HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为Hadoop提供类似于BigTable规模的服务。因此,它可以容错地存储海量稀疏的数据。
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
更多简介或原理性内容可参考链接:
https://www.jianshu.com/p/b23800d9b227
https://www.jianshu.com/p/53864dc3f7b4
https://www.jianshu.com/p/0a0a151c84d4
https://www.jianshu.com/p/479bc6308381
目录
- 一、安装环境
- 二、环境准备
- 三、hbase分布式搭建步骤
- 四、hbase基本使用
- 五、期间遇到的坑
- 六、参考并致谢
一、安装环境
操作系统: CentOS 7
Hadoop版本: Hadoop-3.2.1
zookeeper版本: zookeeper-3.4.14
Hbase版本: hbase-2.2.3
相关主机:
主机:192.168.111.249 master
从机1:192.168.111.247 node1
从机2:192.168.111.248 node2
二、环境准备
hbase和hadoop和jdk版本之间的关系可参考官网:http://hbase.apache.org/book.html#java
1、JDK、Hadoop安装、主机名修改可参考之前写过的文章:
可参考:https://www.jianshu.com/p/27cbd5bbdf61
2、zookeeper安装可参考之前写过的文章:
可参考:https://www.jianshu.com/p/e811a3fd5235
由于本章节主要内容是Hbase的部署安装,Hbase是基于Hadoop、java和zookeeper,而Hadoop和zookeeper的部署会占一定的篇幅,之前也有过相关文章,加上本次Hbase的部署是在之前写Hadoop和zookeeper的文章的时候所用的机器,因此此处就不多加篇幅去重复相关的步骤了,望谅解。
三、hbase分布式搭建步骤
1、下载Hbase
各版本下载地址:http://mirror.bit.edu.cn/apache/hbase/
此处使用的是hbase-2.2.3的版本
[root@master ~]# cd /home/
[root@master home]# wget http://mirror.bit.edu.cn/apache/hbase/2.2.3/hbase-2.2.3-bin.tar.gz
2、解压
[root@master home]# tar zxvf hbase-2.2.3-bin.tar.gz
3、配置环境变量
[root@master home]# vim /etc profile
# 文件中追加以下内容
export HBASE_HOME=/home/hbase-2.2.3
export PATH=$HBASE_HOME/bin:$PATH
保存退出,然后source /etc/profile刷新以下环境变量
4、修改配置文件
需要修改的配置文件以及文件所在的目录如下
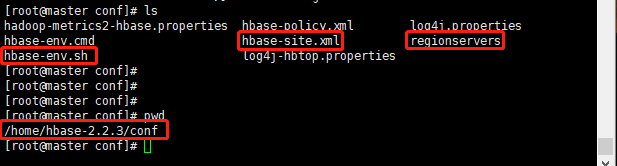
hbase-env.sh
配置java环境变量
注意:第二个参数文档注释写的是JAVA_CLASSPATH,但参数名称却是HBASE_CLASSPATH,据说按照参数名HBASE_CLASSPATH写的话后面启动会有错误报出,因此按照注释写的改为JAVA_CLASSPATH

日志存放路径

关闭自带的zookeeper,hbase自带zookeeper单机版,我们此处搭建的是分布式,因此将此关闭,如需要搭建单机版的话可以保持默认的true
hbase-site.xml
配置文件中configuration标签中间下入以下内容
hbase.master
master:60000
hbase.cluster.distributed
true
hbase.rootdir
hdfs://master:9000/hbase
hbase.zookeeper.quorum
master,node1,node2
hbase.master.maxclockskew
120000
hbase.unsafe.stream.capability.enforce
false

regionservers文件
删除localhost,将从节点主机名写入
5、远程复制hbase到各个节点中
将master的hbase远程拷贝到从节点上,从节点的环境变量也作相应的修改,与master计器的修改方法相同
scp -r /home/hbase-2.2.3 node1:/home/
scp -r /home/hbase-2.2.3 node2:/home/
6、启动
# 【master节点】启动Hadoop
[root@master home]# start-all.sh
# 【各个节点】启动zookeeper
[root@master home]# zkServer.sh start
# 【master端】启动Hbase
[root@master home]# start-hbase.sh
# 【各个节点】使用jps命令查看进程
[root@master home]# jps
master端

node1端

node2端

浏览器打开以下地址可访问到页面:
http://192.168.111.249:16010/master-status
至此Hbase已搭建完毕
四、hbase基本使用
基本命令总结:
| shell命令 | 命令作用 | 命令语法 |
|---|---|---|
| create | 创建表 | < create ‘表名’, ‘列族名’, ‘列族名2’,‘列族名N’ > |
| list | 查看所有表 | < list all > |
| describe | 显示表详细信息 | < describe ‘表名’ > |
| exists | 判断表是否存在 | < exists ‘表名’ > |
| enable | 使表有效 | < enable ‘表名’ > |
| disable | 使表无效 | < disable ‘表名’ > |
| is_enabled | 判断是否启动表 | < is_enabled ‘表名’ > |
| is_disabled | 判断是否禁用表 | < is_disabled ‘表名’ > |
| count | 统计表中行的数量 | < count ‘表名’ > |
| put | 添加记录 | < put ‘表名’, ‘row key’, ‘列族1 : 列’, ‘值’ > |
| get | 获取记录(row key下所有) | < get ‘表名’, ‘row key’> |
| get | 获取记录(某个列族) | < get ‘表名’, ‘row key’, ‘列族’> |
| get | 获取记录(某个列) | < get ‘表名’,‘row key’,‘列族:列’ > |
| delete | 删除记录 | < delete ‘表名’, ‘row key’, ‘列族:列’ > |
| deleteall | 删除一行 | < deleteall ‘表名’,‘row key’> |
| drop | 删除表 | |
| alter | 修改列族(column family) | |
| incr | 增加指定表,行或列的值 | |
| truncate | 清空表 | 逻辑为先删除后创建 |
| scan | 通过对表的扫描来获取对用的值 | |
| tools | 列出hbase所支持的工具 | |
| status | 返回hbase集群的状态信息 | |
| version | 返回hbase版本信息 | |
| exit | 退出hbase shell | |
| shutdown | 关闭hbase集群(与exit不同) |
Hbase中的结构大致如图:

hbase是一张表:表中有一个唯一键是 row key, 每个row key 对应 N(N >= 1)个列族。每个列族由N个列组成(N>=1)
以下以具体例子展示:
# 登录hbase shell
[root@master ~]# hbase shell
# 创建表catke
> create 'catke','column_family_1', 'column_family_2', 'column_family_3'
# 关闭表
> disable 'catke'
# 开启表
> enable 'catke'
# 删除表
> drop 'catke'
# 查看所有表
> list
# 查看表结构
> describe 'catke'
# 插入一条数据
> put 'catke','key_1','column_family_1:column_2','value2'
# 获取一条数据
> get 'catke','key_1'
# 查看get命令的帮助(其他命令类似)
> help 'get'
# 查询表的所有数据
> scan 'catke'
# 查询column_family_1下的数据
> scan 'catke',{COLUMN => 'column_family_1'}
等同于
scan 'catke',{COLUMN => ['column_family_1']}
# 查询column_family_1,column_family_2列族的数据
> scan 'catke',{COLUMN => ['column_family_1', 'column_family_2']}
# 查询column_family_1下column_1列的数据
> scan 'hbase_test',{COLUMN => ['column_family_1:column_1']}
# 查询row key 大于等于某key的数据
> scan 'catke',{COLUMN => ['column_family_1:column_1','column_family_2:column_3'], STARTROW => 'key_2'}
# 查询row key 小于某key的数据
> scan 'catke',{COLUMN => ['column_family_1:column_1','column_family_2:column_3'], STOPROW => 'key_2'}
# 查询大于等于key_2,小于key_5的数据
> scan 'catke',{COLUMN => ['column_family_1:column_1','column_family_2:column_3'], STARTROW => 'key_2', STOPROW => 'key_5'}
# 限制输出的条数(限制的数量是针对主键row key的,因此可能不止2条)
> scan 'catke', {LIMIT => 2}
# 反序获取两行数据
> scan 'catke', {LIMIT => 2, REVERSED => true}
【默认情况下REVERSED => false,当设置REVERSED => true时,数据反向读取2行,自然与之前不一致。可以理解为mysql中select * from dual asc limit 2与select * from dual desc limit 2这样的区别】
# 删除数据(delete这个方法只能删除具体到哪一行中的某个列族下的某一列数据)
> delete 'catke','key_6','column_family_3:'
# 删除一整行数据
> deleteall 'catke','key_7'
# 清空表数据
> truncate 'catke'
# 执行脚本
如将插入语句写到一个文件中,然后执行
[root@master ~]# hbase shell testshell
五、期间遇到的坑
1、启动时日志出现拒绝连接的错误
Caused by: java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:714)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:685)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:788)
at org.apache.hadoop.ipc.Client$Connection.access$3500(Client.java:410)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1550)
at org.apache.hadoop.ipc.Client.call(Client.java:1381)
... 33 more
原因:Hadoop中的dfs.namenode.rpc-address一项没有配置
解决方法:
1、在Hadoop的hdfs-site.xml配置文件中添加以下配置:
dfs.namenode.rpc-address
192.168.111.249:9000
其中192.168.111.249是namenode的服务器地址,9000是与core-site.xml文件中的fs.default.name配置中的端口一致
2、重启hadoop
3、重启hbase
2、启动时出现以下错误
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
解决方法:
在hbase-site.xml配置文件中增加配置
hbase.unsafe.stream.capability.enforce
false
然后重启Hbase
六、参考并致谢
https://www.cnblogs.com/chaofan-/p/9931213.html
https://blog.csdn.net/luqiang81191293/article/details/40428809
https://www.ibm.com/developerworks/cn/downloads/im/biginsightsquick/
https://blog.51cto.com/taotao1240/1735420
https://blog.51cto.com/taotao1240/1734755
https://segmentfault.com/q/1010000005686421/a-1020000005686550
https://segmentfault.com/q/1010000005689441
https://blog.csdn.net/ck3207/article/details/81674557
https://blog.csdn.net/u010416101/article/details/89186320
https://blog.csdn.net/oschina_41140683/article/details/102829597?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task