整篇读完可能费时较长,可能会有的人想直接看重点,想直接看重点的话直接看结论部分




背景
前段时间考了12月的N2,考完之后感觉比想象中的要难一些。
之前自己做真题,感觉阅读听力都不错,有时候整个阅读部分只错2个题。按照真题练习册上的那种计分方式自己大概估算了下,大概是在130分左右徘徊。
不过考完试后才感觉,自己平时做真题跟正儿八经考试还是差别挺大的,哪怕是自己做真题的时候也卡着时间来做。因为考场的环境毕竟跟家里不一样,而且听力是公放真的很容易走神,而且不得不吐槽下教室的隔音很差,旁边还是篮球场,听力听得想狗带。
先不说自己的考试感受了,下面还是聊聊JLPT的计分吧。
相信有不少考过JLPT的人对于JLPT的计分方式感到很迷。我因为是首次考,之前也曾天真的认为,就按照真题册子上的那种计分方式来算分不就完了么,就算有那种一直流传的简单的题不能错,算分高的说法存在,也大概就是在每个大的问题中将各个小题加权,然后权重再乘上这个题目本来的基础分值。这样计算也应该八九不离十了。
可能有的人也不知道这个真题册子上有每题多少分这个东西,我也是因为是做的朋友给我的题,我现在手头上有的卷子正好都没这个计分表。淘宝上找了一圈也没找到有把这个东西放在详情里面的。好不容易找到一张这样的图,全损画质,凑合着看看吧
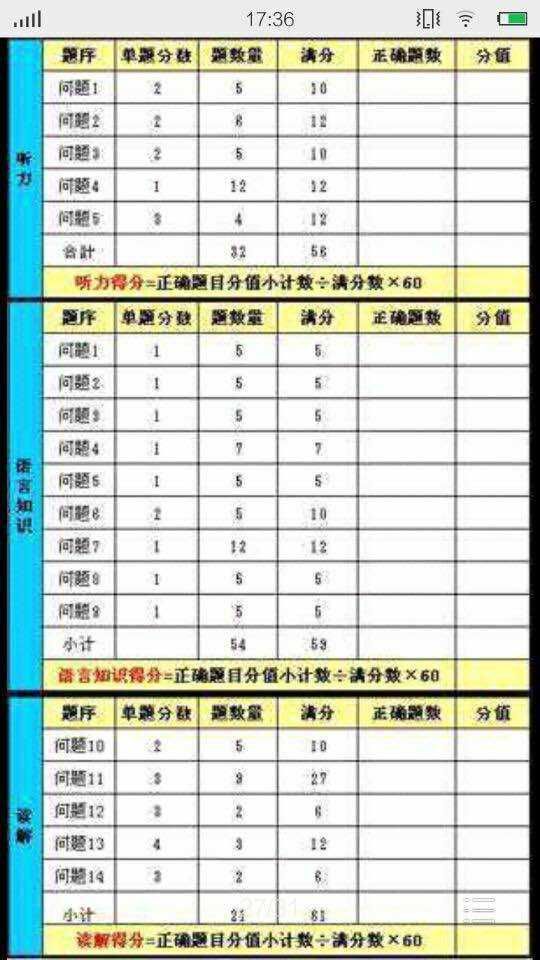
不过多少有些出入,比如问题9的完型填空应该是1个2分的,然后阅读的问题11,3个中篇阅读,应该是每个的前2个小问是2分,第3问是3分的。
(有同学说这个图实在太糊了,我还是拖朋友给照了一下N2试卷上的原版)


但是这都不重要了,因为一会都是要把这套东西推翻的/doge(假装可以发表情)。
而且当初自己还觉得,180分的题目,90分及格,假如运气足够好,乱蒙正好无差别的对一半以上,也都能过。所算一算只需要对60分的题目有足够的把握能做对,其他120分的题,按照1/4的概率乱蒙,正好凑够30分也就压线飘过了。
直到后来在学习群里跟其他群员讨论这个算分方式,因为我的理论说服不了别人,别人的理论(简单题错得多就完完了,乱蒙不给你算分之类的理论)也说服不了我,便决定自己去看看官方给出的解释(维基百科的介绍)之后,才发现自己当初的想法还是太稚嫩了。
正篇
下面就是通过看官方给出的解释得出的关于JPLT计分方式的理解了。(之前也百度过,不过都是很不详细且比较笼统的说法,跟被大家所流传的那样诡异的计分方式不太匹配)
首先先放上维基的官方说明,这里有个坑就是中文的介绍是没有算分方式这一项的,英文的才有。
https://en.wikipedia.org/wiki/Japanese-Language_Proficiency_Test
也就是下面这个页面,可能有的朋友打不开,或许是被墙掉了吧。所以干脆把图也放出来,有兴趣的朋友可以通过链接去看看,毕竟我的理解也不一定全对。
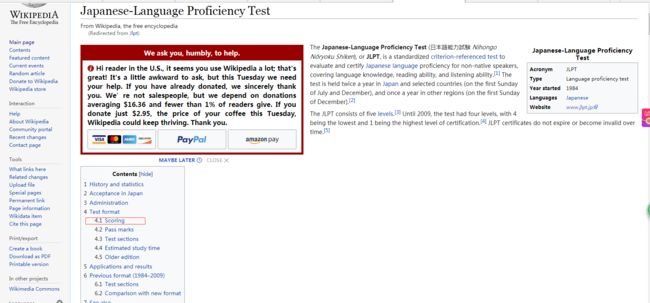
来看上图中标红的这个计分方式一项。

这里我们不看下面的pass marks那一项,这个其实要考试的同学应该都比较清楚了吧,比如分为3个部分,每部分60分,每项不得低于19分,总分90分及格blablabla。。。
我们还是关注scoring这一段的内容。
这一段,其实第一句就是最为重点的内容,说的是这个考试对于通过还是不通过的分数计算是基于一个叫做item-response theory(下面简称IRT)理论的东西。原始的分数是不用来决定你通过与否,以及显示在最后的分数报告中的。最后决定你能不能通过的分数,也就是你看到的报告的分数,都是通过这个IRT的算法进行过缩放的!!
读到这里,我就隐约感受到,传说中的玄学的计分方式,包括这个考试的改卷还能判断你是不是蒙的,应该就是这个IRT的东西搞的鬼。
没办法,要揭开这个神秘的面纱就必须再点开这个item-response theory去看看了。
这个东西打开之后可以切换到中文,虽然中文的词条没有英文的详尽,不过内容已经够我们大概了解一下这个东西是怎么左右JLPT的算分方式的了。
https://zh.wikipedia.org/wiki/%E9%A1%B9%E7%9B%AE%E5%8F%8D%E5%BA%94%E7%90%86%E8%AE%BA
上面是中文的WIKI链接,有兴趣的也可以自己去看看。
同样考虑到可能有的同学打不开,这里还是截图来说下这个玩意儿大概是讲了个什么东西。

上图是对这个翻译过来叫项目反应理论--也就是IRT的东西的一些介绍。看看图中的介绍应该就能明白,总之就是为了让考试/测试能更为准确的去贴合这个测试想要反应的被测试人的某项特征的程度而被研究出来的一个神奇的玩意儿。
而在这里,就是为了让JLPT这个考试的计分方式,能够更为准确的反应参加考试的人真实的日语水平。
下面是这个东西的数学模型。
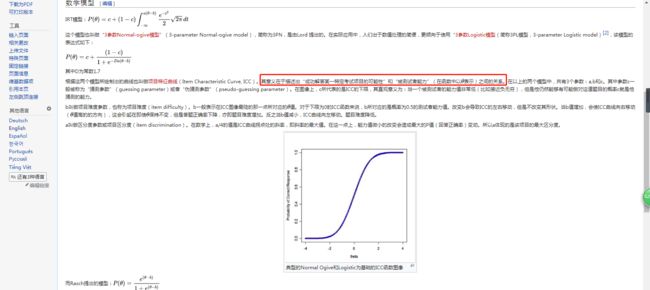
可能字有点小,不过没关系,估计没多少人想仔细的去看这个。
这个东西的重点其实就是这个下面这个公式

第一个模型不讨论了,官方已经说了“在实际应用中,人们出于数值处理的简便,更倾向于使用“3参数Logistic模型(简称3PL模型,3-parameter Logistic model)”也就是上面的这个。
然后其a,b,c三个参数决定了这个函数的图像

这里贴上官方的解释一个参数一个参数的解释一下,可能会有不正确的地方,只是我个人的理解,如果有错误,还望指正。
根据这两个模型所绘制出的曲线也叫做项目特征曲线(Item Characteristic Curve, ICC)。其意义在于描述出“成功解答某一特定考试项目的可能性”和“被测试者能力”(在函数中以θ表示)之间的关系。
横坐标θ值,这里是用来表示“被测试者能力”,取值区间是负无穷到正无穷,纵坐标p,表示做对这个题的概率,取值范围是0-1。
对于这个我的理解是这样的。假设有一个英国人叫Ronnie O'Sullivan(后面简称火箭),不懂汉字,也不懂假名,那么他去做一到JLPT的试题,可以假定他的能力值为0,而题目都是选择题,假设是4个选项,那么他能做对这个题的概率就跟不看题用投骰子的方法做题的人做对的概率是一致的,就是25%。
所以我们根据上面这个图像,可以看到在能力值为0的时候,做对的概率是50%,也就是所测试的题目只有两个选项,瞎蒙的正确率才会是50%。
所以能力值越高(对应日语水平越高),能做对题的概率就越大,这个很符合我们的直觉。
可是能力值低到一个低于0的数又是怎么回事,可能一下子有点懵。我是这样去理解的,假设有一个日语很好的人,本来能力值应该是挺高的,但是他在考试的时候就故意反着选,就是不选正确的答案,争取考出0分试卷(如果所有题都只有2个选项,且把每个题都选上选项,要考出0分也挺难的)。可是这样的情况下,他依旧有概率做对这个题,而对于他本来的打算来说就是他其实选错了。
所以哪怕一个人的能力值接近负无穷,也是有一定概率做对题的。这样解释不知道大家有没有明白一点。
那搞清楚了这个图和模型的XY坐标是用来表示什么的,我们下面就来看看他的3个参数是如何影响他的图像的。
在以上的两个模型中,共有3个参数:a,b和c。其中参数c一般被称为“猜测参数”(guessing parameter)或者“伪猜测参数”(pseudo-guessing parameter)。在图像上,c所代表的是ICC的下限,其直观意义为:当一个被测试者的能力值非常低(比如接近负无穷),但是他仍然能够有可能做对这道题目的概率c就是他猜测的能力。
这是官方对参数c的解释,我们直接来看,c的值的变化会怎样对这个图像产生影响。
其实我个人感觉这个c就是对这个图像的做对概率的取值区间做一个限制,不仅仅是只代表下限,官方说到的是这个c的直观意义为这个人的能力接近负无穷,但是仍然有可能做对这个题目的概率。那我其实觉得那如果这个被测试者的能力接近正无穷的时候,他能做对这个题的概率应该是1-c。
这个地方官方没有特别说到,有可能我的理解有误,不过我觉得这样理解也能说得过去。因为一般情况这个c估计都是取0(其实是一个无限接近于0的数),所以在图像上看这个图的Y坐标的取值范围都是在c-(1-c)中间取值,因为c接近0,所以取值范围还是0-1之间。
接下来看下一个参数。
b叫做项目难度参数,也称为项目难度(item difficulty)。b一般表示在ICC图像最陡的那一点所对应的θ值。对于下限为0的ICC函数来说,b所对应的是概率为0.5的测试者能力值。改变b会导致ICC的左右移动,但是不改变其形状。当b值增加,会使ICC曲线向右移动(θ值高的的方向),这会引起在即使θ保持不变,但是答题正确率下降,亦即题目难度增加。反之当b值减小,ICC曲线向左移动。题目难度降低。
看着感觉好像又是很难理解的样子,还是打个比方来解释。还是刚才的那个没学过日语汉语的火箭,刚刚做了一道2个选项的题,感觉良好,起码还有一半的概率能对嘛。现在做下一道题,发现题目下面的选项变成4个了!!反正看也看不懂题和选项,还是瞎选吧,不过现在这个题火箭做对的概率就只有25%了。
而官方给出的对于b参数的意义解释是,b所对应的是概率为0.5的测试者能力值。也就是同样是这道选项是4个的选择题,要达到50%的正确率的话,得先具备排除两个错误答案的能力值,假设这个时候的题目是一个这样的选择题:

这种题大家仔细研究应该就知道,是比较典型的2-2组合选项的题目。
1和3都是聞いて,而2和4都是聞かせて,这是第一组2个不同区分一组选项
然后1和2都是てくださる一方で,3和4又都是ていただく中で。
首先这个题的正确答案是4,要能选出4,需要掌握这个题的对于上述两个不同的知识点,如果只掌握其一,另一个不知道的话,就只能排出2个选项,然后又是50%的概率去蒙了。
而要掌握这两个知识点其中之一,就需要一定的能力值。这个能力值也就是JLPT考试想要知道的被测试者的日语水平。
同样的,如果这个题的4个选项不是这种两两搭配的,而是4个完全不同的东西,让你去选,你要能有50%的正确率,有一种情况是你知道两个选项不能选,另外两个不确定。不过这种题也有一种情况就是被测试者正好只知道一个选项的意思,且能选入题中符合题目的意思。哪怕其他三个都不知道,这时候被测试者也能做对这个题。
所以这个决定一个题目的难度,这里是项目难度,也就是b参数的值的具体的大小,让人去界定的话,可能界定范围不会太清晰。
但是如果将所有的被测试者(wiki上记载的2010年--2016年每年参加N2考试的人大约在10-15W,包括在日本本地参加考试的考生)的结果作为一个训练数据集去对一个机器学习模型进行训练。那最后会得出一个结果就是在这一年的这次考试中,这个题的难度大概是多少。这可比人去界定的准确多了。
这个项目难度值(也就是题目难度值),是一个非常非常非常重要的指标。这个东西很大程度的左右了我们最后的能力考分数。不过这个我一会儿把最后一个参数a讲解完之后再来详细说明。
现在我们先来看看最后一个参数a是什么意思。
照旧,贴上官方的原版说明
a叫做区分度参数或项目区分度(item discrimination)。在数学上,a/4的值是ICC曲线拐点处的斜率,即斜率的最大值。在这一点上,能力值微小的改变会造成最大的P值(回答正确率)变动。所以a体现的是该项目的最大区分度。
是不是感觉比刚才的那两个参数的官方解释要更复杂一点。不要方张,我们还是一点点的来看他最后表达了什么。
对于官方给出的解释,我们去关注这个a/4是ICC(图像)曲线拐点处的斜率,即斜率的最大值。可能有的同学已经忘记了数学上对于拐点的定义是啥了,这里我要是说什么就是函数的凹凸区分点,2阶导数为0的点啥啥啥的,估计又得把人绕蒙了。
简单粗暴,就是你凭直觉也能找到的。这个图像坡度最大的那个地方,就是它的拐点。

在官方的那个图上就是这个点了。不过实际上某一个题的ICC(图像)不会长得这么标准。
我大概的画了一个图像,可能会是长这样的。

绘制这个图像的想法是按照我之前的假设,被测试者能力值为0的时候,比如英国人火箭(真实的火老师可能还是会一些中文的吧/doge)。能正确做对题的概率应该是在25%的。
然后考虑到某些情况的某些题,ICC图像的拐点不一定是在能力值为0的时候,所以稍微把图像的拐点放在了0-1之间的某一点。当然这个能力值也是个抽象的,不能说能力值为1具体代表了一个什么水平。
有点扯远了,我们还是回到正题来聊这个参数a。
根据官方的解释,图像的拐点处的斜率等于a/4。所以我们知道当a的值越大的时候,拐点处的斜率也就越大,整个图像从低点到高点就越陡峭。
而当a的值越小的时候,相反的拐点处的斜率越小,整个图像呈现的从低点到高点的曲线就越平缓。
这个被称为该项目的最大区分度的参数a。我们举个例子来说一下可能要更明白一点。
就好比词汇语法的问题1中的题,比如这个:

跟问题6的题来比较下,比如这个:

同样是考察词汇,问题1的题型就是a的值很大,图像很陡峭的,问题6的题型就是a的值较小些,所呈现的图像会更加平缓。
这里可能有的同学会觉得这个a不也是跟参数b一样是表示项目的难度的么。其实不然,同样是问题1的题,如果一个题考的是单词青い(あおい)和单词瀬戸際(せとぎわ),其实难度参数b相差很大,但是参数a的项目最大区分度是没什么变化的,因为就是一个单词,你知道就是知道,不知道就不知道了。
所以这里的参数a,我们可以认为是这个题目的综合难度,a的值越大,则是曲线越陡峭,相对的综合难度越小,考察的能力纬度越少,你或许正好只需要知道某个很小的知识点,就能做对。比如单词读音题。而a的值越小,曲线越陡峭,相对的综合难度就更大,考察的能力纬度越多,比如问题6的词汇正确使用题,要做对这个题除了你对这个词的意思明确之外,还需要你对他的适用场合也很清楚,另外的,还需要你能读懂选项的意思,这也需要你会这个选项里面出现的单词和语法了。然而像问题1的题目,我认为没人回去鸟那个题目的题干的句子是啥意思吧,都是看到画线的词直接选假名。
那么现在这个所谓的IRT的常用数学模型的3个相关参数,还有它的图像的数学意义都已经解释完了。接下来,就是探讨下这个玩意儿是怎么左右我们的能力考分数了。
通过刚才的分析,我们假设能力考试的机构可以通过把本次所有的试卷收集之后作为训练数据,通过机器学习算法,标定每个题的难度和项目区分度(题目综合难度)。
那现在机构可以再通过每道题目的难度,和被测试者做各种难度的题的正确状况,通过一套算法,标定每个被测试者的能力。
比如之前所述,题目难度低的题,被测试者的正确率在7-80%,题目难度约高,被测试者的正确率线性下降,则此被测试者的能力值和做出各种难度的题的概率期望是相符合的。
而现在我们考虑一个情况,还是火箭火老师吧,他这次运气不错,虽然不会日语,但是乱蒙一通之后出来对答案,发现自己居然对了一半还多一点的题。感觉自己应该能过,然而最后分数出来发现根本没到90分,还是没过!这是为啥?
我想这个时候不少同学应该已经知道其中的原由了。有的同学估计还没反应过来上述的这套理论是怎么作用在分数上的。那我还是继续打个比方来解释吧。
我们假设火老师这次对了55道题,试卷一共有105道题目,正确率是52.38%。如果在看完这篇文章之前,这种乱蒙的结果,我们凭直觉来看,应该是过了对吧,毕竟满分180,蒙对一半以上的题能过是没毛病的啊。
因为全是蒙,加之无论题目难度如何,分值如何,都差不多是无差别的占据52.38%的正确率。如果没有这套IRC模型加持的话,火老师就真的过了啊。
可是有了这套IRC加持之后,乱蒙想过哪有那么简单。
因为是对所有难度的题都占据了52.38%左右的正确率。所以在机器分析之后,判定你的能力基点是以简单题为上限的,正常人都应该是在难题上的正确率要远小于简单题的正确率的。也就是机器分析被测试者的能力值,最根本的依据是通过简单的题来标定的。只有简单的题能做对,往后做难题也保持教高的正确率,机器判定的能力值才会高。而简单的题的正确率就不怎么样,哪怕难题正确率还不错(相对于一般情况),也会被判定为蒙的!
这个是很符合逻辑的事情。
①1+1=?,②16+85=?,③32*5=?④(sin(π/2) + 5)*8=? ⑤y=e^x,y'=?
就像上面的5个题,难度是递增的,而被测试者能做出第几个题是取决于他的数学能力的。
总不能说这个人连1+1都算不对,还能算对后面的4个题吧。
所以在简单题上的表现是低于一般人的火老师,被系统判定为能力值低,在简单题的正确率表现为52.38%,那系统会认为火老师在难题上能做对的概率可能仅在30%左右,就算实际的正确率是在52.38%,但是系统认为火老师在难题部分只能得到30%分的不能再多了。
如此这般,我们简单粗暴的假设简单题的分数占70%(大约126分),难题占30%(54分)。最后火老师的成绩就变成了
126 * 52.38% + 54 * 30% = 82.1988
火老师就这么本来满心欢喜的以为自己过了,却被最后的结果给打击到了。表示这尼玛是什么蜜汁评分系统,是不是改错了,自己明明是对了一半以上的题,辣鸡玩意儿,再也不考日语能力考了。
到这里,关于JLPT的评分规则,也就大致的介绍完了。下面就总结一下结论吧。
结论
JLPT的计分是有一套复杂且科学的数学模型去对最后实际的分数进行重新标定的。
如果在简单题上表现不好,可能哪怕你难题蒙对了不少,最后的成绩也不会理想!
系统真的可以知道你做难题的时候是不是靠蒙蒙对的。所以烧香拜佛求蒙的题多对一点的同学,不如更有针对性的求在不会的简单题上能蒙的都对。
如果你一题不会全篇蒙(或者大范围蒙),最后正确率在50%以上,但是最后没过,不要吃惊,如果想知道为什么改卷的能知道你是不是蒙的,那就再回头读读本文的正篇部分吧。
感谢各位能读到这里。如果有机会以后还写点啥,还会再见的。
PS.
1.文中出现的真题其实是N1的题,因为我手上没有N2的电子版的题。N1题是18年7月的题。
2.文中一直用来打比方的火箭火老师,是我最喜爱的斯诺克选手,
憨豆
奥沙利文。估计有的同学是知道的。
3.由于社畜每天的可支配时间有限,这篇文章不是一天写完的,断断续续还是写了好多天,所以可能有逻辑不连贯的地方,还望见谅。