KNN最邻近结点算法
一、算法原理
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。

二、算法实现
import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k, X_train, y_train, x):
assert 1 <= k <= X_train.shape[0], "ERROR: k must be valid!"
assert X_train.shape[0] == y_train.shape[0], "ERROR: the size of X_train must equal to the size of y_train!"
assert X_train.shape[1] == x.shape[0], "ERROR: the feature number of x must be equal to X_train!"
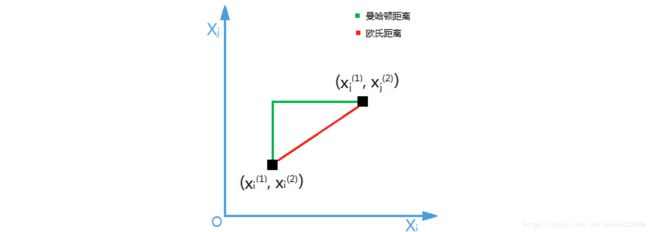
# 求被测点到所有样本点的欧氏距离
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
# 返回按距离升序排列后的索引列表
nearest = np.argsort(distances)
# 返回前k小的距离
topK_y = [y_train[i] for i in nearest[:k]]
# collections的Counter()方法:求出数组的相同元素的个数,返回一个dict:{key=元素名,value=元素个数}
votes = Counter(topK_y)
# most_common()方法:求出最多的元素对应的那个键值对
return votes.most_common(1)[0][0]
示例:
# 数据集
# 特征
raw_data_x= [[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所属类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 预测
x = np.array([8.093607318,3.365731514])
predict = kNN_classify(6,X_train,y_train,x)
predict
三、scikit-learn KNN
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train, y_train)
示例:
训练数据集同上
# 预测
x = np.array([[8.093607318,3.365731514]])
kNN_classifier.predict(x)
四、鸢尾花示例
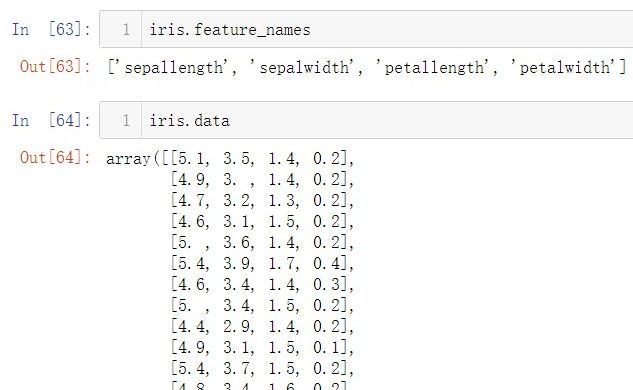
1.数据准备
(1)导入数据
from sklearn.datasets import fetch_openml
iris = fetch_openml(name='iris')
(2)初步了解数据
(3)切分数据集
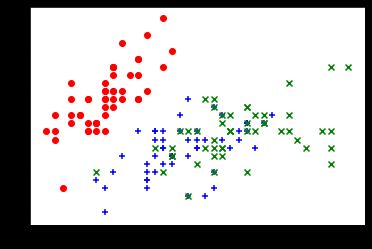
①以花萼长度、宽度为特征值
X = iris.data[:, : 2]
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
y = iris.target
y = encoder.fit_transform(y)
# 数据可视化
plt.scatter(X[y==0,0], X[y==0,1], color="red", marker="o")
plt.scatter(X[y==1,0], X[y==1,1], color="blue", marker="+")
plt.scatter(X[y==2,0], X[y==2,1], color="green", marker="x")
plt.show()
②以花瓣长度、宽度为特征值
X = iris.data[:, 2:]
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
y = iris.target
y = encoder.fit_transform(y)
# 数据可视化
plt.scatter(X[y==0,0], X[y==0,1], color="red", marker="o")
plt.scatter(X[y==1,0], X[y==1,1], color="blue", marker="+")
plt.scatter(X[y==2,0], X[y==2,1], color="green", marker="x")
plt.show()

- 训练集测试集切分
def train_test_set_split(X, y, test_ratio=0.2, seed=None):
assert X.shape[0] == y.shape[0], "ERROR: the size of X must be equal to the size of y!"
assert 0.0 <= test_ratio <= 1.0, "ERROR :test_radio must be valid!"
if seed:
np.random.seed(seed)
# 返回随机打乱排列后的索引
shuffle_indexes = np.random.permutation(len(X))
tets_size = int(len(X) * test_ratio)
test_indexes = shuffle_indexes[:tets_size]
train_indexes = shuffle_indexes[tets_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, y_train, X_test, y_test
X_train, y_train, X_test, y_test = train_test_set_split(X, y, 0.2)
或者使用scikit-learn封装方法
import machine_learning
from machine_learning.module_selection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y, test_radio=0.2)
(4)训练模型
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=6)
knn_clf.fit(X_train, y_train)
(5)测试模型
y_predict = knn_clf.predict(X_test)
print("模型分类准确率为{}".format(sum(y_predict==y_test)/len(y_test)))
