原文: https://medium.com/adobetech/best-practices-for-serverless-observability-a99d8dc8af5c
WRITTEN BY
Ran Ribenzaft
Co-Founder & CTO @epsagon | AWS Serverless Hero | Entrepreneur, passionate about serverless and microservices.
翻译:祝坤荣(时序)
现在看起来每个工程师都熟悉serverless这个词,但离在生产环境大规模使用还很远。意思是,实际上,大部分人在使用serverless时还是没有经验的,并且由于这个原因,很多最佳实践还是缺失的。
在这篇文章里,我们会深入可观察性,它是每个工程和运维团队在移动到生产环境的核心组件。我们会讨论每个重要的基础:度量,日志和分布式追踪,并提供serverless在真实世界的最佳实践的例子。
可观察性中的度量
传统简单直接做监控的套路就是去看度量数据。 度量, 尤其是度量中体现的趋势, 可以展示出我们系统的基本统计情况,比如:
• CPU或内存的使用峰值
• 流量和请求的趋势
• 我们使用的跨服务的延迟情况
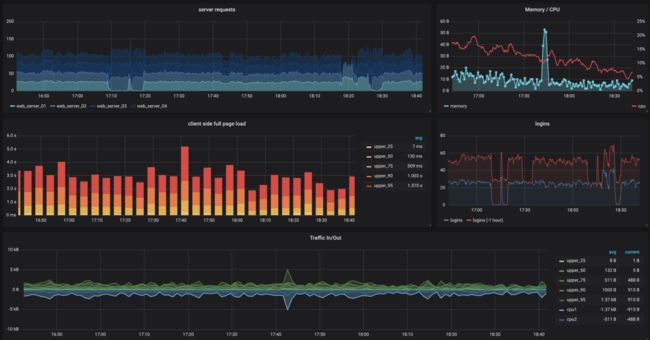
Google SRE图书中指出了监控分布式系统的4个黄金指标是延迟,流量,错误和饱和度。尽管看起来很简单,它仍然需要一些经验和时间来进行正确的监控。这个流程包括:
• 从环境,应用,资源和服务上收集所有度量指标。这包括,比如,我们的k8s集群,云资源,Java和Node.js应用,我们的Redis集群。想要记录这些度量信息每个实体都需要一套不同的处理方法。
• 将度量信息传给一个统一平台,它要处理正确的量级,聚合所有度量指标,展示正确的数据(比如,用百分位替代平均值)。
• 最终,我们需要为每个应用或环境建一个仪表盘,并且为其中重要的定义合适的报警。
在serverless化后,CPU和内存变得不那么相关了;不要只盯着调用和错误的基本图表。多看和观察你的function有的每个动作。你调用的任何API都需要被监控。
可观察性中的日志
度量指标只能告诉我们’好或坏’。他们不会提供任何信息和一种方式来告诉我们为什么一个应用不工作了。
要定位问题的种类,我们需要理解我们代码或服务的流程。要达到这个目的我们要打印包括所有从开始到详细异常的日志(到一个文件,socket或服务)。
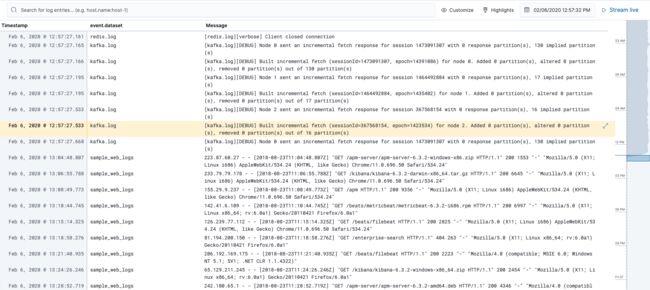
Elastic中的日志
每个工程师都熟悉定位问题或bug的场景和要找到正确日志时持续升高的压力。这些问题都是由于日志的一些缺陷和固有的问题:
• 它们基本上是手动的。日过你没有记录一些事情,它不会出现(然后你补了日志,部署你的代码,并且等着问题再次出现)。
• 通常,它们没有上下文。这表示你要找到你想要找的日志,你需要对发生在你代码或服务的事件的相关日志进行搜索。
• 在众多服务中有很多的日志,这很难在它们之间进行导航。
想要从日志中得到有效的信息:
• 在你的日志行中填加元数据;例如,服务/函数function名称,场景,请求ID等。
• 在你使用的代码中自动化日志事件的处理。我们会在下面追踪章节讨论这个。
• 保证在你的服务中用正确的方式索引日志,然后你可以使用工具来进行分析。使用工具分析日志(用元数据和维度)可以帮助你理解你应用中的复杂趋势。
• 记录自定义的度量指标。这也适用于之前的基础指标,但它可以帮你发现业务核心指标。比如,上周用户注册的数量。
可观察性中的分布式追踪
追踪是可观察性中的重要基础,它在微服务和serverless中度量和日志中扮演重要角色。追踪的目的是收集一次操作的数据,这样我们可以在不同的服务中看到流程。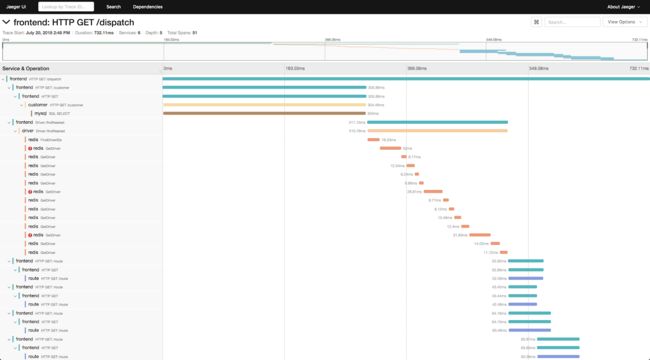
在一个运行微服务和serverless的现代应用中,我们需要对追踪的“分布式”部分有更多的关注。追踪里最流行的标准是OpenTracing(或新的OpenTelemetry)。分布式追踪描述了一个框架来收集关于事件的数据(比如,一个DB查询,我们会收集主机名,表名,持续时间,操作等),这叫做spans与上下文。它也描述了在你的服务中注入和抽取“追踪ID”。
有效在代码中抓取追踪的一种推荐的方式是进行增强instrument(https://epsagon.com/blog/instrumentation-for-better-monitoring-and-troubleshooting/),所以每个调用不需要手动。Instrumentation增强修改了一些调用;比如,每次你调用HTTP,它会路由到一个中间件,由其保存追踪信息。
由于追踪是被一种结构化的方式捕捉的,它让我们可以对日志问一些更有意思的问题;比如,你可以查找所有“insert”操作超过300ms的事件,其被打了一个特定customer ID的标签。

追踪捕捉了结构化数据
要牢记以下几个关键问题:
• 增强和追踪你的应用是一个非常长的过程,需要长时间维护。如果你选择自己实现不会快速获胜。
• 我们只讨论了追踪收集的部分。下一步是传送它们到一些服务。Jaeger(https://www.jaegertracing.io/)可能是展现和搜索追踪信息的主流服务。
如果要从追踪中得到最大的收获:
• 用标签来充实你的追踪。标签让你们可以在你的复杂系统中精确定位事件,按维度进行分析,比如,userId=X的一个特定事件有多少次,用了多久。好的标签可以是user ID,商品ID,事件类型,或任何你系统中特定的信息。
• 因为追踪给日志加入了上下文所以它在问题定位中扮演了核心组件。要做到那样,请考虑下载追踪里记录payload。比如,每一个对DB的调用,增加查询信息;每一个HTTP调用,填加request/reponse的header和body信息。
• 要在没有任何上下文信息里在成吨的日志或图表里搜索是很难的。通过使用追踪你可以可视化这些在你系统中的复杂服务和事务。
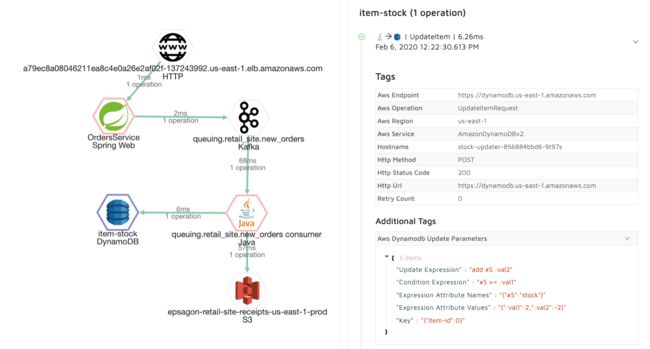
可视化追踪和payload信息是一个故障排查的强大工具(Epsagon)
总结
可观察性在每个现代应用中扮演了很重要的部分。它需要很多规划,繁重的维护来应用最佳实践。将每个基础部分分离到不同的工具可以让工程团队有很大的生产力,强化他们的合作。当选择一个工具来整合一切事物时这很重要。
另外,自动化你的流程以便它们不会对日常工程的工作流产生影响很重要。选一个受控的解决方案可以有很大的优势,就像你从云供应商选择数据库,消息队列,或服务器。
在Epsagon(https://epsagon.com/),我们在建立一个针对serverless和微服务的追踪和监控的定制方案。你过你有兴趣可以联系我们。
本文来自祝坤荣(时序)的微信公众号「麦芽面包,id「darkjune_think」
转载请注明。
交流Email: [email protected]