本篇内容
主要讲述一些常用的函数、语法,结合案例、面试题来进行实践。
日期函数
date_sub('',n) 和date_add('',n) 加减日期
select date_sub('2020-12-03',1);
+-------------+
| _c0 |
+-------------+
| 2020-12-02 |
+-------------+
select date_add('2020-12-03',1);
+-------------+
| _c0 |
+-------------+
| 2020-12-04 |
+-------------+
last_day('') 返回这个月的最后一天
select last_day('2020-02-02');
+-------------+
| _c0 |
+-------------+
| 2020-02-29 |
+-------------+
dayofweek(string date)返回所给日期为所在周的第几天
select dayofweek(‘2020-12-03’);周四
+------+
| _c0 |
+------+
| 5 |
+------+
注:返回的数字应该是真正的周几加上一,因为西方一周的第一天是周日
面试题:
求出 '2020-12-03'所在月的第一天和 所在周的周一的日期
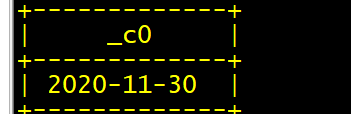
select trunc('2020-12-03','MM');
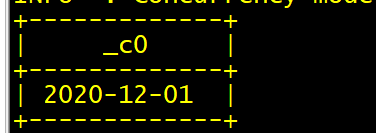
select date_sub('2020-12-03',dayofweek('2020-12-03')-2);
dayofweek 先求出日期所在的周几,然后使用当前日期-(所在周几-2) 求出周一所在的日期 1是周日 2 是周一
year(string date) 、month(string date)、 hour(string date)
datediff 计算出两个时间的差
select datediff('2020-12-04','2020-12-06');
+------+
| _c0 |
+------+
| -2 |
+------+
很明显是前面日期减后面日期
条件函数
if(exp1,exp2,exp3) 若exp1为true,则返回exp2的值,否则,返回exp3的值 相当于一个三元表达式
nvl(val,default) 判断val是否为null,如果为null,返回default,不为null,返回val
编号函数
rank() 有并列,1 1 3 但没有第二名
row_number() 不会有重复,不会有并列 1 2 3 4 5
dense_rank 有并列,有第二名 1 1 2 3 4 5
编号函数 ,给行排上编号 ,一般和窗口函数结合使用
example 面试题:
打地鼠案例
数据
u01,1,1
u01,2,0
u01,3,1
u01,6,1
u02,5,1
u02,6,0
u02,7,0
u02,1,1
u02,2,1
u03,4,1
u03,5,1
u03,6,0
u02,3,0
u02,4,1
u02,8,1
u01,4,1
u01,5,0
u02,9,1
u03,1,1
u03,2,1
u03,3,1
求连续 3次打中地鼠用户
select uid,
max(count_suc)
from
(
select
uid,
diff,
count(1) as count_suc
from
(
select
uid,
dt,
row_number() over(partition by uid order by dt) as tp,
(dt-row_number() over(partition by uid order by dt)) as diff
from tb_ds where suc=1) t1
group by uid,diff having count_suc>=2) t2 group by uid ;
注意点:
1)窗口函数 要放在from前面,侧窗口函数是放在from后面,侧窗口函数,相当于一个虚拟表
2)每一个子查询的表 记得要起别名
3)多思考
大小企业高频连续活跃用户手写sql题
这是一道大厂小厂都喜欢考察的的sql题目,思路跟上面差不多。
有数据:
+---------------+----------------------+
| tb_login.uid | tb_login.login_date |
+---------------+----------------------+
| a | 2020-11-01 |
| a | 2020-11-02 |
| a | 2020-11-03 |
| a | 2020-11-05 |
| a | 2020-11-06 |
| b | 2020-11-06 |
| b | 2020-11-04 |
| b | 2020-11-03 |
| c | 2020-11-01 |
| c | 2020-11-02 |
| c | 2020-11-03 |
| c | 2020-11-04 |
| c | 2020-11-05 |
+---------------+----------------------+
现需要查出连续活跃3天及3天以上的用户及活跃天数
思路:使用编号函数row_number() +窗口函数
1)求出每行编号
select uid,
login_date,
row_number() over(partition by uid order by login_date) dn
from tb_login;
+------+-------------+-----+
| uid | login_date | dn |
+------+-------------+-----+
| a | 2020-11-01 | 1 |
| a | 2020-11-02 | 2 |
| a | 2020-11-03 | 3 |
| a | 2020-11-05 | 4 |
| a | 2020-11-06 | 5 |
| b | 2020-11-03 | 1 |
| b | 2020-11-04 | 2 |
| b | 2020-11-06 | 3 |
| c | 2020-11-01 | 1 |
| c | 2020-11-02 | 2 |
| c | 2020-11-03 | 3 |
| c | 2020-11-04 | 4 |
| c | 2020-11-05 | 5 |
+------+-------------+-----+
2)求出登录日期与每行编号的差
select uid,
login_date,
date_sub(login_date,row_number() over(partition by uid order by login_date)) diff
from tb_login;
+------+-------------+-------------+
| uid | login_date | diff |
+------+-------------+-------------+
| a | 2020-11-01 | 2020-10-31 |
| a | 2020-11-02 | 2020-10-31 |
| a | 2020-11-03 | 2020-10-31 |
| a | 2020-11-05 | 2020-11-01 |
| a | 2020-11-06 | 2020-11-01 |
| b | 2020-11-03 | 2020-11-02 |
| b | 2020-11-04 | 2020-11-02 |
| b | 2020-11-06 | 2020-11-03 |
| c | 2020-11-01 | 2020-10-31 |
| c | 2020-11-02 | 2020-10-31 |
| c | 2020-11-03 | 2020-10-31 |
| c | 2020-11-04 | 2020-10-31 |
| c | 2020-11-05 | 2020-10-31 |
+------+-------------+-------------+
3)分组聚合求出连续登录的天数,并限制连续登录天数大于等于2
select uid,
diff,
count(1) as cnt
from
(
select uid,
login_date,
date_sub(login_date,row_number() over(partition by uid order by login_date)) diff
from tb_login
)t1 group by uid,diff having cnt>=2;
+------+-------------+------+
| uid | diff | cnt |
+------+-------------+------+
| a | 2020-10-31 | 3 |
| a | 2020-11-01 | 2 |
| b | 2020-11-02 | 2 |
| c | 2020-10-31 | 5 |
+------+-------------+------+
4)由于上述结果出现了a有两个连续登录天数在2天以上的,所以再次分组聚合求出最大连续活跃天数
select uid,
max(cnt) as cnt_login
from
(
select uid,
diff,
count(1) as cnt
from
(
select uid,
login_date,
date_sub(login_date,row_number() over(partition by uid order by login_date)) diff
from tb_login
)t1 group by uid,diff having cnt>=2) t2 group by uid;
+------+------------+
| uid | cnt_login |
+------+------------+
| a | 3 |
| b | 2 |
| c | 5 |
+------+------------+
列转行数据 使用侧窗口函数+explode 炸裂函数
列转行,将一列中多个属性 转化为 多行属性数据 相当于炸裂 ,一般使用测窗口函数+explode炸裂函数
explode(arr) 将数组每个元素炸裂开 多行数据
select name,tp
from tb_movie2
lateral view
explode(split(categorys,',')) t as tp;
行转列
行转列,将多行数据 拼接为一行数据
注意根据情况使用concat_ws(',',arr
面试题:
向分区为ds的表A 中写入数据
load data local inpath "path" into table A partition(ds="val")
自定义函数
面试题:
UDTF UDAF UDF 有什么区别?
UDF操作单个数据行 ,返回一个数据行作为输出返回对应值 1对1
UDAF 接受多个输入数据行,会产生一个数据行并输出 比如 count或者sum这样的聚合函数 返回聚合值 多对1
UDTF 操作单个数据行,返回多个数据行 返回拆分值 1对多 比如lateral view explode()
面试题:
数据倾斜的产生和解决办法
数据倾斜的现象:
mr程序程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长。
这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜。
其根本原因就是reduce之前的shuffle过程,shuffle进行抓取数据到各个reduce区中
解决办法:
1)增加reduce的并行度(个数)
2)增加内存
3)自定义分区规则,重新设计哈希散列函数,将key分配到不同的reduce上去
面试题
left join和left semi join的区别
LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。
left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。因为右表只有 join key 参与关联计算了,而left join on 默认是整个关系模型都参与计算了
右表传递关联条件给左表 相当于 in 比如 SELECT * FROM A LEFT SEMI JOIN B ON A.ID=B,ID = SELECT * FROM A WHERE ID IN (SELECT ID FROM B)
面试题:
hive中的调优
1)select尽量不要使用select * ,count(1)或者count(列名) 而不是 count(*)
2)避免count(distinct) 可以使用 count(1) group by
3)文件储存为orc格式或者parquet
使用特殊的文件存储格式 orc或者parquet
create table tb_name()
as select ... from tb_b
stored as orc/parquet 默认是 textfile
4)使用分区表和分桶表
5)开启map端聚合
6)避免笛卡尔积
7)测试数据在本地运行
set mapreduce ......name=local/yarn
8)适当的调整maptask的个数和reduce的个数
9)小表join大表 使用map端join 小文件分布式缓存处理
Hive本系列到此结束,后续尽量多出面试题及解析和思考方式。