Pandas处理时间序列(一)
Pandas处理时间序列
由于Pandas最初是为金融模型而创建的,因此它拥有一些功能非常强大的日期、时间、带时间索引的处理工具。
3.12.1 Python的日期与时间工具
Python中处理时间日期、时间、时间跨度的工具很多。常用的有如下三类:
- 原生Python:datetime和dateutil库
- NumPy库
- Pandas库
1.原生Python的日期与时间工具:datetime与deteutil
Python基础的日期与时间功能都在标准库的datetime模块中。与第三方库dateutil模块搭配使用,可以实现许多时间与日期的功能。
dateutil模块安装:
pip install python-dateutil
使用datetime创建一个日期:
In [1]: from datetime import datetime
datetime(year=2019,month=7,day=5)
Out[1]: datetime.datetime(2019, 7, 5, 0, 0)
对字符串格式的日期进行解析:
In [2]: date = parser.parse("5th of July, 2019")
date
Out[2]: datetime.datetime(2019, 7, 5, 0, 0)
一旦有了datetime对象,就可以进行许多操作,比如打印出星期:
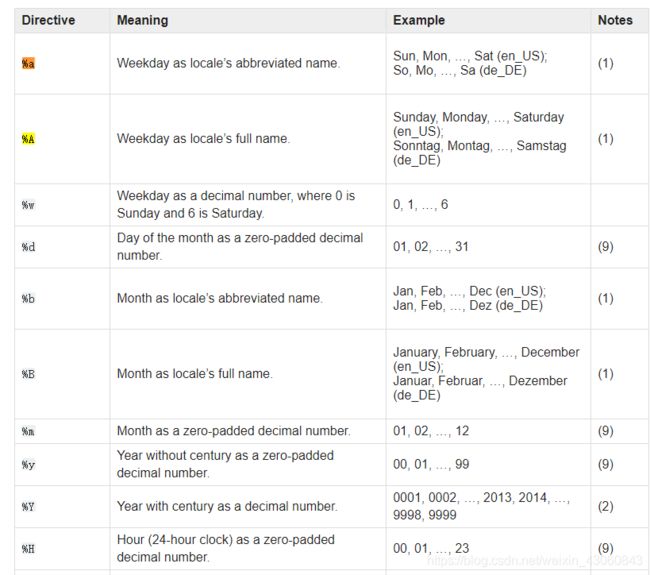
In [3]: date.strftime('%A')
Out[3]: 'Friday'
在上面的代码中使用了标准字符串格式,可以在datetime文档中获取更多信息。
datetime文档
2.Numpy的datetime64类型
和Numpy的存在原因相似,如果处理的时间数据量比较大,那么Python的原生库处理起来就会比较慢,于是Numpy增加了自己的时间序列类型。
In [4]: import numpy as np
date = np.array('2019-07-05',dtype=np.datetime64)
date
Out[4]: array('2019-07-05', dtype='datetime64[D]')
有了这个日期格式,就可以进行快速的向量化运算:
In [5]: date + np.arange(10)
Out[5]: array(['2019-07-05', '2019-07-06', '2019-07-07', '2019-07-08','2019-07-09', '2019-07-10', '2019-07-11', '2019-07-12','2019-07-13', '2019-07-14'], dtype='datetime64[D]')
因为Numpy的datetime64数组内元素类型统一,所以运算速度会比Python的datetime运算速度快很多。
3.Pandas的日期与时间工具:理想与现实的最佳解决方案
Pandas 所有关于日期与时间的处理方法全部都是通过Timestamp 对象实现的。Pandas 通过一组Timestamp 对象就可以创建一个可以作为Series 或DataFrame 索引的
DatetimeIndex。
Pandas处理时间字符串:
In [6]: import pandas as pd
date = pd.to_datetime('5th of July, 2019')
In [7]: date
Out[7] :Timestamp('2019-07-05 00:00:00')
获取星期:
大写A是全称,小写a是简称
In [8]: date.strftime("%a")
out[8]: 'Fri'
进行向量化计算:
In [9]: date + pd.to_timedelta(np.arange(10))
Out[9] :
DatetimeIndex([ '2019-07-05 00:00:00',
'2019-07-05 00:00:00.000000001',
'2019-07-05 00:00:00.000000002',
'2019-07-05 00:00:00.000000003',
'2019-07-05 00:00:00.000000004',
'2019-07-05 00:00:00.000000005',
'2019-07-05 00:00:00.000000006',
'2019-07-05 00:00:00.000000007',
'2019-07-05 00:00:00.000000008',
'2019-07-05 00:00:00.000000009'],
dtype='datetime64[ns]', freq=None)
由于datetime64 对象是64 位精度,所以可编码的时间范围可以是基本单元的2的64次方 倍。所以要指定计算单位:
D:天,M:月
In [10]: date + pd.to_timedelta(np.arange(10),'D')
Out[10]: DatetimeIndex(['2019-07-05', '2019-07-06', '2019-07-07', '2019-07-08', '2019-07-09', '2019-07-10', '2019-07-11', '2019-07-12', '2019-07-13', '2019-07-14'],
dtype='datetime64[ns]', freq=None)
3.12.2 Pandas时间序列:用时间做索引
Pandas 时间序列工具非常适合用来处理带时间戳的索引数据.比如我们通过时间索引创建一个Series对象:
In [11]: index = pd.DatetimeIndex(['2019-07-01', '2014-07-04','2019-06-04', '2015-05-04'])
data = pd.Series([1,2,3,4],index=index)
data
Out[11]: 2019-07-01 1
2014-07-04 2
2019-06-04 3
2015-05-04 4
dtype: int64
我们可以直接用日期进行切片取值,他会选取符合切片时间段内的所有值:
In [11]:data["2014-07-04":"2019-06-04"]
Out[11]:2014-07-04 2
2019-06-04 3
2015-05-04 4
dtype: int64
我们也可以使用不存在data中的索引值做切片:
In [12]:data["2010-07-04":"2019-06-04"]
Out[12]:2014-07-04 2
2019-06-04 3
2015-05-04 4
dtype: int64
另外,可以直接通过年份(月份)获取该年所有数据:
In [13]:data['2019']
Out[13]:2019-07-01 1
2019-06-04 3
dtype: int64