最近在学习大数据,在自己本地装了三个虚拟机,学习搭建hadoop集群。记录下过程,方便日后查看。
1.准备工作
VMware-workstation-full-12.1.0,Centos 7_x64镜像,jdk_1.8.0_linux_x64,hadoop_2.7.7.
虚拟机安装步骤参考:https://www.cnblogs.com/tony-hyn/p/9677902.html
jdk刚开始从Oracle官网下载,结果使用tar -zxvf 解压时一直报错,后来查阅资料,使用wget 方法直接下载到linux中.
参考资料:https://blog.csdn.net/u011365831/article/details/79301188
hadoop下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
使用tar -zxvf 解压hadoop时也报错,将tar.gz后缀修改为.tar,再次解压搞定。
2.搭建集群
2.1 建议在安装系统镜像时顺便配置下网络,修改下hostname.或者单独修改每台机器的hostname
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=Mage1
2.2 在命令行输入: vi /etc/hosts
添加3台服务器的节点名信息
192.168.126.133 node1
192.168.126.134 node2
192.168.126.135 node3
2.3 关闭防火墙
查看防火墙状态
firewall-cmd --state
停止firewall
systemctl stop firewalld.service
禁止firewall开机启动
systemctl disable firewalld.service
2.4 时间同步
命令行输入:yum install ntp 下载ntp插件 ,
下载完成后 命令行输入:ntpdate -u ntp1.aliyun.com
2.5 配置ssh无密码访问
使用root用户创建hadoop用户并分配到hadoop组,如下图所示以test用户为例:

将test用户赋予root权限: 修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
test ALL=(ALL) ALL
修改完毕,现在可以用test 帐号登录,然后用命令 sudo ,即可获得root权限进行操作。
在每个节点上分别执行:ssh-keygen -t rsa 一直按回车直到生成结束
执行结束之后每个节点上的/hadoop/.ssh/目录下生成了两个文件 id_rsa 和 id_rsa.pub
其中前者为私钥,后者为公钥
在主节点上执行:
命令行输入:cp id_rsa.pub authorized_keys
将子节点的公钥拷贝到主节点并添加进authorized_keys
将两个子节点的公钥拷贝到主节点上
分别在两个子节点上执行:
scp /hadoop/.ssh/id_rsa.pub hadoop@node1:/hadoop/.ssh/id_rsa_node2.pub
scp /hadoop.ssh/id_rsa.pub hadoop@node1:/hadoop/.ssh/id_rsa_node3.pub
然后在主节点上,将拷贝过来的两个公钥合并到authorized_keys文件中去
主节点上执行:
cat id_rsa_node2.pub>> authorized_keys
cat id_rsa_node3.pub>> authorized_keys
将主节点的authorized_keys文件分别替换子节点的authorized_keys文件
主节点上用scp命令将authorized_keys文件拷贝到子节点的相应位置
scp authorized_keys hadoop@node2:/hadoop/.ssh/
scp authorized_keys hadoop@node3:/hadoop/.ssh/
2.6 配置jdk
配置环境变量, 编辑~/.bash_profile文件:
vi ~/.bash_profile
在文件末尾添加以下代码:
export JAVA_HOME=实际路径
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
source ~/.bash_profile,使环境变量生效
2.7 安装配置hadoop
配置环境变量, 编辑~/.bash_profile文件:
vi ~/.bash_profile
在文件末尾添加以下代码:
export HADOOP_HOME=实际路径
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bash_profile,使环境变量生效
配置hadoop配置文件
需要配置的文件的位置为 hadoop路径/etc/hadoop,需要修改的有以下几个文件:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
其中hadoop-env.sh和yarn-env.sh里面都要添加jdk的环境变量
修改hadoop-env.sh
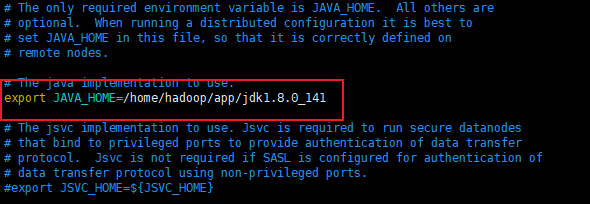
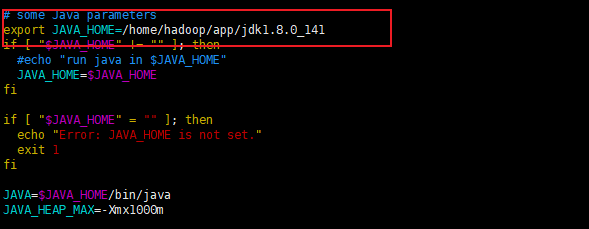
修改yarn-env.sh
修改core-site.xml(加粗斜体部分需要按照实际修改,提前创建所需目录)
fs.defaultFS
hdfs://node1:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/home/hadoop/app/hadoop-2.7.7/temp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
修改hdfs-site.xml (加粗斜体部分需要按照实际修改, 提前创建所需目录 )
dfs.namenode.secondary.http-address
node1:9001
dfs.namenode.name.dir
file:/home/hadoop/app/hadoop-2.7.7/namenode
dfs.datanode.data.dir
file:/home/hadoop/app/hadoop-2.7.7/data
dfs.replication
2
dfs.webhdfs.enabled
true
dfs.permissions
false
dfs.web.ugi
supergroup
注意要将mapred-site.xml.template重命名为 .xml的文件 mv mapred-site.xml.template mapred-site.xml,并修改
(加粗斜体部分需要按照实际修改)
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node1:10020
mapreduce.jobhistory.webapp.address
node1:19888
修改yarn-site.xml (加粗斜体部分需要按照实际修改)
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
node1:8032
yarn.resourcemanager.scheduler.address
node1:8030
yarn.resourcemanager.resource-tracker.address
node1:8031
yarn.resourcemanager.admin.address
node1:8033
yarn.resourcemanager.webapp.address
node1:8088
修改slaves
node1
node2
node3
将hadoop与环境变量scp 到其他主机
格式化主节点的namenode,进入hadoop目录然后执行:
./bin/hadoop namenode -format
3 启动hadoop
start-all.sh
主节点以及从节点进程


