关于缺陷自动修复的一些思考
新的财年开始了,每个团队都在做新年的计划。每当做计划,就有对于需求是不是真需求的讨论。
但是对于bug自动修复技术来说,从来不需要讨论为什么要做这个事情。需要讨论的从来是如何做到。我用两句话来总结:
- 需求是真需求
- 困难是真困难
反映在学术界的论文上,针对bug自动修复和主要相关领域的综述每隔一两年就要来一拨。像潮汐一样,被需求卷起,又被拍散在困难的沙滩上。

第一类困难:靠人工写规则为什么走不通?
说起修bug,几乎每个开发同学都有话说。要实现bug的自动定位与修复,也基本上每个同学都有自己的想法。直觉上,这也不是太复杂的事情,将每一个或者是每一类问题定义成一系列的模板或者规则,然后照方抓药就好了,不是么?
我们将上面的方法起个名字叫做规则方法吧。规则方法有三种好处:
- 入门门槛低,至少不会上来就被劝退
- 可解释性强,讲不清楚的规则写都写不出来
- 便于协同作战,可以拆解给团队进行合作
那么,通过积累足够的人手,写足够多的规则,是不是就可以解决bug自动定位和自动修复呢?
答案有两个:理论上做不到,工程上也做不到。
理论上为什么做不到呢?
我们可以用宏观和具体的两个定理来证明做不到。

首先是哥德尔不完备性定理,它是说蕴含了皮亚诺算术公理的一致系统是不完备的。翻译成人话,就是凡是能表示自然数的系统,都有定理不能被证明。不管是后端用的Java还是前端用的javscript,都可以表示自然数系统,所以都肯定有语句是不能被判定的。
如果有同学想理解更透彻一点的话,我们介绍下皮亚诺算术公理,它有5条内容;
- 第一,0是一个自然数
- 第二,任何自然数n都有一个自然数Suc(n)作为它的后继
- 第三,0不是任何自然数的后继
- 第四,后继函数是单一的,即,如果Suc(m)=Suc(n),则m=n.
- 第五,令Q为关于自然数的一个性质。如果
- 0具有性质Q
- 并且 如果自然数n具有性质Q,则Suc(n)也具有性质Q
- 那么所有自然数n都有性质Q
有了上面的5条公理,我们就可以定义加法和乘法两种操作了:
- 加法:对于任何自然数n和m:
- n + 0 = n
- 并且 n + Suc(m) = Suc(n + m)
- 乘法:对任何自然数n和m:
- n * 0 = 0
- n * Suc(m) = (n * m) + n
我们可以通过自动定理证明器证明皮亚诺的乘法与我们在自然数上的乘法是一致的:
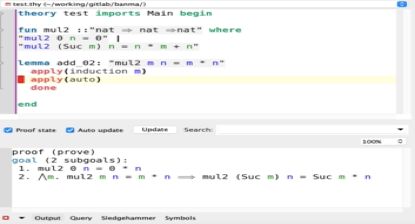
如果觉得哥德尔定理听不懂,没关系,针对计算机程序,我们还有莱斯定理。

我们将程序的每种行为,定义为程序的属性。
如果对于某种属性,针对所有程序都为真,那么就叫它平凡属性。相对的,如果不是针对所有程序都为真的,就是非平凡属性。
莱斯定理是说,对于程序的任何非平凡属性,都不存在可以检查该属性的通用算法。
好,精确的解我们从理论上证明了求不出来。那么我们求近似解行不行?
答案仍然不乐观。原因在于计算复杂性,这是一个获得图灵奖的领域。随着代码规模的线性增长,其分析的复杂度是指数级增长的。程序分析技术,比如布尔可满足性理论SAT、可满足性模理论SMT和符号执行的技术,都严重受制于计算量。
这也导致了基于规则的工具,不管是简单的分析脚本还是复杂的静态分析工具,都在想方设法跟复杂性斗争,比如说可以参看源伞同学们所用的启发式方法等各种技术。
第一类困难的最后一条,机器学习中的规则学习是符号主义学习的主要代表,其代表方法归纳逻辑程序设计方法等方法因为复杂度高,在统计学习兴起之后一直没有太大的发展。
第二类困难:多写点测试用例行不行?
如果不依赖直觉,看看专业著作里对于修复bug是如何描述的,以下是世界名著《代码大全》中总结的方法:
- 将发现的错误提炼为测试用例,并且在单元测试中重现这个bug
- 更进一步,尝试用各种不同的方法来重现这个bug
- 使用否定性测试用例从另一个方向来研究这个bug
- 使用各种工具来辅助定位bug, 如编译器、调试器、内存检查工具、代码补全工具等
- 通过各种方法不断缩小嫌疑的范围
- 对曾经出现过bug的函数或类保持警惕
- 检查最新修改过的代码
- 尽可能使用增量式集成,减小提交的规模
- 提交代码前按照checklist检查常见的错误

相比之下,大部分同学平时解决bug的步骤不会像上面一样复杂,按《代码大全》上写的这么做成本太高了。
但实际上,如果你学习过科学研究的方法论的话,会发现《代码大全》的方法非常符合科学研究的方法。我们来看下科学研究的一般方法:
- 通过可复重试验收集数据
- 根据收集到的数据的统计特征构造一个假说
- 设计一个实验来证明或者证伪第二步构造的假说
- 假说被证明或者证伪
- 根据需要重复进行上面的步骤
将上述通用的科学方法应用于bug解决,我们可以总结成下面的步骤:
- 首先,将错误的状态稳定下来,也就是能重现问题
- 其次,分析错误的来源
- 第一步,收集bug产生的数据
- 第二步,根据第一步收集的数据构造产生bug原因的假设
- 第三步,证实或者证伪第二步的假设,可以通过修改代码再运行测试等方法来证明
- 第四步,根据第三步的结果来确定结论
- 再次,按照错误原因修复bug
- 然后,验证修复有效,问题不再重现
- 最后,推而广之,看看是否还有类似的bug没有被发现

将上面这些方法变自动化,就是自动定位的7种武器了:
- Spectrum-Based Fault Localization 频谱定位
- Mutation-Based Fault Localization 变异定位
- Program Slicing 程序切片
- Stack trace Analysis 栈帧分析
- Predicate Switching 谓词预测
- Information Retrieval-Based Fault Localization 信息获取定位
- History-Based Fault Localization 历史定位
以其中效果最好的频谱分析来说,通过写足够定位问题的测试用例,针对测试用例记录代码覆盖率。被失败测试用例执行的程序元素,更有可能有错误;被成功测试用例执行的程序元素,更有可能没错误。通过公式的计算,我们就可以估算出问题出在哪里。

看起来很美好,但是一实践就到处碰壁,互联网公司都是快速迭代,代码变化快,大规模的测试用例根本跟不上。
第三类困难:证明程序没有bug可不可以?
靠直觉写规则不行,测试用例写不起工作量承受不了,那么我们回归到第一性原理,不要有bug分析bug了,直接在写代码时就证明程序没有bug行不行?
恭喜你,你打开了computer science的大门,计算机科学的最高奖图灵奖在早期有多半的成就都是与此相关的。有研究模型的,有开发工具的,不亦乐乎:
1963年,约翰·麦卡锡提出递归函数作为程序的模型
1967年,罗伯特·弗洛伊德提出命令式程序的前后断言法
1969年,东尼·霍尔提出程序语言的公理语义,即霍尔逻辑
1972年,罗宾·米尔纳受达纳·斯科特的理论的启发,在斯坦福大学开发了LCF工具 - Logic for Computable Functions
1975年,艾兹格·迪科斯彻提出最弱前置条件法
1979年,米尔纳在爱丁堡大学改进LCF,为此发明了ML语言(Meta Language)
1990年,米尔纳组织推出Standard ML
不仅是程序正确性证明,人工智能的最早研究就是从自动定理证明起步的。1956年,人工智能起点达特茅斯会议,西蒙和纽厄尔公布了Logic Theorist程序,这是第一个自动定理证明程序。
除此之外,证明方法也需要研究,1970年,高德纳和学生开创了形式主义证明方法,主要是项重写。
另外,费根鲍姆的专家系统的底层技术仍然是机器定理证明。

自动定理证明是个超越计算机科学的领域,数学家早就在思考这个问题了。最早的思考来自笛卡尔。到了近代,数学哲学中的逻辑主义代表人物罗素主张把数学归约到逻辑,而数学哲学形式主义的代表人物希尔伯特梦想把数学符号化。
1931年,哥德尔不完全性定理证明一阶整数算术是不可判定的。
不久,塔尔斯基证明了一阶实数是可判定的。
1931年左右,23岁去世的少年天才埃尔布朗是为证明论和递归论奠定了基础
1935年左右,希尔伯特的逻辑助手根岑完善了证明论
1939年,维特根斯坦和图灵在课堂上最早讨论证明复杂性
1978年,哈特马尼斯的《可行计算和可证明的复杂性性质》讨论了证明复杂性问题
如果大家对这门学科感兴趣,欢迎大家学习啊。图灵奖得主Dijkstra曾经说过:

如果要入门的话,可以看陆汝钤院士的《计算系统的形式语义》(上),学习理论。但是看了还不能编程,还得看下顾明老师等翻译的《交互式定理证明与程序开发》。有了上面两本之后,还需要一个例题集,建议读下Cormen等著的《算法导论》,它对每一个算法都有正确性证明。
如果觉得陆院士那本书太厚,可以看张广泉编著的《形式化方法导论》和Glynn Winskel著的《程序设计语言的形式语义》。
或者看下网上的softwarefoundations教程:https://softwarefoundations.cis.upenn.edu/。既有理论,又有Coq的实现,能够学以致用。
这部分方法,我们统称为形式化方法,面临的困难是学习门槛真高。虽然有自动定理论明工具来辅助,仍然生产力不高,大规模实现困难。
解法:统计机器学习方法
前面我们分析了以静态分析为代表的第一类方法,以动态测试为主的第二类方法和以形式化方法为代表的第三类方法,单独用于bug自动修复都有困难。那么我们的解决方案是什么呢?不能光说人家不好,自己没有方法啊,那不是成了解构主义了么。
诚实地讲,还真没有效果太好的方法,哈哈。
但是我们也不能在可可托海干等着啊。
我们的打法可以归纳成4条原则:
- 坚持第一性原理
- 从历史经验中学习
- 借鉴机器学习中的思想
- 坚持一等智慧
坚持第一性原理
第一性原理是从头计算,不需要任何参数,只需要一些基本的物理常量,就可以得到体系基态的基本性质的原理。
这非常切合我们的目标,我认为,缺陷自动修复本质上是个程序智能生成,也叫程序综合的任务。
自从计算机诞生以来,经历了从机器语言、汇编语言到高级语言的演化,但是在所谓的第四代编程语言上一直遇到瓶颈。可能low-code和no-code才是下一代产品。基于编译原理的时代已经过去了,现在需要人工智能的加持,产生下一代编程技术,这基本是共识。这是提升编程生产力目前看来最好的方向。
另外就是有些不管是什么方向都要用到的公共部分,这些基础设施的建设是一定要搞的。
从历史经验中学习
从人工智能的发展史上看,目前统计学习胜过符号主义是不争的事实。不管是图像还是自然语言处理,都是统计方法取得了突破。
据此推断,在程序语言处理方面,不管基于规则方法看起来多有吸引力,也只能是辅助手段,否则最终可能难成正果。
能够借用深度学习、深度强化学习和预训练模型为基础的自然语言处理的方案这些发现最快的方向,我们有可能像风口上的猪一样飞起来。
统计上认为,人类的语言是有所谓的“自然性”原理的。2013年,代码的自然性原理被证明。2016年,bug的自然性原理也被证明。这为我们给代码闻味道提供了理论基础,有bug的代码的熵值跟正常的的代码是不同的。这样,我们可以把预测bug存在变成一个符合泊松分布的二分类问题。
语言模型在自然语言语言处理中占有核心地位,我们同样也可以训练程序语言的模型。不过因为程序语言与自然语言的不同,比如特别能定义新词,需要进行一些预处理。好在洗数据本来就是做算法人的宿命,正好顺便也了解下编程语言工具的更新。
借鉴机器学习中的思想
统计方法目前取得和结果还不太尽如人意,但是我们可以采用Boosting的思想让其集成在一起。
另外,虽然砸算力这样的想法被李戈老师等专家批评过,但是GPT-3等超大算力所带来的能力有目共暏,作为工业界的人士,这也是值得我们考虑的。因为资源是线性增加的,而取得的结果是不连续的。当资源超过一定阈值时,就将带来一些原来所不曾想到的提升。
所以,端到端的模型仍然是值得考虑的重要方向。
坚持一等智慧
菲茨杰拉德曾说过,一个人同时保有两种矛盾的观念,还能正常行事,这是一等智慧的表现。

对于我们来说,就是如何把程序分析和自然语言处理这样完全不同的方向能够集成在一起,这就是我们的一等智慧。
比如,完全使用规则,或者依赖归纳规则学习是走不通的路,但是我们可以将规则变成约束。
举个例子,我们先用规则进行分类,比如我们只关注空指针问题,内存溢出问题,特定类型的异常等细分子类,然后再通过统计机器学习的方法进行处理。
又如,归纳学习困难,我们可以尝试先搞搞聚类。就像昕东同学去年所做的工作那样。
小结
总结一下本文的观点,我想说的是:
- bug自修复很困难,困难到不能靠直觉,需要比较深的自然语言处理和程序分析等知识。就像想理解哥德巴赫猜想只需要初中数学知识,但研究如何证明它需要解析数论和代数数论等专门学科。
- bug自修复目前还处于初级阶段,还没有特效药。跨界同学慎入,投入产出比不高。
- 不过,只要不是想一步解决终级问题,还是有很多低垂的果实可以摘取的。这里充满了希望和可能,程序智能合成也许不是最终正确的方向,但是比改进编程语言和编译原理成功率还是要大得多的。
- 不断蓬勃发展的机器学习技术不停地给我们输送弹药,从深度学习到深度强化学习到预训练模型,后面还会不断有惊喜。而回头看我们面对的困难,处于山不加增的状态,早晚有一天能搬完。
参考文献
- 《计算系统的形式语义》(上),陆汝钤院士著,清华大学出版社
- 《交互式定理证明与程序开发》, Yves Bertot等著,顾明等译,清华大学出版社,2010
- 《形式化方法导论》,张广泉编著,清华大学出版社,2015
- 《ML程序设计教程》,Paulson著,柯韦译,机械工业出版社,2005
- 《算法导论》, Cormen等著,机械工业出版社,2013
- 《程序设计语言的形式语义》,Glynn Winskel著,宋国新、邵志清译,2003
- 宫丽娜,姜淑娟,姜丽.软件缺陷预测技术研究进展.软件学报,2019,30(10):3090-3114. http://www.jos.org.cn/1000-9825/5790.htm
- 蔡亮,范元瑞,鄢萌,夏鑫.即时软件缺陷预测研究进展.软件学报,2019,30(5):1288−1307. http://www.jos.org.cn/1000-9825/5713.htm
- 李斌,贺也平,马恒太.程序自动修复:关键问题及技术.软件学报,2019,30(2):244−265. http://www.jos.org.cn/1000-9825/5657.htm
- 金芝,刘芳,李戈.程序理解:现状与未来.软件学报,2019,30(1):110-126. http://www.jos.org.cn/1000-9825/5643.htm
- 张健,张超,玄跻峰,熊英飞,王千祥,梁彬,李炼,窦文生,陈振邦,陈立前,蔡彦.程序分析研究进展.软件学报,2019, 30(1):80-109. http://www.jos.org.cn/1000-9825/5651.htm
- 李晓卓,贺也平,马恒太.缺陷理解研究:现状、问题与发展.软件学报,2020,31(1):20-46. http://www.jos.org.cn/1000-9825/5887.htm
- 顾斌, 于波, 董晓刚, 李晓锋, 钟睿明, 杨孟飞. 程序智能合成技术研究进展. 软件学报. http://www.jos.org.cn/1000-9825/6200.htm
- 李政亮,陈翔,蒋智威,顾庆.基于信息检索的软件缺陷定位方法综述.软件学报,2021,32(2):247−276. http://www.jos.org.cn/1000-9825/6130.htm
- Wong WE, Gao RZ, Li YH, Abreu R, Wotawa F. A survey on software fault localization. IEEE Transactions on Software Engineering, 2016, 42(8): 707-740. [doi: 10.1109/TSE.2016.2521368]
- Zhang X, Zhu C, Li Y, et al. Precfix: large-scale patch recommendation by mining defect-patch pairs[C]//Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: Software Engineering in Practice. 2020: 41-50.
- 熊英飞老师《软件分析》课课件:https://xiongyingfei.github.io/SA/2020/main.htm