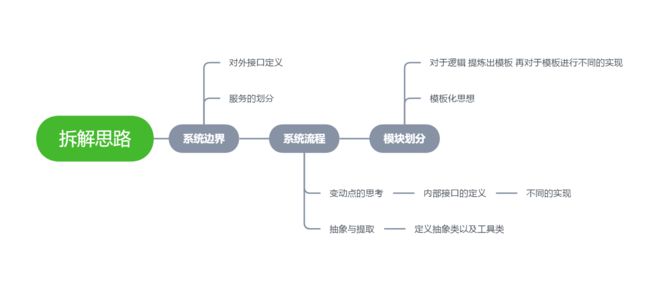
思路
最初我拿到一个问题的时候,首先想的就是他怎么实现,具体的实现,而面向接口编程需要先考虑好流程,明白变动点可能在哪里,系统的边界在哪里,边界的划分决定了模块和服务的拆分,变动点决定了需要抽象和隔离的地方。想清楚再下手。
提炼一下就是:
案例
代码重构方案
//原来的代码
for (ModuleEnum module : modules) {
switch (module) {
case ALBUM:
Album albumData = getAlbumData(key, pageSize, pageNumber);
if (albumData.getContent().size() == 0) {
searchData.setAlbum(null);
} else {
searchData.setAlbum(albumData);
}
break;
case ACTIVITY:
Activity activityData = getActivityData(key, pageSize, pageNumber);
if (activityData.getContent().size() == 0) {
searchData.setActivity(null);
} else {
searchData.setActivity(activityData);
}
break;
case COURSE:
Course courseData = getCourseData(key, pageSize, pageNumber);
if (courseData.getContent().size() == 0) {
searchData.setCourse(null);
} else {
searchData.setCourse(courseData);
}
break;
case BLOG:
Blog blogData = getBlogData(key, pageSize, pageNumber);
if (blogData.getBlogContents().size() == 0) {
searchData.setBlog(null);
} else {
searchData.setBlog(blogData);
}
break;
default:
}
}
这里我们看到了非常多的代码冗余,逻辑完全一样,但是写了四遍.再看下面:
//这里4个方法对应上面的调用(逻辑完全一样,仅仅是返回值和其中一些调用的方法不一样,我就只列出方法名了)
private Album getAlbumData(String key, int pageSize, int pageNumber) throws IOException;
private Activity getActivityData(String key, int pageSize, int pageNumber) throws IOException;
private Course getCourseData(String key, int pageSize, int pageNumber) throws Exception;
private Blog getBlogData(String key, int pageSize, int pageNumber) throws IOException;
重构思路
对这里的重构我考虑用如下的方法:
1.使用工厂模式调用不同的实现,替换switch.
2.在接口和实现之间增加抽象方法,提取公共逻辑

上码
1 枚举实现工厂方法
//枚举类
public enum ModuleEnum {
//在线课程
COURSE("0", "course", "courseindex"){
@Override
public ISearchService build() {
return new CourseSearch();
}
},
//培训活动
ACTIVITY("1", "activity", "activityindex") {
@Override
public ISearchService build() {
return new AlbumSearch();
}
},
//知识库
ALBUM("2", "album", "albumindex") {
@Override
public ISearchService build() {
return new AlbumSearch();
}
},
//Q记
BLOG("3", "blog", "blogindex") {
@Override
public ISearchService build() {
return new BlogSearch();
}
};
public abstract ISearchService build();
}
这里使用枚举来实现工厂方法,因为考虑使用反射效率较低.
可以看到,我定义了一个抽象的build方法,返回实现类的接口,而在每个枚举类中又实现了build方法 返回不同的实现类.
//调用者
ISearchService isearchservice = ModuleEnum.build();
if (isearchservice == null) {
//防御性判断
throw new RuntimeException("不支持的模块类型" + ModuleEnum.getName());
}
return isearchservice;
这里通过调用build方法来实现工厂方法的调用
2 增加抽象方法
public abstract class AbstractSearchService implements ISearchService {
private static final Logger log = LoggerFactory.getLogger(AbstractSearchService.class);
@Override
public SearchData getSearchData(String key, int pageNumber, int pageSize, SearchData searchData) throws Exception {
AbstractlModulBase modulData = getModulData(key, pageSize, pageNumber);
if (modulData.getContent().size() == 0) {
searchData.setAlbum(null);
} else {
//根据具体的子类调用具体的实现
searchData = setData(searchData, modulData);
}
return searchData;
}
private AbstractlModulBase getModulData(String key, int pageSize, int pageNumber) {
Page page = new Page(pageSize, pageNumber);
//从ES中查询基础数据
List activityBeanList = getModulBeanList(key, page);
//获取模块Id
List masterIdList = getParentIdList(activityBeanList);
log.info("搜索到的模块id = {}", masterIdList);
//从bubbo中查询实时数据 之后对ES中的数据和Dubbo中的实时数据进行整合 并判断是否有数据未同步
return getModulBeenAndMix(masterIdList, activityBeanList, page);
}
/**
* 将基类转换成不同的子类 并赋值
* @param searchData 统一存储查询出的所有内容
* @param modulData 基类
* @return SearchData
*/
protected abstract SearchData setData(SearchData searchData, AbstractlModulBase modulData);
/**
* ES查询
* @param key ES查询关键词
* @param page 分页信息
* @return ES查询结果Been
*/
protected abstract List getModulBeanList(String key, Page page);
/**
* 从bubbo中查询实时数据 之后对ES中的数据和Dubbo中的实时数据进行整合 并判断是否有数据未同步
* @param masterIdList IdList
* @param beanList ES查询集合
* @param page 分页信息
* @return 查询总结果
*/
protected abstract AbstractlModulBase getModulBeenAndMix(List masterIdList, List beanList, Page page);
/**
* 提取IdList
* @param parentBeans been
* @return IdList
*/
private List getParentIdList(List parentBeans) {
Preconditions.checkNotNull(parentBeans);
return Lists.transform(parentBeans, new Function() {
@Override
public Integer apply(ParentBean input) {
return input.getId();
}
});
}
}
这里针对具体的逻辑进行拆分 并将具体的实现交由子类完成
一些设计思路
功能设计
- 模块功能的改变、增加、移除;系统流程的变化
- 适应业务发展的一种常态(频繁的,不可抗拒的)
- 设计系统时考虑:模块解耦(避免牵一发而动全身); 面向接口编程(尽量减少对调用方影响)
- 修改系统时考虑:扩展 > 修改 (遵循“开闭原则”) → 功能兼容
程序设计
1. 问题拆分,划分模块 明确输入输出,暂时忽略代码细节(切忌代码堆叠) → 定义接口(面向接口编程)
参数校验 → 命令识别与解析 → 文件读取 → 命令执行 → 结果输出
变化:
- 参数校验模块(功能改变):不再校验源文件目录参数
- 文件读取模块(新流程不再使用):不再需要使用文件读取模块
- 结果输出模块(功能改变):由输出到结果文件 → 通过日志到控制台 [LocalFileOutputService → LogOutputService]
模块功能变化后的几种改动方式(不分优劣,取决于具体场景):
- 直接修改原模块逻辑:核心逻辑未变,局部微调,bugfix
- 继承原有模块:优势:复用父类逻辑;局限性:单继承
- 新增模块实现:核心逻辑变化,入参未变化(如结果输出:输出文件 → 输出日志)
- 扩展接口方法:核心逻辑未变,入参变化 (不同方法适用于不同的场景,方法重载,类比构造方法)
优势:功能聚合,适用不同场景;公共逻辑可以复用
2. 数据模型的建立 → 抽象(关注当前问题域的属性)、继承
- 命令实体:关注:(类型,选项,参数)
- 文件数据:关注:(内容,文件名) 忽略(创建时间,访问权限等)
- 不再代表原始文件数据:而是代表中间处理结果
3. 过程抽象 → 分离变与不变(模板方法模式)
- 流程发生变化
- 对外接口不变
4. 各个模块代码的实现 → 代码规范
- 变量命名:见名知意、驼峰命名、常量大写下划线分隔等
- 异常处理:
- 抛出or处理
- 自定义异常:类型、原因、执行现场信息、异常栈(便于定位问题代码)
- 日志记录:远离System.out.println(性能:加锁+阻塞当前线程)
5. 性能优化 → 可选
多文件流式处理(缓解内存压力),线程池执行(提高吞吐量)等等。
最后
这里我的实现还不是很完善,但思路基本就是这样,重构完之后代码可扩展性更好,代码冗余减少.