独家 | 10分钟带你上手TensorFlow实践(附代码)
原文链接:点击打开链接
原文链接:点击打开链接
摘要: 这篇TensorFlow教程的目标读者是那些对机器学习有一定基本概念并且想尝试上手TensorFlow的人。首先你需要安装好TensorFlow(可以跟着本教程进行安装http://cv-tricks.com/artificial-intelligence/deep-learning/deep-learning-frameworks/tensorflow/install-tensorflow-1-0-gpu-ubuntu-14-04-aws-p2-xlarge/)。
这篇TensorFlow教程的目标读者是那些对机器学习有一定基本概念并且想尝试上手TensorFlow的人。首先你需要安装好TensorFlow(可以跟着本教程进行安装http://cv-tricks.com/artificial-intelligence/deep-learning/deep-learning-frameworks/tensorflow/install-tensorflow-1-0-gpu-ubuntu-14-04-aws-p2-xlarge/)。 本教程共分为两部分: 第一部分我们会配合代码实例解释基础概念, 第二部分我们会构建一个线性回归模型。
TensorFlow是一个用于数值计算的库,其中数据沿着图(graph)而流动。在TensorFlow中数据用n维数组表示并被称之为Tensors。而图(graph)由数据(也叫Tensors)和数学运算共同组成。
TensorFlow不同于其他编程语言的另一个方面是: 在TensorFlow中无论你要构建什么,首先你需要构思整个蓝图。在创建图的时候,变量并没有被赋值。随后当已经创建了完整的图之后,还需要在一个会话(session)中去运行它,此时图中的变量才会被赋值。稍后还有更详细的介绍。
现在让我们通过动手来学习。运行Python并导入tensorflow:

1. TensorFlow中的图
图是TensorFlow的主干,所有的计算/操作/变量都位于图中。代码中发生的一切都位于TensorFlow提供的一个默认图中。可以通过如下代码访问该图:

你也可以这样得到所有操作的list:
![]()
由于现在图是空的,所以该语句的输出也是空的,即[]。
如果想打印出各操作的名称,用这条语句:
![]()
这回还是空的,等我们在图中加入了操作之后再来执行该语句。
另外,我们也可创建多个图,现在先不细讲。
2. TensorFlow会话
图是用来定义操作的,而操作必须运行在一个会话(session)中,图和会话的创建是相互独立的。可以把图想象成是设计蓝图,则会话就是它的施工地点。
图仅仅是定义了计算或者说构建了设计蓝图。 然而,除非我们在会话中运行图或者图的一部分,否则没有任何变量也没有任何值。
可以这样创建会话:

打开一个会话时,要记得在结尾处关闭。或者可以用python中的with语句块,如此一来,它将会自动被关闭:

在本教程的代码中我们会频繁使用with语句块,我们也推荐你这样操作。
3. TensorFlow中的Tensors
TF将数据保存在Tensors中,它有点像numPy包中的多维数组(尽管它们和numPy数组不同)
常量常量的值不能修改,定义方式如下:

可以看到,不同于Python之类的其他语言,这里并不能直接打印/访问常量的值,除非在会话中运行,再来试一下:
![]()
这回打印了输出结果1.0
变量即Tensors,和其它语言中的变量相似。

变量(顾名思义)和常量不同,能够存储不同的值。然而,在TF中,变量需要分别进行初始化,单独初始化每个变量效率很低。但TensorFlow提供了一次性初始化所有变量的机制,具体方法如下:
对于0.11及更早的tf版本,使用initialize_all_variables()方法:
>>>init_op = tf.initialize_all_variables()
0.12及以后的版本,使用global_variables_initializer():
>>>init_op = tf.global_variables_initializer()
上述代码会把init_op添加到TensorFlow的默认图中。
现在,试图访问刚才定义的变量b之前,先运行一下init_op,打印b输出2.0:

现在可以打印出该图中的全部操作:

这回输出了:
Const
test_var/initial_value
test_var
test_var/Assign
test_var/read
init
如你所见,之前定义过常量a, 所以它被加到了图中。同理,对于变量b而言,许多’test_var’的状态,例如test_var/initial_value,test_var/read等也被加入了图中。你可以利用TensorBoard来可视化整个网络,TensorBoard是一个用于可视化TensorFlow图和训练过程的工具。
占位符占位符,顾名思义表示占位,是指等待被初始化/填充的tensors。占位符被用于训练数据,只有当代码是在会话中运行的时候占位符才会被填充。“喂给”占位符的东西叫做feed_dict。Feed_dict是用于存储数据的(一系列)键值对:
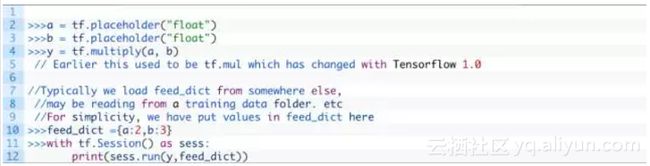
上例输出结果为6.
4. 在TensorFlow中应用设备
TensorFlow具有非常强大的内置功能,可以在gpu, cpu或者gpu集群上运行你的代码。 它为你提供了选项,使你能选择要用来运行代码的设备。 这里不对此进行详细介绍,随后会有单独关于这个主题的教程。先来看一下TensorFlow全貌:

这部分我们会学习线性回归的代码,首先来看几个代码中用到的TensorFlow函数:
创建随机正态分布:
使用random_normal创建服从正态分布的随机值。本例中,w是一个784*10的变量,其中的值服从标准差为0.01的正态分布。
![]()
Reduce_mean:
计算一个数组的均值

输出35
ArgMax:
类似于python中的argmax, 返回沿指定轴方向上,tensor最大值的索引

输出:array([2, 0]), 表示每一行中最大值的索引。
线性回归练习:
问题描述:线性回归中,开始时有很多数据点,我们的任务是用一条直线来拟合这些点。本例中,我们将生成100个点,并拟合他们。
生成训练数据trainX的值位于-1和1之间。
trainY是trainX的3倍外加一些干扰值。
占位符定义两个占位符,用于随后填充训练数据
![]()
线性回归的模型是 y_model = w * x, 我们需要计算出w的值。首先可以初始化w为0来建立一个模型, 并且定义cost函数为(Y – y_model)的平方。TensorFlow中自带了许多优化器(Optimizer),用来在每次迭代后更新梯度,从而使cost函数最小。这里我们使用GradientDescentOptimizer以0.01的学习率来训练模型, 随后会循环运行该训练操作:

目前为止,我们仅仅是定义好了图,还没有任何具体的计算。
TensorFlow的变量还没有被赋值。为了真正运行定义好的图,还需要创建并运行一个会话,在此之前,可以先定义初始化所有变量的操作init:

第一步,在session.run()中调用init完成初始化操作。随后我们通过向feed_dict“喂”数据来运行train_op。迭代完成之后,我们打印出最终的w值,应该接近3。
练习如果你又新建了一个会话,会输出什么结果呢?

将会输出0.0, 这就是符号计算(symbolic computation)的思想, 一旦脱离了之前的会话,所有的操作都不复存在。