KMP算法背后的细节与难点
本文是笔者在复习数据结构时的笔记,在初次接触KMP算法时觉得理解起来困难重重,在翻阅网上众多自称“通俗易懂地解释KMP算法”的文章后,发现大多文章都只是粗浅地停留在对比KMP和暴力匹配算法的不同,而没有深入地去探讨算法细节中关于next数组的计算和推导、next数组应如何用代码实现等问题。所以笔者在花费大量时间思考并最终理解后,希望通过这篇文章讲清和讲透KMP算法其中的细节。
在进入正题之前,让我们先说明几个概念:
主串:若我们称A = 'hello world’为主串
子串:则我们可以称B = 'hello’或C = ‘world’ 等为A的子串,即从A中取出来的部分字符串我们都可以称为子串
模式串:子串也可以称为模式串,但我们一般将要与主串进行比较匹配的字符串为模式串。
在本文所用到的字符串都是用字符数组来存储的,而且字符串第一个下标为1而不是0.
首先我们说一下什么是模式匹配。简单来说,模式匹配就是指判断一个模式串是否是一个主串的子串,即主串是否包含该模式串,如果是,返回该模式串在主串中的位置(即第一个字符的位置)。我们先看下面一个例子,已知一主串为 ‘helloworld’,模式串为 ‘owo’,由下图可知,模式串与主串匹配的结果再5这个位置,那么在模式匹配算法完成后会返回 5 作为结果,这应该没什么问题,重点是应该怎么去确定 ‘owo’ 在 ‘helloworld’ 中的位置。

第一种方法称为暴力匹配法。即我们将模式串的第一个字符分别依次与主串中的每一个字符匹配一次,直到出现模式串的每一个字符与主串的每一个字符完全匹配为止。

由上图我们可以看到,我们依次拿模式串与主串进行匹配,直到第五次才匹配成功,假设主串的长度为m,模式串的长度为n,那么暴力匹配算法的最坏时间复杂度为O(m*n),这样的结果是不太理想的,因为在上图的匹配中,在第一次匹配的时候我们其实已经明确子串 ‘hel’ 中不存在 'owo’其中任一个字符,换言之,第二次和第三次匹配其实可以完全省去的。
我们再来看另外一个例子。模式串 ‘good’ 与 主串 ‘googlegood’ 进行第一次匹配时,当匹配到主串第四个位置 ‘g’ 时发现 ‘g’ 和 ‘d’ 不相等并进行第二次匹配,于是主串的指针i从1走到4后重新回溯到2的位置。但是我们很清楚地看到,第二到第三次匹配其实都是没有必要进行的,因为我们在第一次匹配时已经有了一个短暂的记忆,即第二和第三个字符的首字母都是 ‘o’ 而不是 ‘g’ 。所以暴力匹配法的一个最大缺点就是主串指针i在每一次匹配失败后都会回溯,即便我们已经知道了回溯后匹配也不成功。而KMP算法完美地解决了这个缺点,所以接下来我们就开始介绍KMP算法的思想和细节。

KMP算法由D.E.Knuth,J.H.Morris和V.R.Pratt三人共同提出,所以取他们名字的首字符组成了KMP。在进行深入地探讨KMP算法的相关细节之前,我们再来说明几个概念。
前缀:前缀指除最后一个字符之外,字符串的全部头部子串
后缀:除第一个字符外字符串的全部尾部子串
部分匹配值(partial match):字符串前缀和后缀相等的最长长度,也可简称为PM
定义完我们来举几个例子说明一下,以字符串 ‘ababa’ 来举例:
- 对于 ‘a’ :它没有前缀也没有后缀,PM=0。
- 对于 ‘ab’ :它的前缀有{a},后缀有{b},PM=0
- 对于 ‘aba’ :它的前缀有{a,ab},后缀有{a,ba},PM=1,因为前后缀相等的长度最长的串’a’长度为1
- 对于 ‘abab’ :它的前缀有{a,ab,aba},后缀有{b,ab,bab},PM=2,因为前后缀相等长度最长的串’ab’长度为2
- 对于’ababa’ :它的前缀有{a,ab,aba,abab},后缀有{a,ba,aba,baba},PM=3,因为前后缀相等的长度最长的串’aba’长度为3.
综上分析,我们可以得出对于字符串’ababa’它的部分匹配值分别是:00123,那这个部分匹配值在我们进行模式匹配的时候可以起到一个什么作用呢?继续上例子:
在上面的例子中,在第一次 ‘good’ 和 ‘googlegood’ 进行第一次比较后,又进行了两次在我们看来毫无意义的比较,那我们是否可以直接让 ‘good’ 去和 ‘googlegood’ 中的第四个字符 ‘g’ 去比较呢?
这里注意一下,当我们人眼直接望去这两个字符串时,我们可以很清楚地发现 ‘good’ 这个子串在主串的末尾,从而前面的六次比较在我们看来都是无意义的。但是这并不是计算机所处理信息的方式,计算机一次只可以读取一个字符,在第一次匹配的时候,它只观测到了前三个字符还有知道第四个字符不是 ‘d’,所有计算机在处理问题的时候只能在已知的信息范围内处理问题。
好,回到我们的例子上来,前面讲到了第一次匹配,流程如下图:

在第一次匹配的过程中,主串指针i和模式串指针j分别移动,当移动到第四个位置时发现 ‘g’ 不等于 ‘d’ ,如果是在暴力匹配的情形下,此时i重新回到主串第二个位置,也就是 ‘o’ ,与模式串从第一个位置 ‘g’ 开始进行新一次的匹配。
前面也提过,导致暴力匹配算法时间开销大的原因就是主串指针的回溯,那如果我们可以让主串指针i不回溯,在匹配的整个过程中一直往前移动,我们就可以省下很多的时间。那么,以计算机的视角来看待这个问题:
已知前三个字符匹配成功,第四个字符与模式串字符不匹配,第四个字符后面的未知,而在经过比对的过程中,发现第二和第三个字符都不与模式串的第一个字符 ‘g’ 匹配,那么此时我是要继续按照i=2, i=3, i=4这样的顺序匹配下去呢,还是直接让模式串的首字符去和主串的第四个字符比对? 答案肯定是后者,因为省去了无意义的匹配,但考虑更多的情况,我们要怎么让计算机知道它在不同的情形下应让模式串移动到哪个位置与主串比较呢?这时部分匹配值便派上了用场。
这里我们先上一个公式:模式串移动位数 = 已匹配字符数 - 部分匹配值,后面再来解释这个公式代表什么意思。模式串 ‘good’ 的部分匹配值为0000,这个留给读者动手做,非常简单,这里就不再细讲。已匹配到的字符共三个,所有模式串 ‘good’ 移动的位数应该是 3 - 0 = 3,此时应该让模式串的第一个字符与主串的第四个字符进行匹配。
好了,至此我们已经大概将KMP算法的流程给过了一遍,不知道大家有没有看懂:
- 求出模式串的部分匹配值
- 在模式串与主串匹配的过程中依据部分匹配值计算如果匹配失败下一次模式串应该移动多少位去和主串匹配
- 不断重复第二步直到匹配成功/失败
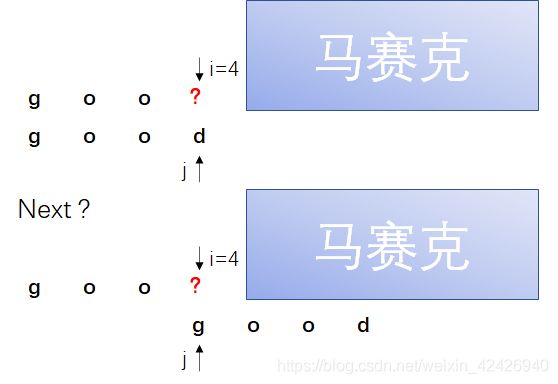
至此KMP算法的基本思想都已经讲完啦,但是KMP算法实现的技术难点才刚刚开始~ 我们前面讲过部分匹配值指的是一个串前缀后缀相等部分的最大长度是多少,但是当我们前面在使用部分匹配值时我们却是给了一串数字。比如前面我们说 ‘good’ 对应的PM为0000,'ababa’的PM为00123,那这串数又是代表什么呢?在KMP算法的实现中我们将其称为next数组,拿 ‘ababa’ 举例:

对应于模式串 ‘ababa’ 的next数组为:[0,0,1,2,3]。我们可以这样来理解这个数组,当我们的指针j停留在某一个位置时发现模式串字符与主串字符不等,我们去找到已匹配字符串的最后一位的PM值,利用公式模式串移动位数 = 已匹配字符数 + 部分匹配值来计算出模式串应该移动的位数等于多少。比如:

现在我们再重头来捋一下上面图中的整个过程:
第一次匹配:在i=5的位置主串与模式串匹配不上,这时候寻找已匹配子串共四个字符的最后一个字符也就是 ‘b’ 在next数组中的PM值为2,我们让模式串向右移动4-2=2个位置,并保持主串指针i不动。
第二次匹配:我们可以看到经过第一次按照PM值计算出来的位数移动后,我们直接将模式串的 ‘ab’ 与主串的 ‘ab’ 对齐,并从比较主串的第五位和模式串的第三位是否相等开始匹配。之所以能这样是因为前面在已经与主串匹配成功的部分模式串字符其实就是模式串的子串,我们只不过是在寻找已匹配成功的模式串的相等前后缀而已。(可能有点绕口,但也只能这样表达了,希望读者可以好好地琢磨理解,第一次看不一定可以看懂,慢慢思考动笔在纸上画图可以加深理解)。此时在i=5这个位置匹配失败,我们寻找已匹配子串的最后一个字符的PM值为0,计算模式串移动位数为2,并保持主串指针i不动
第三次匹配:此时我们来到了第三次匹配,注意!此时主串与模式串在模式串的第一个字符就匹配失败了,此时需要主串指针i和模式串同时向右移动一位。
第四次匹配:成功啦~
如果按照暴力匹配方式的话,我们需要六次才可以匹配成功,当然碰见更为复杂的串自然所需时间会更高。
希望通过这个例子,读者可以加深对KMP算法流程、部分匹配值(PM)、next数组以及模式串的移动有了一个更加直观和深刻的理解但真正的难点其实还没到,请大家务必再坚持一会儿~刚刚讲的整个流程其实有两点需要我们注意:
首先,模式串并不会真的移动,这里只是为了方便大家理解在逻辑上实现的移动,但是模式串所存储在内存中的物理结构是不会移动到任何地方的。
那这里又代表的是什么呢?其实这里代表的是指向模式串的指针j的移动,刚刚一直在将主串指针i而一直忽略了模式串指针j,不知道读者有没有发现~ 当我们在模式串的第一个字符便匹配失败时,我们会让主串指针i和模式串指针j共同向右移动一位。**当我们的主串和模式串有至少一个匹配字符时,若遇到匹配失败的字符,便让主串指针i仍指向该字符,而模式串指针j指向已匹配字符串最后一个字符的`PM+1’个位置。**我们再拿上面的例子说明一下:在第一次匹配中,已匹配字符串的最后一个字符 ‘b’ 的PM为2,所有此时模式串指针j应指向模式串的第(2+1=3)个字符,即 ‘a’ ,并开始与主串进行比较。那背后的原理其实也很简单,PM所指的是串中前缀和后缀相等的最大长度,而已匹配部分其实是模式串的子串,是模式串自身的一部分,如果我们可以保证模式串的部分前缀和其部分后缀是相等的话,那么我们只需从这部分相等前缀后一个字符开始比较即可,前面的都可以略过。(这段话建议读者结合图片理解并思考,其实是不难理解的。)
其次,假如我们在j=3的位置匹配失败了,但我们却需要去找next[2]的PM值再加一最后赋值给模式串指针j,这在实现上就会比较麻烦,所以我们首先将next数组的所有值往右移动一位,然后再加1,得到一个新的next数组,这个数组里的元素 next[j] 表示当我们在第j个位置匹配失败时,我们的指针j应该移动到模式串的next[j]个位置重新与主串指针i 进行比较,拿上面 ‘ababa’ 的next数组举例:
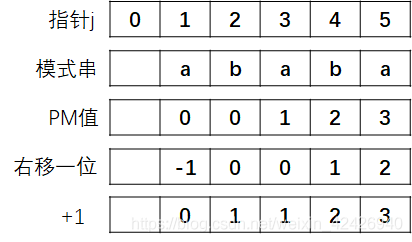
看到这里可能有读者会问,我们在原始的next数组中将所有的PM值向右移动一位时最右边的PM值就因溢出而被舍弃了,这样不会有什么问题吗?这里主要是因为,第j个位置的PM值是当j+1个位置匹配失败时才需要派上用场,而例子中的模式串总共就五个字符,所以不存在第6个字符匹配失败,自然j=5对应的PM也就没有存在的意义了。
至此,我们已经详细地说明了KMP算法流程、next数组在模式串"移动"过程中所起的作用、原理、以及如何生成一个我们想要的简洁明了方便代码实现的next数组,下面要讲的才是本文的重难点,估计也是全文最难理解的地方,即如何推导next数组的一般式。我们从本文一开始到现在,对于next数组都是手动计算,却从来没有思考过如何用计算机来实现这一过程,那下面的部分就会着重探讨如何推导next数组的一般式~
在上述的分析中其实我们已经看过了三种情况,分别是:
- 在主串指针i 与模式串指针j 所指向的字符匹配失败之前,主串模式串已经存在匹配成功的子串,而且这部分子串有相等的前后缀,比如第一次匹配,此时next[j] (在第一次匹配中是next[5]应该是2+1=3)应该为已匹配子串的部分匹配值+1。(忘记定义的读者可以回去看看部分匹配值的定义)

- 第二种情况便于第一种情况类似,只不过已匹配子串部分没有相等的前后缀,比如第二次匹配,这时我们不需要去计算什么PM值,只需要让next[j]=1便可。(在第二次匹配中是next[3]=1)
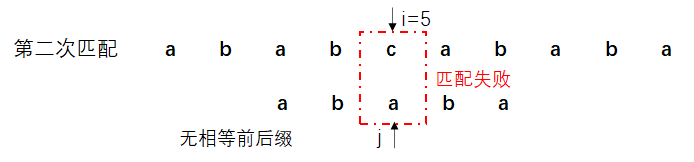
- 第三种情况便是模式串从第一个字符就与主串匹配失败了,这时我们让next[j]=0,之后再让i++, j++,以使主串指针i和模式串指针j同时往前进一位。比如第三次匹配:
这里之所以让next[j]=0,让j指向next[j],之后再进行i++和j++只是为了实现起来方便而已。本质上第一次匹配就失败的话,模式串指针仍然是指向第一个字符的。

相信到这一步,读者对上面的next数组可能存在的三种情况都有所了解了,那么我们可以进一步来总结next数组存在的形式,先来探讨第一种情况:
设 主 串 为 S 1 S 2 . . . S n , 模 式 串 为 P 1 P 2 . . . P m , 当 主 串 指 针 i 和 模 式 串 指 针 j 所 指 字 符 匹 配 失 败 时 , 设 存 在 { k } ∈ ( 1 , j ) 使 得 ′ P 1 P 2 . . . P k − 1 ′ = ′ p j − k + 1 P j − k + 2 . . . P j − 1 ′ 则 n e x t [ j ] = m a x { k } 设主串为S_1S_2...S_n,模式串为P_1P_2...P_m,当主串指针i和模式串指针j所指字符匹配失败时,\\设存在\{k\}\in(1,j)使得'P_1P_2...P_{k-1}' = 'p_{j-k+1}P_{j-k+2}...P_{j-1}'\\则next[j]=max\{k\} 设主串为S1S2...Sn,模式串为P1P2...Pm,当主串指针i和模式串指针j所指字符匹配失败时,设存在{ k}∈(1,j)使得′P1P2...Pk−1′=′pj−k+1Pj−k+2...Pj−1′则next[j]=max{ k}
上面的定义应该没啥问题吧,意思其实就是当主串与模式串在第j个字符匹配失败时,如果是第一种情况的话,已匹配字符串中可能存在若干对前后缀相等的子串,此时我们把前后缀相等的最长长度作为我们的PM值,并通过之前提到的PM+1计算得到的K作为我们的next[j]。
那下面两种情况就更好说了,如果是第三种情况,我们直接让next[j]=0;其他的就让next[j]=1,即模式串指针指向模式串第一个字符,总结来说有下面这个表达式:
n e x t [ j ] = { 0 , j = 1 m a x { k } , 当 { k } 中 元 素 不 为 0 也 不 为 空 1 , 其 他 情 况 next[j]=\left\{ \begin{aligned} & 0 , & j=1 &\\ & max\{k\}, & 当\{k\}中元素不为0也不为空 \\ & 1, & 其他情况 \end{aligned} \right. next[j]=⎩⎪⎨⎪⎧0,max{ k},1,j=1当{ k}中元素不为0也不为空其他情况
由上面这个式子我们知道next数组其实是一个关于j的函数,它所代表的意思是当模式串的第j个字符与主串匹配失败时,我们应让模式串指针j移动到哪一个位置进行下一次比对。但是我们最终想做的不是仅仅得到这个表达式,而是找到一种可以推导next[j]的值的算法。接下来的部分,我们会试着来推导这样一种计算next[j]的算法。
当j=1的时候,next[1]=0,这我们在上面提过了,因为在第一次匹配就失败的情况下,我们需要让主串指针i向前移动一位,并且保持模式串指针仍指向第一个字符。
当j=2的时候,即模式串与主串在第二个字符就匹配失败了,那已匹配成功的只有一个字符,一个字符是没有前后缀自然就没有PM了,所以此时next[2]=1。
那么再然后呢?
我们来换一个思路,与其从j=1,2,3…… 一个一个求值,不如直接假设我们已知next[j]的值,现在的问题是求解next[j+1]为多少?
令next[j]=k,则k表示当模式串与主串在模式串的第j个字符匹配失败后应将k赋值给模式串指针j,即令j=k,然后再用j和主串指针i进行下一轮的匹配。由图可知,此时子串 P 1 … … P k − 1 P_1 ……P_{k-1} P1……Pk−1与 P j − k + 1 … … P j − 1 P_{j-k+1}……P_{j-1} Pj−k+1……Pj−1是相等的,且长度都为k-1。
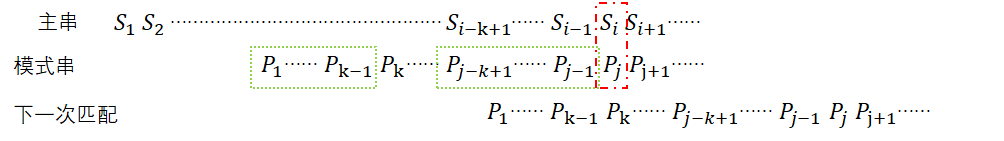
那当我们想求next[j+1]时候,我们面临两种情况:
如果此时 P J = P K P_J=P_K PJ=PK的话,那我们直接让next[j+1]=next[j]+1就可以了,这是最理想的一种情况。
如果 P J ≠ P K P_J\not=P_K PJ=PK的话,那么我们需要做的就是在中 P 1 … … P k P_1 ……P_{k} P1……Pk寻找一个长度更短的前缀 P 1 … … P k ′ P_1 ……P_{k'} P1……Pk′去和 P j − k + 1 … … P j P_{j-k+1}……P_j Pj−k+1……Pj的后缀匹配上,从而我们可以令 n e x t [ j + 1 ] = k ′ + 1 next[j+1]=k'+1 next[j+1]=k′+1 。那寻找这样一个符合条件的前缀可以不停地让 P 1 … … P k P_1 ……P_k P1……Pk向右移动并观察是否存在一个 P 1 … … P k ′ P_1 ……P_k' P1……Pk′ 可以和 P j − k ′ + 1 … … P j P_{j-k'+1}……P_j Pj−k′+1……Pj 匹配上,但这样的一种操作方式仿佛又回到了暴力匹配的年代…
再仔细想一想,我们是否可以把找寻一个 P 1 … … P k ′ P_1 ……P_{k'} P1……Pk′ 和 P j − k ′ + 1 … … P j P_{j-k'+1}……P_j Pj−k′+1……Pj 匹配上的问题转换成一个模式匹配的问题?我们此时面临的问题就是 P k P_k Pk与 P j P_j Pj不相等,那么我们可以通过令 k ′ = n e x t [ k ] k'=next[k] k′=next[k]来让 P 1 … … P k ′ − 1 P_1……P_{k'-1} P1……Pk′−1与 P j − k ′ + 1 … … P j − 1 P_{j-k'+1}……P_{j-1} Pj−k′+1……Pj−1对齐,并比较 P k ′ P_{k'} Pk′与 P j P_{j} Pj是否相等,若相等,则我们让 n e x t [ j + 1 ] = k ′ + 1 next[j+1]=k'+1 next[j+1]=k′+1即可。(之所以可以这么做是因为 P 1 … … P k ′ − 1 P_1……P_{k'-1} P1……Pk′−1与 P 1 … … P k − 1 P_1……P_{k-1} P1……Pk−1相等,而 P 1 … … P k − 1 P_1……P_{k-1} P1……Pk−1与 P j − k ′ + 1 … … P j − 1 P_{j-k'+1}……P_{j-1} Pj−k′+1……Pj−1相等。)

若 P k ′ P_{k'} Pk′与 P j P_{j} Pj仍不相等,则我们继续令 k ′ = n e x t [ k ′ ] = n e x t [ n e x t [ k ] ] k'=next[k']=next[next[k]] k′=next[k′]=next[next[k]]并且继续判断 P k ′ P_{k'} Pk′是否等于 P j P_j Pj。那到了最后就一定会出现一个k’使得 P k ′ P_{k'} Pk′等于 P j P_j Pj吗,那也不一定…如果不存在这样一个k’时,我们会直接让 n e x t [ j + 1 ] = 1 next[j+1]=1 next[j+1]=1。至今为止,我们就彻底地将next数组推导的过程给讲明白啦~ 下面给一段C++的代码实现,逻辑已经在上面讲得很清楚了,相信代码阅读起来没有什么特别大的障碍。
//本文定义字符串的方式是设定一个字符串结构,如下:
#define MAXLEN 255 //这个数可以是任意的
typedef struct{
char ch[MAXLEN];
int length; //串的实际长度
}SString;
//如何求模式串的next数组?
void get_next{
SString T, int next[]}{
int i=1, j=0;
next[1]=0;
while(i<T.length){
if(j==0||T.ch[i]==T.ch[j]){
i++;
j++;
next[i]=j;
}
else
j=next[j];
}
}
上面这段求next数组通式的代码在第一次看肯定会有很多疑问,所以我用上面的 ′ a b a b a ′ 'ababa' ′ababa′这个例子画了一张步骤图,大家可以对照着这张图来阅读这段代码,相信可以帮助你减少更多理解的时间。

//KMP算法如何实现?
int Index_KMP(SString S, SString T, int next[]){
int i=1, j=1;
while(i<=S.length&&j<=T.length){
if(j==0||S.ch[i]==T.ch[j]){
i++;
j++;
}
else
j=next[j];
}
if(j>T.length)
return i-T.length;
else
return 0;
}
最后在结尾我们在提及一下如何改进KMP算法,已知若主串的 S i S_i Si与模式串的 P j P_j Pj匹配失败后,接下来理应是 S i S_i Si与 P n e x t [ j ] P_{next[j]} Pnext[j]进行比对,那如果此时出现一个情况就是 P n e x t [ j ] = P j P_{next[j]}=P_j Pnext[j]=Pj,那么这样的比对是没有意义的,所以要解决这个问题,我们只需要再next数组的推导中加一次判断即可,即若 P n e x t [ j ] = P j P_{next[j]}=P_j Pnext[j]=Pj,则继续让 j = n e x t [ j ] j=next[j] j=next[j],直到 P n e x t [ j ] ≠ P j P_{next[j]}\not=P_j Pnext[j]=Pj为止。
//我们将改进完的next数组称为nextval[]
void get_nextval(SString T, int nextval[]){
int i=1, j=0;
nextval[1]=0;
while(i<T.length){
if(j==0||T.ch[i]==T.ch[j]){
i++;
j++;
if(T.ch[i]!=T.ch[j])
nextval[i]=j;
else
nextval[i]=nextval[j];
}
else
j=nextval[j];
}
}

至此本文已接近尾声,KMP算法对初学者而言难度还是比较大的,主要是难在理解上,所以还需要反复地琢磨和理解,才可以真正弄懂这个算法的思想和实现方式。有什么问题欢迎评论区或者私信交流哦!
完~