Perceiver解读:使用transformer进行多模态分类
Perceiver解读
最近在看多模态学习的工作,发现一个使用transformer进行多模态融合的模型很有趣,分享一下,文章是Perceiver: General Perception with Iterative Attention。
Perceiver的共享主要包括两点:1.使得transformer的层数可以更深,实验中可以堆叠48层;2.可以在不改变模型结构的基础上处理多种模态的数据,实验中对图像、音频、视频、点云数据都进行了测试,目前研究在图像、点云、音频、视频、音频+视频数据上进行了分类实验,其中ImageNet数据集上的效果和ResNet-50不相上下,直接对224×224的图像进行处理,在语音数据集AudioSet上超过SOTA,在点云数据集ModelNet40上保持可比性一致的情况下取得SOTA结果;3.引入非对称注意力模型迭代融合输入数据和latent array,使模型可以处理尺寸很大的输入,甚至直接处理原始图像,不需要卷积直接就可以处理50000个像素。
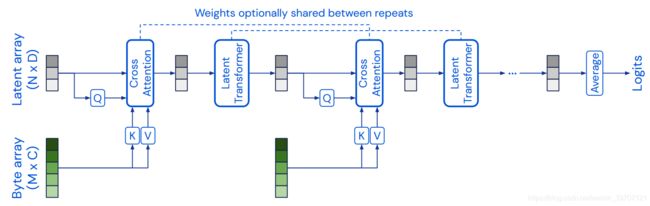
Perceiver的模型结构如上图,模型可以看作是对输入的端对端聚类,latent array中的元素作为聚类中心,利用了高度不对称的交叉注意力层,通过不断迭代来融合输入数据,将其有限的模型容量分配给最相关的输入。同样地本文也是使用傅里叶编码来保持位置信息。
模型总体上由两大基础结构组成:1.cross-attention用于将byte array和前一latent array进行融合,输出得到latent array;2.latent transformer输入latent array,输出latent array,将latent array从前一特征空间映射到另一个特征空间。byte array的长度就是输入数据的长度,例如图像语音等,一般长度很大。Latent array是长度自定的超参数,需要比byte array小很多,达到降维的效果(本文在ImageNet数据集上byte array的长度为50176,latent array的长度设置为1024)。总体来说,Perceiver堆叠了多个cross-attention和transformer的模块不断迭代挖掘输入信息,其中cross-attention将高维byte array映射为低维latent array,transformer将latent array的特征空间映射到另一特征空间,本文实验部分最多堆叠了48层这样的结构。
cross-attention模块:这里的cross-attention参考transformer中decoder的multi-head attention,QKV来自于encoder的输出和decoder输入,byte array使用MLP获得K和V向量,latent array也通过MLP获得Q向量。QKV通过cross-attention融合后得到长度为N的array,这样将原始数据的长度M降低为latent array的长度N。传统的transformer直接对图像这类输入维度很大的数据进行attention时会产生二次复杂性,例如一张图像展开为一维后长度为M,需要产生向量 ![]() ,
,![]() ,
,![]() ,此时attention机制中的
,此时attention机制中的![]() 的复杂度为
的复杂度为![]() ,在输入维度很高时耗费时间很长。Perceiver的cross-attention模块中引入非对称,也就是K和V向量来自byte array,而V向量来自latent array,这样的attention机制复杂度为
,在输入维度很高时耗费时间很长。Perceiver的cross-attention模块中引入非对称,也就是K和V向量来自byte array,而V向量来自latent array,这样的attention机制复杂度为![]() ,使模型直接处理原始大小的数据成为可能。
,使模型直接处理原始大小的数据成为可能。
Latent transformer模块:latent transformer其实是transformer encoder,包括multi-head self-attention和FFN。经过cross-attention处理后array的长度变为一个较小的长度N,这样transformer计算时的复杂度为![]() ,相对于原始数据的长度M要小很多,从而将传统深度为d的transformer复杂度从
,相对于原始数据的长度M要小很多,从而将传统深度为d的transformer复杂度从![]() 降为
降为![]() 。起始的latent array使用随机初始化得到,随后不断通过学习更新。
。起始的latent array使用随机初始化得到,随后不断通过学习更新。
迭代attention:通过从byte array中提取KV向量再送入cross-attention达到降维目的,但是这样的操作也许会限制模型从输入数据中捕捉足够的信息,既然通过引入latent array大大降低了transformer直接处理原始数据的复杂性,那么就可以尝试堆叠多个cross-attention和latent transformer这样的结构来迭代从输入数据中获取信息。为了提高参数有效性,相邻的cross-attention或者相邻的latent transformer之间都可以进行参数共享。本文在ImageNet实验中进行参数共享后参数数量降低了10倍。需要注意的是每一次迭代的cross-attention都是将原始输入重新进行一次融合,搭配参数降低的方法使得在不降低感受野尺寸的前提下也不会使模型规模过大。
其他模型结构上的细节:Perceiver也采用了transformer广泛使用的残差连接,将模块的输入直接加到模块输出上,在latent transformer和cross-attention尚均有使用。cross-attention在输入前首先对byte array和latent array进行层归一化,然后才使用线性层进行QKV的提取,输出同样是使用一个带有dropout的线性层进行处理。每个cross-attention和self-attention block之后都会跟一个dense block,输入先进行层归一化,再跟激活函数为GELU的线性层,最后在加一个有dropout的线性层。
综上来看,latent array提取Q向量,可以看作是query,通过迭代对从byte array提取的KV向量进行多次查询,cross-attention实现了将很大的原始输入通过注意力机制降维到可以接受的维度,然后latent transformer再让latent array自己的元素不断进行自我交互,搭配这两种结构让byte array的信息最终可以用维度更小的latent array得以表示,复杂度是![]() 。
。
Positional encodings:attention对于不同顺序的输入都会得到相同的输出,称这种特性为permutation-invariant,由于数据形式多样,而attention模型不对数据空间结构或者对称性做先验,所以很适合各类数据处理。但是也因为这种原因attention不能自己完成空间关系信息获取,所以通常要为输入特征加上positional encodings,不仅可以用来编码序列位置和空间位置等,也可以为多模态数据用类别编码来区别模态。
图像数据的实验作者使用了ImageNet数据集,positional encodings作者使用了crop坐标,因为image坐标会造成过拟合。优化器作者采用了专为transformer结构设计的Lamb优化器。实验一共进行了三种,第一种是在标准ImageNet数据集上进行实验,第二种和第三种分别是对图片排列顺序做了置乱和对每张图中的像素做了置乱。最终第一个实验结果在表1,第二个和第三个实验结果在表2。Transformer由于直接处理全尺寸太耗时,这里先采样到64×64的尺寸。
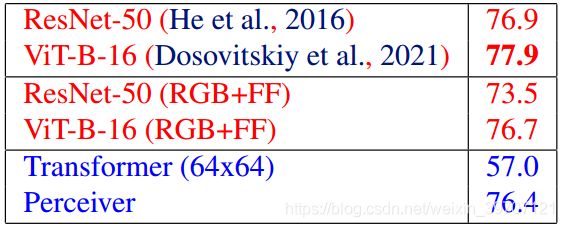
表1
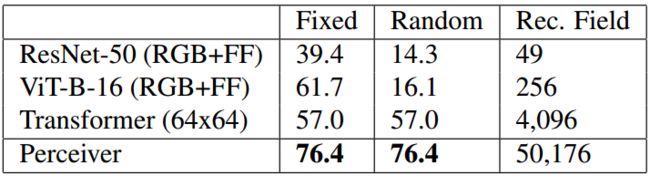
表2
第二个实验中的Fixed表示只置乱图片顺序,Random是图像像素点位置进行置乱,Rec, Field是感受野的大小,ResNet-50用的是7×7的卷积核,ViT使用了16×16的patch,transformer和perceiver都是全局感受野。看得出来transformer和perceiver由于attention的置换不变性,结果未受影响。
可视化cross-attention模块:这里对第一个(蓝色框)、第二个(绿色框)和第八个(橙色框)cross-attention模块的![]() 输出进行可视化,其中第二层到第八层都进行了参数共享。第一个模块输入图的痕迹很明显,很多注意力落在狗上,而第二层和第八层结果相似,注意力都表现为高频网格。虽然第二层和第八层的注意力虽然结构相似,但是细节上仍有差异,表明模型关注的像素集并不一样。
输出进行可视化,其中第二层到第八层都进行了参数共享。第一个模块输入图的痕迹很明显,很多注意力落在狗上,而第二层和第八层结果相似,注意力都表现为高频网格。虽然第二层和第八层的注意力虽然结构相似,但是细节上仍有差异,表明模型关注的像素集并不一样。
参考:
https://zhuanlan.zhihu.com/p/360773327
https://www.youtube.com/watch?v=P_xeshTnPZg