 15:22:03
# Original author: 70748
#
#######################################################
from pkg.B import B
from pkg.C import C
class D(B, C):
def showMe(self):
super().showMe()
print("D's showMe is called")
创建一个简单测试:
from pkg.D import D
d = D()
d.showMe()
# A's showMe is called
# C's showMe is called
# B's showMe is called
# D's showMe is called
初次接触到Python这种多继承的可能对这个测试结果有点费解,我们接下来进行详细解释。
MRO
我们之前有提过mro(method revolution order),利用它我们可以查看一个类的方法解析顺序:
from pkg.D import D
d = D()
d.showMe()
print(D.__mro__)
# A's showMe is called
# C's showMe is called
# B's showMe is called
# D's showMe is called
# (, , , , )
在这个菱形结构中,D的方法解析顺序是D>B>C>A,其中我们需要注意B和C的顺序,这在多个平行父类中尤为重要,他们的顺序取决于D的声明中D(B,C)的顺序,如果我们修改一下:
######################################################## # D.py# Python implementation of the Class D# Generated by Enterprise Architect# Created on: 08-5��-2021 15:22:03# Original author: 70748# #######################################################from pkg.B import Bfrom pkg.C import Cclass D(C,B): def showMe(self): super().showMe() print("D's showMe is called")
测试结果也会变成:
from pkg.D import Dd = D()d.showMe()print(D.__mro__)# A's showMe is called# B's showMe is called# C's showMe is called# D's showMe is called# (, , , , )
用UML图表示一下当前的解析顺序:
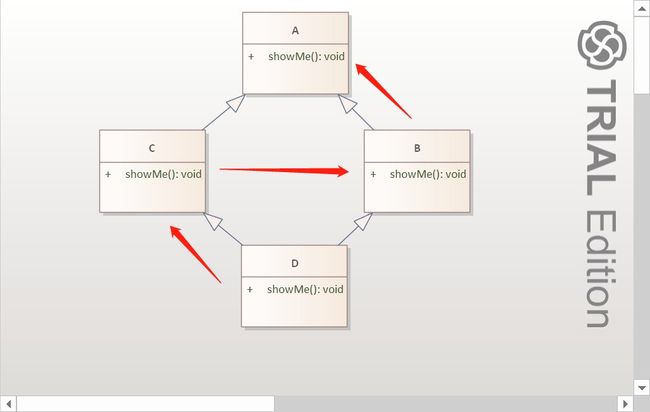
因为D中继承顺序改变,所以UML图中C和D的顺序也颠倒了。
我们来解释一下调用结果为什么会是那样:
- D的
showMe方法被调用。 - 通过D的
showMe方法中的super().showMe()向上解析,查找到C的showMe方法 - C的
showMe方法被调用。 - 通过C的
showMe方法中的super().showMe()向上解析,查找到B的showMe方法 - B的
showMe方法被调用。 - 通过B的
showMe方法中的super().showMe()向上解析,查找到A的showMe方法 - A的
showMe方法被调用,输出A's showMe is called。 - A的
showMe方法调用结束,在B的showMe方法中输出B's showMe is called。 - B的
showMe方法调用结束,在C的showMe方法中输出C's showMe is called。 - C的
showMe方法调用结束,在D的showMe方法中输出D's showMe is called。
解释起来稍微麻烦些,但结合UML图中的方法解析顺序不难理解。
Python正是通过规定了菱形问题中这种解析顺序,得以明确同级别父类的同名方法解析问题。
这种解析顺序在数学上称之为C3算法。
想继续了解C3算法的可以阅读C3 算法:Python 多继承的内部原理 Table of Contents。
需要注意的是,在C中调用super().showMe()却是调用了B的相应方法,但是C和B并无直接继承关系。
这是因为虽然在C的类定义中其基类只有A,但是对于D来说,这个菱形结构的继承关系中C在MRO解析顺序中的父检索对象应该是B而非A。
跨MRO调用
除了子类可以遵循mro原则调用父类的相应方法以外,子类还可以跳过mro规则显示地调用指定父类的方法:
class D(C,B): def showMe(self): A.showMe(self) # super().showMe() print("D's showMe is called")
from pkg.D import Dd = D()d.showMe()# A's showMe is called# D's showMe is called
甚至可以在类定义外部直接调用:
from pkg.A import AA.showMe(d)# A's showMe is called
相当灵活,这都是因为Python本身的语言特性,解释器对实例的调用a.showMe()本来就是通过A.showMe(a)这种方式进行的,所以我们利用这点来“跨mro”调用当然也是可行的。
原则
我们知道,继承存在的最大意义除了代码复用,其最核心的含义是用来明确"IS"关系。
在单继承语言中这种关系很明确,因为只有一个父类,自然就只能是一种东西。但对于Python这种多继承语言,就很麻烦,我们经常会迷失在诸如A(B,C,D,E,F)之类的继承关系中,连A的主体到底是一个什么都很难分辨清楚。
所以虽然多继承的语法本身拥有相当高的自由度,也给代码复用带来很大的便利性,但是我们并不能随意滥用。
在使用中我们需要遵循以下原则:
-
区分接口继承和实现继承。
明确继承主体,在进行多继承时,将主体以外的功能性复用模块(类似接口)定义为“混入”。
关于“混入”可以阅读通过 Python 理解 Mixin 概念。
-
通过名称明确混入。
混入都要统一命名以和继承主体进行区分,比如
ExampleMixin,以Mixin作为后缀是一个比较通用的做法。 -
抽象基类可以作为混入,反之则不行。
对于这点或许理解稍微困难。对于抽象基类来说,因为可以实现代码,所以自然可以作为混入(混入的本质是功能性复用模块)。而反过来,混入并不能起到抽象基类明确“IS”关系的用途。
-
使用聚合类。
这里的聚合类不完全是UML关系中的聚合类。说的是类似以下的类:
class AggregateClass(ParentClass,Exp1Mixin,Exp2Mixin,Exp3Mixin): '''这是一个将主体ParentClass和混入Exp1,Exp2,Exp3捏合在一起的聚合类''' pass在这样的聚合类里,往往只有一个说明字符串,以及
pass语句,没有任何其他实现。这样的聚合类最大的用途就像示例中的说明字符串展示的那样,是把主体基类和其它混入捏合在一起,给其它子类复用带来便利。
-
多用组合少用继承。
这是一条经典的设计模式原则,这里不做过多解释,想了解的可以阅读设计模式 by Python1:策略模式。
这里只是一些基本原则,可能并不完整。
下面用一个简单示例来说明如何使用以上原则:

在这个简单示例中,Person是用来明确“IS”关系的存在,所以是一个抽象基类。而Career同样是明确"IS"关系的存在,所以也是一个抽象基类,但不同的是它是用来明确一些混入的关系。
而对于这个类图,相关职业相比于“Person”显然是一个功能性概念,所以在多继承的时候我们将其定义为混入。
图中的军医Surgeon是一个聚合类,它将Person、SoldierMixin、DoctorMixin捏合成了一个Surgeon,方便子类进行代码复用,比如可以创建Chinese Surgeon或American Surgeon等子类。
混入是一个相对概念,在这个类图中职业是定义为混入,但如果我们创建的是一个职业信息分类系统,和可能就是继承主体,而非混入。
好了,以上就是这篇迟来的笔记的全文,需要说明的是相对于《Fluent Python》原章节,我没有使用“Flask”等框架介绍多重继承的使用原则及相应的优缺点,原因是那样太过庞杂,很难理解。如果对原书感兴趣的可以阅读原文相关章节。
感谢阅读。
虽然天气不那么阴冷了,但写博客依然不是个轻松的活。
