本论文发表于2016年,介绍了一个完整的推荐系统结构,包括离线训练和线上serving,也涵盖了许多算法落地的细节,工程性很强,建议反复阅读。
1. 简介
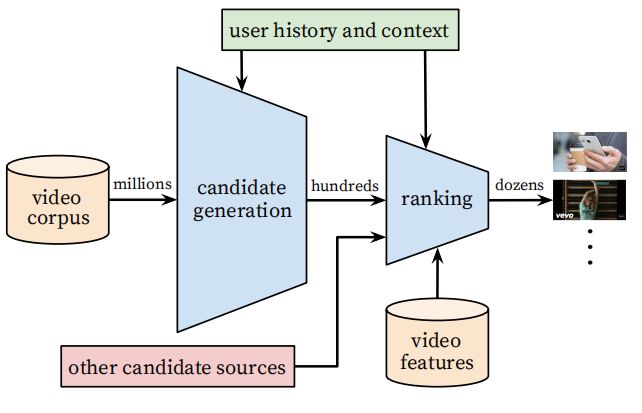
Youtube推荐系统包含两个主要模型:candidate generation model(召回)和ranking model(排序),这也是现今主流推荐系统的普遍架构。 系统架构如图1所示。
模型需要解决的问题:
- 大规模数据
Youtube是世界上最大的视频分享网站,其推荐系统必须使用分布式算法以及高效率的在线serving系统。 - 时效性
Youtube的语料库每秒钟都会更新许多视频,推荐系统必须能够对新上传的视频以及用户最新的动作做出及时反馈。 - 噪音
用户的历史行为特征十分稀疏,模型很难学习到用户真正的喜好,往往会学到更多的噪音。
2. System Overview
Youtube推荐系统的candidate generation和ranking分别用两个神经网络来完成。
Candidate generation model将用户在youtube上的行为历史作为输入,从中筛选出一个较小的候选视频集。选出来的视频一般都是与用户高度相关的。这里一般使用一些粗粒度的特征,如观看视频的ID,搜索历史,用户侧统计特征等。
Ranking model会为上一步选出来的候选视频集中的每个视频进行打分,打分最高的视频就会被展示给用户,排在第一的就是系统认为用户最感兴趣的视频。与candidate generation model不同,ranking model会用到用户和视频更加精细的特征。
模型迭代时会用许多离线指标,如precision, recall等等,但最终评价模型的标准则采用了线上a/b test实验,因为离线和在线值表不总是相符,而且离线指标无法反映用户行为的变化,
3. Candidate Generation
3.1 分类模型
召回模型将推荐系统抽象为了一个的多分类问题,即预测某个用户(以及相应的context )在某个时刻观看的某个视频属于哪一类,用公式表示如下
式(1)是一个softmax函数的形式,其中表示pair的embedding,表示候选视频(candidate video)的embedding。DNN的任务就是学习一个用户历史和conntext到用户embedding的映射,用于式(1)的softmax函数中对videos进行分类。
训练模型使用的输入是用户观看的历史,这是一种隐式(implicit)的特征。虽然youtube数据中有许多显式的(explicit)特征(如用户上滑/下滑,参与调查等),但这些特征往往非常稀疏,很难反映用户兴趣的长尾部分。召回的模型更注重涵盖用户的各种行为兴趣,因此使用隐式的特征来训练模型。
对于海量数据的处理方式
由于该模型面对的是数十亿计的用户和视频输入以及数百万计的类别总数,性能问题是工程实践的重点。youtube采用了以下方案来解决性能问题:
- 负采样(negative sampling)
youtube的样本集中,正样本被定义为用户完整地观看一个视频,而负样本的数量远远多于正样本。这里根据负样本的分布特征进行采样,然后在给样本以权重来修复这一采样操作。正负样本都是用cross entropy作为损失函数。实际中,与传统的softmax相比,这一负采样操作可以加快100倍以上的速度。 - serving时使用KNN代替softmax
在线serving的时候,我们需要计算出top N个candidate video展现给用户。同时给百万甚至更高级别的item打分对模型性能要求很高,因此在serving时使用了KNN方法来代替softmax。
3.2 模型结构
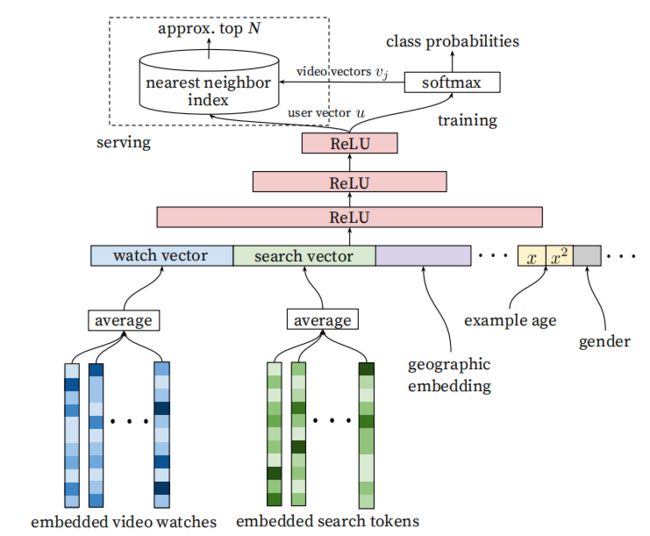
模型结构没有太多创新的地方,就是embedding + DNN模式,对序列特征采用了averag pooling,见图 2 所示。
3.3 特征和模型探索
"Example Age" 特征
youtube用户往往会对新鲜的,刚发布的视频感兴趣,但模型是基于历史数据训练的,因此会产生偏差,打分会更偏向训练数据时间窗口的平均值,而不会着重为用户推荐新鲜的视频。因此模型训练时加入了 "example age"的特征,标识了每个video已经上传了多久。线上serving时,会着重为用户推荐新上传的视频。
特征和模型深度
DNN采用了用户最近观看和最近搜索作为主要特征embedding维度是256,序列长度选择了最近50次。论文尝试了不同的DNN深度和宽度,发现使用复杂的DNN结构,其预测精度也会随之上升。
4. Ranking
排序的首要功能就是使用曝光数据来对candidate generation的结果进行筛选和校正。排序的模型结构与召回类似,但使用了更多细粒度的特征,这是因为排序只需要对召回的数百个视频进行打分,是更加精细化的预测。
A/B test的中使用的排序指标是用户的观看时长。之所以不用点击率,是因为一些“标题党”的视频可能会有很高的点击,但用户并不感兴趣。
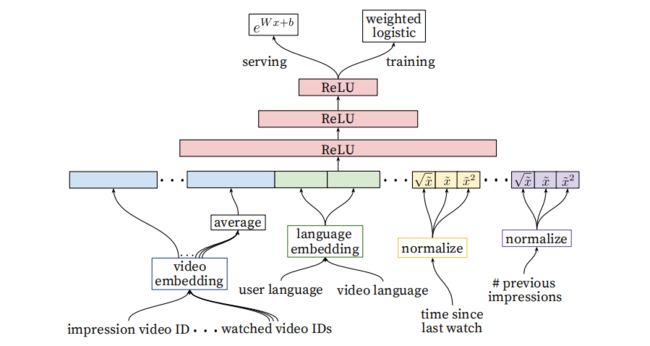
排序模型结构如图3所示,与candidate generation类似,只是输入特征更多,而且输出用了logistic regression.
4.1 特征处理
Ranking model 使用了多种维度的特征,binary/多维特征都有涉及。特征被分为item和user/context两类,在serving时前者计算多次,后者只计算一次。
特征工程
特征工程的难点是如何对用户序列进行利用。其中用户上次的行为是最重要的一个特征,如用户上一次观看的视频ID。另外一个重要特征是某个视频在该用户下的曝光频率。举个例子,如果最近曝光给用户但未点击的视频,在下次观看时就不会出现在推荐列表中。
类目特征的embedding处理
对于每个类目特征(categorical feature),embedding size的大小与其vocabulary的大小为正相关。特征空间中的unique values越多,embedding size越大。对于video ID, 搜索词条等较大的ID空间,会对所有的ID进行一个简单的点击频率排序,选出TOP N个ID进行embedding,其余的直接映射为0。
模型还采用了share embedding,如用到video ID的所有特种都会share,这样有助于提升模型的泛化能力,加速训练以及减小模型存储空间。
连续特征的归一化
神经网络对输入数据的分布十分敏感。对于连续性特征,会将其归一化到[0,1)区间内。同时,对于特征还会并行输入和,以让模型可以从不同的空间学习特征,增强模型的表达能力。实验证明归一化的离线指标会有收益。
4.2 对观看时长进行建模
Ranking模型的正负样本是按照是否点击来划分的(这点与candidate generation不同)。模型使用weighted logistic regression作为输出,cross entropy作为损失函数进行训练。这里的weighted是指用播放时长来为所有的正样本加权,而负样本给以相同的权重。这样学习到的odds就是播放时长的期望(具体推导见论文4.2节)
4.3 DNN宽度和深度
结果表明DNN的宽度和深度对模型效果都有影响。
5. 总结
本论文将youtube深度推荐系统分为两个部分:candidate generation和ranking。
candidate generation面对的是数以亿计的视频语料库,其目标是从中筛选出与用户高度相关的子集供排序部分进一步优化。对于海量数据采用了负采样的方式,提升了训练效率;模型方面采用了经典的embedding + DNN结构,并在serving时将softmax换成了KNN以提高打分效率。训练数据只使用了user watch和user query特征以及部分context特征,同时加入了example age的权重,提升了推荐的时效性。
Ranking模型面对的是hundreds数量级的视频打分,采用了更精细化的特征。相关特征间会share embedding,对连续性特征会采用归一化。模型结构与candidate generation类似,但用了logistic regression作为输出函数,并在serving时使用简单的指数函数来打分。candidate generation和ranking的模型都对深度和宽度敏感。