python爬虫怎么获取network中的链接_网络爬虫入门之requests 库的基本使用——以亚马逊图书界面为例...
本文作者:赵冰洁,中南财经政法大学金融学院
本文编辑:王子一
技术总编:张馨月
爬虫俱乐部云端课程
爬虫 俱乐部于2020年暑期在线上举办的 Stata与Python编程技术训练营和 Stata数据分析法律与制度专题训练营已经圆满结束啦~应广大学员需求,我们的课程现已在腾讯课堂全面上线,且 继续提供答疑服务 。现在关注公众号并在朋友圈转发推文《 来腾讯课堂学Stata和Python啦 !》或《 8月Stata数据分析法律与制度专场来啦!》,即可获得 600元课程优惠券 ,集赞50个再领 200元课程优惠券 !(截图发至本公众号后台领取)原价2400元的课程,现在只要 1600元 !requests库是我们在使用Python爬虫时经常使用的第三方库,它通过 “发送请求,获取响应” 的过程来自动地帮助我们获取网页信息。我们之前写的爬虫案例基本上都是基于requests库实现,大家如果想找到更多的练手项目,可以进入公众号的主页,在菜单栏-Python-网络爬虫下找到更多的练手项目。不过,对于新手小白来说,这个库该如何使用呢?今天,小编为大家带来手把手教学,一起往下看吧~
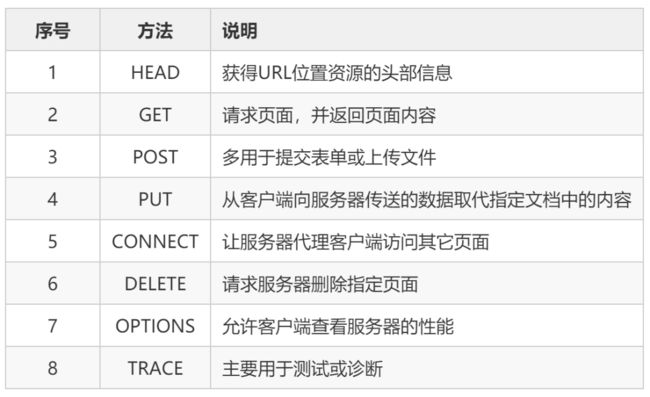
一、网络爬虫原理简介 简单来讲,网络爬虫就是获取网页并提取网页信息的过程。在平时上网的过程中,我们输入url并按下回车,便可得到想要的网页信息。这个过程实质上是浏览器向服务器发送了一个 请求(request),服务器接收后对此做出 响应(response) 并传回给浏览器。在Python中,为了实现自动抓取的过程,我们通常使用 requests 库来模拟发送请求的过程。 客户端发出的请求主要由四部分组成,分别为
客户端发出的请求主要由四部分组成,分别为
请求网址 、
请求方法 、
请求头 以及
请求体 。 对
请求方法 而言,最常见的两种方式是get与post,其中get方法是通过在url中拼接字段发送给服务器以获得响应。post请求方式的使用和get请求方式的区别在于它传递参数的方式是通过表单来向服务器传递信息。除此之外,还有一些其他的请求方法, 如下表所示:

与此同时,我们还可以在该界面查看到网页的请求头和请求体信息。在写爬虫时,我们通常需要加入请求头的信息以更好的模拟网页请求的过程,在一定程度上防止触发网页的反爬机制。请求体中通常包含的是表单信息,对以get方式请求的网页,该部分的内容为空。
二、requests库的基本使用
1.请求网页 我们进行爬虫的第一步是根据网页的请求方式来发送请求,最常用的方式为requests.get( ) 、requests.post( )这两种。对于requests.get( ),我们通常需要传入网址和请求头信息,而对于requests.post( ) ,我们通常还需要传入请求体中的内容。更具体的语法说明如下: (1)get()方法requests.get(url,params = None,**kwargs)- url : 拟获取页面的url链接
- params : 指在url中增加的额外参数
- **kwargs : 指控制访问的参数,常用的包括headers(请求头)、timeout(超时时间)等,完整介绍可参考官方文档https://requests.readthedocs.io/en/master/。
requests.post(url,data = None,json = None, **kwargs)- url : 拟获取页面的url链接
- data : 字典、字节序列或文件对象作为Requests的内容
- json : JSON格式的数据作为Requests的内容
- **kwargs : 控制访问的参数

更多的有关于HTTP响应的状态码可以参照《Requests get爬虫之设置headers》。
三、爬虫案例
 在爬取之前,我们先导入
在爬取之前,我们先导入
requests 模块,并获取页面的url链接:
import requestsurl = "https://www.amazon.cn/dp/B00DNX7CAM"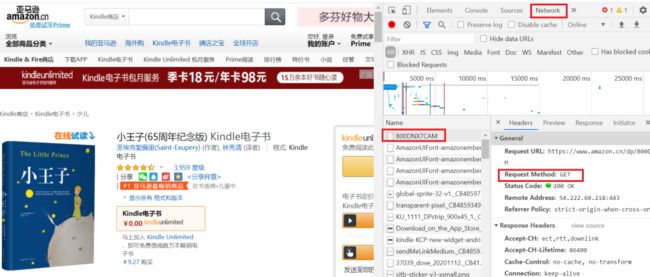 如果直接使用requsts.get(url)将无法获取到我们需要的网页信息,如下所示:
如果直接使用requsts.get(url)将无法获取到我们需要的网页信息,如下所示:
import requestsurl = "https://www.amazon.cn/dp/B00DNX7CAM"r = requests.get(url)r.status_coder.request.headers ,我们可以尝试寻找出现错误的原因:
 如图所示,红色标框表明亚马逊的服务器识别出了本次请求由Python中的requests发起,因而拒绝了此次访问。 因此,为了防止网页识别出该请求由Python发起,通常我们加入请求头的部分信息来进行“伪装”,以模拟浏览器向服务器发送请求。
如图所示,红色标框表明亚马逊的服务器识别出了本次请求由Python中的requests发起,因而拒绝了此次访问。 因此,为了防止网页识别出该请求由Python发起,通常我们加入请求头的部分信息来进行“伪装”,以模拟浏览器向服务器发送请求。
import requestsurl = "https://www.amazon.cn/dp/B00DNX7CAM"headers = { "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Accept-Encoding":"gzip, deflate, br", "Accept-Language":"zh-CN,zh;q=0.9", "Cache-Control":"max-age=0", "Connection":"keep-alive", "downlink":"5.7", "ect":"4g", "Host":"www.amazon.cn", "rtt":"100", "Sec-Fetch-Dest":"document", "Sec-Fetch-Mode":"navigate", "Sec-Fetch-Site":"none", "Sec-Fetch-User":"?1", "Upgrade-Insecure-Requests":"1", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36"}r = requests.get(url, headers = headers) ### 使用 GET 请求方式访问网页信息,并添加已修改的 headers 信息r.status_coder.encoding
r.text 查看返回的内容:
print(r.text) 基于此,我们便可通过使用xpath来完成对关键信息的提取,代码如下:
基于此,我们便可通过使用xpath来完成对关键信息的提取,代码如下:
#导入需要使用的库from lxml import etreeimport pandas as pdimport retree = etree.HTML(r.text) #根据xpath定位所需信息title_xpath = '//*[@id="productTitle"]/text()' price_xpath = "//span[@class='a-size-medium a-color-price']/text()"author_xpath = '//*[@id="bylineInfo"]/span[1]/a/text()'#对信息进行提取title = tree.xpath(title_xpath)title = [re.sub("\s","",t) for t in title]price = tree.xpath(price_xpath)price = [re.sub("\s","",p) for p in price]author = tree.xpath(author_xpath)#将结果导入至dataframedf = pd.DataFrame(data = [title,author,price]).Tdf.columns = ["书名","作者","价格"]df 以上就是小编对于 requests 库的简要介绍及其应用,大家也来动手试试吧~
以上就是小编对于 requests 库的简要介绍及其应用,大家也来动手试试吧~
 对我们的推文累计打赏超过10
00元,我们即可给您开具发票,发票类别为“咨询费”。
用心做事,不负您的支持!
往期推文推荐 reduce()函数和filter()函数闪亮登场 “环环”入扣之foreach命令
对我们的推文累计打赏超过10
00元,我们即可给您开具发票,发票类别为“咨询费”。
用心做事,不负您的支持!
往期推文推荐 reduce()函数和filter()函数闪亮登场 “环环”入扣之foreach命令
统计年鉴数据整理小技巧
Seminar | 作为飞行员,我比别的CEO多了什么?
利用TensorFlow构建前馈神经网络
推文合集(1)| Stata学习者必看的n篇推文!
Seminar | 诚信的价值
利用tushare获取股票数据及实现可视化
从Excel到Stata的“摆渡车”——import excel命令
光阴十载,见证了《经济研究》中的“高被引”
利用tushare获取股票数据
在Python中实现Stata的stack功能
这些年,经管类C刊都在研究什么?
Seminar | 眼见为实吗?高管面部可信度、审计师任期与审计费用
Seminar | 恐怖袭击与CEO薪酬
代码补全,主题更换,Jupyter Notebook原来可以这样用?
【爬虫实战】“双十一”微博热搜实时跟进
Stata中的数值型变量分类神器--recode
fs命令——我们的小帮手【邀请函】听说你还在为处理表格头大?
用stack取代excel的数据重整操作吧 关于我们微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。 投稿邮箱:[email protected] 投稿要求:1)必须原创,禁止抄袭;2)必须准确,详细,有例子,有截图;注意事项:1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。2)邮件请注明投稿,邮件名称为“投稿+推文名称”。3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
