最近由于工作需要,需要一个关于现在所有手机型号的信息表。看了很多电商网站都会有手机种类和对其的详细介绍,但检查元素发现获取这些信息远比想象中要难,现在很多网站做的反爬措施还是很到位的。在开发者工具中根本找不到一个合适的response对象。于是联想,是否能从app端突破这个限制呢,突然想起来在app端可以用抓包工具进行抓取request和response等其他所有信息。于是启发是否可以通过这点来越过爬虫瓶颈呢?
前期准备
研究了研究这个app抓包工具,感觉还是很好用的。所谓“工欲善其事必先利其器”,反正能达到所要求目的就好,感觉这个工具还是不错的,先推荐给大家。https://www.charlesproxy.com/
开始
在爬取时,我选了爱回收这个app进行了实验,感觉其实这个app的信息还是蛮全的,翻了翻他的手机回收的信息全是我想要的信息。
至于有关Charles怎么使用,请大家查阅其他资料。此处不做多的介绍。
观察
在对app的手机列表进行查阅时,可以看到在charles中抓来的包
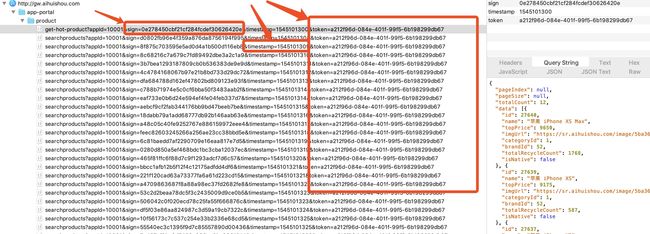
仔细观察可以看到请求的url、请求方法、请求头、请求体、响应头、响应体等。
其实一开始的想法还是正统的爬虫想法,仿照app的请求的方式进行发送请求欺骗服务器来获取数据,但在postman中进行测试的时候传入这些值确实能够获取到刚才已经发送过请求的数据json包,但是对于未发送过的请求的数据来说返回的却是一个null。
不难发现其实在发送请求时,在请求的url中参数中有sig、timestamp和token,这三个参数除了时间戳剩余两个都是加密过的,如果我仿照爬虫的话我需要带上这几个参数,对于token来说这几次请求token都是一样的,可以暂时写一个固定的放进去,时间戳也可用time模块来获取,但是sig这个参数不知道是有什么参数构成并且加密的,这就让整个过程变得很棘手。在仿照浏览器发送请求时我需要知道这个sig参数是有什么构成并且加密的,看似是个md5加密,但md5加密也不可逆,那就只能暂时放下这条路。
但是经过研究这个charles工具发现每次其实都是带着response的,我就直接人工存下来就好了然后通过脚本处理一下这些文件就拿到了想要的数据。
文件批量处理
批量存储这些文件到本地,其实感觉这个数据还是对自己的很友好的,每个文件中都是标准的json格式,但唯一不好之处就是突然发现这些文件都没有后缀名称,总共保存的文件就有好几百个,于是我写了一个shell脚本rename.sh来批量给这些文件加上后缀名“.json”
for i in ~/Desktop/product/*;
do mv "$i" "${i%}.json";
done
数据处理
这样有了json文件的话就比较好获取到我想要的信息了,将json转成字典,分析结构就可以去除我想要的信息进行相应操作了。
首先获取指定目录的所有json文件,先将路径加入到列表中。
# 获取当前指定路径下的所有json文件
def parse_dir(root_dir):
"""
:param root_dir:
:return:
"""
path = Path(root_dir)
all_json_file = list(path.glob('*.json'))
parse_result = []
for json_file in all_json_file:
parse_result.append(str(json_file))
return parse_result
通过json路径读取json,并将其转换成字典以便后续操作。
# 读取json
def load_json(file):
"""
:param file:
:return:
"""
file = open(file, encoding='utf-8') # 设置以utf-8解码模式读取文件,encoding参数必须设置,否则默认以gbk模式读取文件,当文件中包含中文时,会报错
file_data = json.load(file)
data_list = file_data['data']
phone_list = []
for item in data_list:
phone_name = item['name']
phone_img = item['imgUrl']
top_price = item['topPrice']
brand_id = item['brandId']
phone_name = format_name(phone_name) # 格式化手机名称为正确格式
img_download(phone_name, phone_img) # 根据json中的图片url下载图片到指定位置
phone_dict = {
"phone_name": phone_name,
"phone_img": phone_img,
"top_price": top_price,
"brand_id": brand_id,
"img_path": os.getcwd() + '/image/' + phone_name + '.png'
}
phone_list.append(phone_dict)
return phone_list
转换成字典后直接写入到EXCEL表格中就好了。
# 生成excel文件
def generate_excel(row, col, expenses):
"""
:param row:
:param col:
:param expenses:
:return:
"""
workbook = xlsxwriter.Workbook('./tran_data.xlsx')
worksheet = workbook.add_worksheet()
bold_format = workbook.add_format({'bold': True}) # 设定格式,字典中格式为指定选项
money_format = workbook.add_format({'num_format': '$#,##0'}) # bold:加粗,num_format:数字格式
date_format = workbook.add_format({'num_format': 'mmmm d yyyy'})
worksheet.set_column(1, 1, 15) # 将二行二列设置宽度为15(从0开始)
worksheet.write('A1', '手机名称', bold_format) # 用符号标记位置,例如:A列1行
worksheet.write('B1', '手机图片', bold_format)
worksheet.write('C1', '最高价', bold_format)
worksheet.write('D1', '品牌ID', bold_format)
worksheet.write('E1', '本地图片地址', bold_format)
for item in expenses: # 使用write_string方法,指定数据格式写入数据
worksheet.write_string(row, col, str(item['phone_name']))
worksheet.write_string(row, col + 1, item['phone_img'])
worksheet.write_string(row, col + 2, str(item['top_price']))
worksheet.write_string(row, col + 3, str(item['brand_id']))
worksheet.write_string(row, col + 4, item['img_path'])
row += 1
workbook.close()
return row
最后附上项目源码地址https://github.com/PeterPZhang/Simple_json_download_transformxlsx