Python动态网页爬虫入门实例
Python动态网页爬虫入门实例
- 写在前面
- 成果展示
-
- 常量定义
- 类初始化
- 车速数据爬取
- 数据持久化
- 爬虫主函数
- 写在后面
-
- 1.静态网页爬取
- 2.动态网页请求获取
- 3.时间处理问题
写在前面
最近在课余时间主张自己学习一点新技能,并考虑到以后可能经常用得到,于是花了两天时间自学了一点爬虫技巧,在这里简单记录一下自己的历程。
- 系统版本:Windows10 64
- Python版本: 3.7
- 调用库: requests, time, re
三者均为内部库,一般无需另行下载 - 爬取网站:广州市交通信息网
选择这个网站是因为之前看到一篇文章中介绍爬取了该网站的数据进行分析,因此在有先人经验情况下认识到了该网站的可爬性,但本文代码均属原创,如有雷同纯属巧合,转载也请注明出处。
作者学习尚浅,该项目更多为作者学习记录,如对初学者有所帮助倍感荣幸,如有大佬对内容做出批评指正不胜感激。
另外这里推荐一个作者学习爬虫时候看的视频资源,思路清晰且较为通俗易懂,适合简单粗暴的入门:传送门
声明:本文档仅用于学习与交流使用,严禁用于一切商业用途,由此产生的后果本人概不负责。
成果展示
在本部分将主要将学习与实践的成果进行展示,包括代码以及爬取到的数据样例。
常量定义
首先定义常量包括爬取网站url,这里我们爬取广州市交通信息网的路况信息中区域车速信息数据,通过谷歌浏览器获取到请求url,请求头以及代理如下代码所示:
#定义请求参数,包括url,请求头,以及代理
url = 'http://219.136.133.162/gztraffic/GetData.ashx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',}
proxies = {
'http':'http://219.136.133.162/gztraffic/Default.aspx'}
类初始化
类初始化函数,带入上述参数,代码如下:
#初始化类时添加请求参数
def __init__(self, url, headers, proxies):
self.url = url
self.headers = headers
self.proxies = proxies
self.publish_time = () #用于记录时间
车速数据爬取
通过requests库执行urlget请求,注意设置headers,proxies,timeout参数,这会保证你的请求不会出现意外,获取数据后转换编码方式,并利用正则表达式(注意转义字符的使用)获取到我们所需的有用信息并保存在内存中等待下一步处理,具体代码如下:
#请求,获取以及解析车速数据
def speedDataGet(self):
url =self.url
headers = self.headers
proxies = self.proxies
speed_info_list = [] #建立一个存放车速数据的列表
try:
response = requests.get(url, headers=headers, proxies=proxies, timeout=5)
response.encoding = 'utf-8'
data = re.findall('{"zoneStateData":\[(.*?)\],"topCongRoadData"', response.text, re.S)[0] #从爬取到的源码中获取所需车速数据
containers = re.findall('{(.*?)}', data) #获取每一个区域车速文本信息并保留可迭代性质
for container in containers:
speed = float(re.findall('RoadSpeed":(.*?),"PublishTime', container)[0]) #从文本中获取车速信息并转换为float格式
speed_info_list.append(speed) #保存
publish_time = int(re.findall('Date\((.*?)\)', container)[0]) #获取数据时间戳信息
self.publish_time = publish_time/1000 #该网站时间戳信息为毫秒,在这里先改为秒,待下一步处理
except requests.exceptions.RequestException as e:
print(e)
return speed_info_list
数据持久化
完成获取车速数据的部分之后就需要考虑如何将数据保留下来,由于我们获取到的数据目前以列表的形式存储在内存之中,因此只需要处理好数据格式方便后续工作之后简单写入即可,不过首先我们需要解决一下每次或得到数据的时间表示的问题,在爬取过程中我们顺便取得了服务器上的时间戳信息,因此利用time库中的localtime()函数进行转换即可得到我们所熟悉的时间概念,具体代码如下:
#数据写入磁盘
def dataWrite(self, write_path):
speed_data = self.speedDataGet() #获取车速数据列表
if speed_data: #如果成功获取到了数据
date_time = time.localtime(self.publish_time)[:5] #将时间戳转换为当地时间,并保留从年到分钟的信息
data = '' #用于存放待写入数据
for element in date_time: #将时间信息写入data
if element < 10: #为统一格式,将诸如1月或1时改写为01月和01时
data += '0' + str(element) + '/'
else:
data += str(element) + '/'
data = data[:-1] + ';\t' #统一分隔符为';\t'
for element in speed_data: #写入车速数据到data
data += str(element) + ';\t'
with open(write_path, 'a') as f: #写入磁盘
f.write('\n')
f.write(data)
print(date_time) #用于显示成功写入一次数据
else:
print('未获取到车速数据')
爬虫主函数
该部分为爬虫的主函数,外部执行即该函数,包括写入数据前的准备如数据抬头的写入,以及循环发送请求等,具体代码如下:
#爬虫主函数
def spider(self):
write_path = '.\\data.csv' #数据写入路径
areas = ['中心', '越秀', '荔湾', '天河', '海珠', '白云']
data_title = '----/--/--/--/--;\t' #数据头统一格式
for area in areas:
data_title += area + ';\t' #数据头写入
with open(write_path, 'w') as f:
f.write('') #清空文本
f.write(data_title) #写入数据头
while True:
self.dataWrite(write_path) #执行新数据写入程序
time.sleep(300) #由于服务器数据每5分钟更新一次,我们也每隔5分钟请求一次
到这里算法的整体部分就完成了,能够从广州市交通信息网提取到我们所需要的数据并按照我们的要求保存在磁盘之中,获取到的数据样例如下:

写在后面
首先,非常感谢您能够坚持看到这里,本分享的主体部分,包括内容与代码还有结果都在上面了,下面是我在进行本次项目,甚至已经小到可能都算不上一个项目的本次实践的一些心路历程,包括实施的思路以及过程中遇到的问题与解决方法,希望能对刚入门且同样遇到一些问题的你有一些帮助。
1.静态网页爬取
秉承着在实践中学习的原则,作者在简单学习了爬虫的基本原理之后,选择了先对网页的静态内容进行简单的爬取,该过程并没有遇到太大的困难,网络上关于静态网页的爬取的实例与教程也非常多,因此不做赘述。
2.动态网页请求获取
在完成了静态网页的爬取之后,我曾尝试在已爬取的静态网页源码中寻找到我所需的数据,但是我失败了,在网页源码中无法找到数据信息。查找资料后发现是由于动态网页的原理所致,至于具体这里不展开描述且作者也没有完全掌握这一部分知识,不过该部分是进行高阶爬虫必不可少的一部分知识,建议学有余力的同学能够进行深入了解。这里我们只介绍针对本实例的细节:
首先在谷歌浏览器目标网页打开检查选项,选择Network->XHR选项,查看请求发送情况:

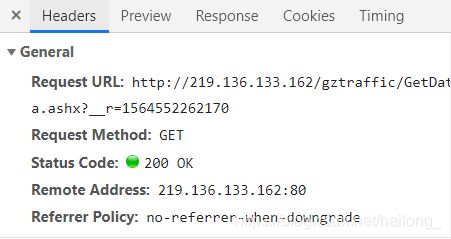
我们观察到有个GetData请求,点击查看headers我们可以发现General选项中有我们所需要的request url内容,即我们所真正需要的动态请求地址:
另:地址中?之后部分为时间戳信息,但不是请求的必要信息,服务器只会按照它的时间戳向你发送信息,因此实际过程中可以去掉
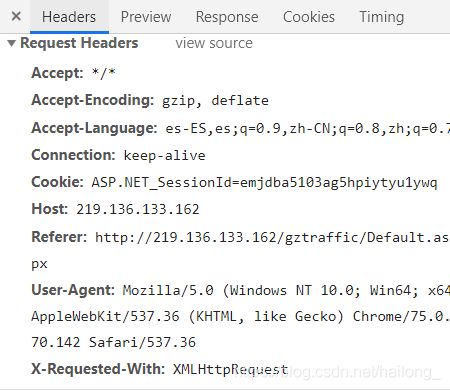
到这里我发现还是不能请求成功,发现原因可能是由于请求头和代理没有设置,同时为避免发生意外需要加上timeout的设置,关于请求头和代理的获取,还是在刚刚的headers选项卡中,向下拉我们可以看到request headers的选项,其中Referer和user-Agent是我们所关心的两项:
3.时间处理问题
到这里,我们对于当下时间服务器所传回的车速数据的爬取可以顺利完成,在解决写入问题时,格式统一是一方面,不过易于解决,只需要细心,但对我造成了一定困扰的是时间格式的转换问题,这时我想到了用time包进行时间格式转换,它其中带的方法可以很方便地将Unix时间戳转化为当地时间,然而返回的是time库中定义的struct_time类,通过查看time的help可以得知该类继承自元组,因此考虑到其同样具有一定的可迭代性质,采用切片方式切取前5项,分别代表:年/月/日/时/分,并保存为我们希望的格式,如代码所示:
date_time = time.localtime(self.publish_time)[:5]
引入time库之后,关于定时循环的问题也同样得到了解决,利用time库中的sleep()函数进行延时,可以很方便地得到我们想要的结果。
至此本篇分享就算是完成啦,希望作为本人学习路上记录的一些点滴,能够为后来之人提供一些捷径。