今天开始对学习的输出,先从经典的数据科学项目入手。
Big Mart Sales prediction 任务目标是根据数据科学家已收集的不同城市10家商店的1559种产品的2013年销售数据。以及数据科学家定义的每个产品和商店的某些属性,预测每个产品在特定商店的销售情况。这篇笔记主要学习了https://www.analyticsvidhya.com/blog/2016/02/bigmart-sales-solution-top-20/?spm=a2c4e.11153940.blogcont603256.10.333b1d6fYOsiOK,这篇文章的分析思路。
分析思路基本是(假设生成—数据探索— 数据清洗—特征工程—模型构建)
1、假设生成 (列举可能影响结果的因素来更好地理解问题)
有关商店的假设:
城市类型:位于城市或一线城市的商店应该有更高的销售额,因为那里的人们收入水平较高。
人口密度:由于需求增加,位于人口稠密地区的商店应该有更高的销售额。
商店容量:规模大的商店应该有更高的销售额,因为人们更喜欢从一个地方获得一切。
竞争对手:附近有类似场所的商店因竞争激烈而销售额较少。
营销:有良好营销部门的商店应该有更高的销售额,因为它将正确的优惠和广告吸引客户。
位置:位于热门市场内的商店应该有更高的销售额,因为更好地接触客户。
客户行为:保持正确产品组合以满足客户本地需求的商店将获得更高的销售额。
氛围:由礼貌和谦逊的人维护良好和管理的商店预计会有更高的客流量,从而提高销售额。
有关产品的假设:
品牌:由于对客户的信任度较高,品牌产品应具有较高的销量。
包装:包装良好的产品可以吸引顾客并销售更多产品。
效用:与特定用途产品相比,日用产品应具有更高的销售趋势。
展示区域:在商店中提供更大货架的产品可能首先引起注意并且销售更多。
商店中的可见性:商店中商品的位置将影响销售。
广告:在大多数情况下,在商店中更好的广告宣传销售应该会更高。
促销优惠:产品附带有吸引力的优惠和折扣将销售更多。
2、数据探索(查看分类和连续的特征并对数据进行推断)
这一节会对数据作基本的探索,并做出一些推论。尝试找出一些异常数据,并在下一节中解决它们。
第一步是查看数据并尝试识别我们假设的信息与可用数据的比较。我们作了15项假设,数据一共有9项特征,其中6项在我们的假设当中,对于数据没有体现的假设,寻找开源数据填补空白也是可行的。
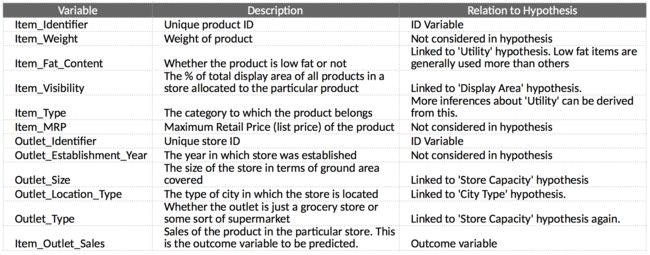
第二步,加载数据集查看数据。这里,将训练数据和测试数据合并进行特征分析,然后在建模的时候再再进行分割。
import pandas as pd
import numpy as np
train = pd.read_csv("train_data.csv")
test = pd.read_csv("test_data.csv")
train['source']='train'
test['source']='test'
data = pd.concat([train, test],ignore_index=True)
print(train.shape, test.shape, data.shape)
# 检查缺失值
data.apply(lambda x: sum(x.isnull()))
# 查看数据统计特征
data.describe()
# 查看每个变量中唯一值的数量
data.apply(lambda x: len(x.unique()))
# 查看每个名义变量中不同类别的频率
categorical_columns = [x for x in data.dtypes.index if data.dtypes[x]=='object']
categorical_columns = [x for x in categorical_columns if x not in ['Item_Identifier','Outlet_Identifier','source']]
for col in categorical_columns:
print('\nFrequency of Categories for varible %s'%col) # Item_Type 可以进行合并
print(data[col].value_counts())
观察数据可以发现:
(1).Item_Visibility的最小值为零。这没有实际意义。
(2).Outlet_Establishment_Years从1985年到2009年各不相同,可以将它们转换为特定商店的年龄.
(3). Item_Weight和Item_Outlet_Sales有缺失值。
(4).Item_Fat_Content:存在编码错误
(5).Item_Type:可以进行结合
3、数据清理 (处理缺失值和异常值)
输入缺失值(Item_Weight 和 Outlet_Size)
# 均值填充Item_Weight
item_avg_weight = data.pivot_table(values='Item_Weight', index='Item_Identifier')
miss_bool = data['Item_Weight'].isnull()
data.loc[miss_bool,'Item_Weight'] = data.loc[miss_bool,'Item_Identifier'].apply(lambda x: item_avg_weight.loc[x])
# mode填充Outlet_Size
from scipy.stats import mode
outlet_size_mode = data.pivot_table(values='Outlet_Size', index='Outlet_Type',aggfunc=(lambda x:mode(x.astype(str)).mode[0]) )
miss_bool = data['Outlet_Size'].isnull()
data.loc[miss_bool,'Outlet_Size'] = data.loc[miss_bool,'Outlet_Type'].apply(lambda x: outlet_size_mode.loc[x])
4、特征工程 (修改现有变量并创建新变量以进行分析)
修正Item_Visibility
# 均值替换0值
visibility_avg = data.pivot_table(values='Item_Visibility', index='Item_Identifier')
miss_bool = (data['Item_Visibility'] == 0)
data.loc[miss_bool,'Item_Visibility'] = data.loc[miss_bool,'Item_Identifier'].apply(lambda x: visibility_avg.loc[x])
添加新特征(Item_Visibility_MeanRatio)
data['Item_Visibility_MeanRatio'] = data.apply(lambda x: x['Item_Visibility']/visibility_avg[x['Item_Identifier']], axis=1)
组合Item_Type
data['Item_Type_Combined'] = data['Item_Identifier'].apply(lambda x: x[0:2])
data['Item_Type_Combined'] = data['Item_Type_Combined'].map({'FD':'Food',
'NC':'Non-Consumable',
'DR':'Drinks'})
data['Item_Type_Combined'].value_counts()
转换为商店的年龄
data['Item_Type_Combined'].value_counts()
data['Outlet_Years'] = 2013 - data['Outlet_Establishment_Year']
data['Outlet_Years'].describe()
修改Item_Fat_Content的类别
data['Item_Fat_Content'] = data['Item_Fat_Content'].replace({'LF':'Low Fat',
'reg':'Regular',
'low fat':'Low Fat'})
数值化和分类变量的独热编码
# 数值化
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['Outlet'] = le.fit_transform(data['Outlet_Identifier'])
var_mod = ['Item_Fat_Content','Outlet_Location_Type','Outlet_Size','Item_Type_Combined','Outlet_Type','Outlet']
le = LabelEncoder()
for i in var_mod:
data[i] = le.fit_transform(data[i])
# 独热编码
data = pd.get_dummies(data, columns=['Item_Fat_Content','Outlet_Location_Type','Outlet_Size','Outlet_Type',
'Item_Type_Combined','Outlet'])
数据导出
#去除已经转换的数据
data.drop(['Item_Type','Outlet_Establishment_Year'],axis=1,inplace=True)
#还原为训练集和测试集
train = data.loc[data['source']=="train"]
test = data.loc[data['source']=="test"]
#去除不需要的列
test.drop(['Item_Outlet_Sales','source'],axis=1,inplace=True)
train.drop(['source'],axis=1,inplace=True)
#导出
train.to_csv("train_modified.csv",index=False)
test.to_csv("test_modified.csv",index=False)
4、模型构建 (对数据进行预测模型)
建立基线
mean_sales = train['Item_Outlet_Sales'].mean()
base1 = test[['Item_Identifier','Outlet_Identifier']]
base1['Item_Outlet_Sales'] = mean_sales
base1.to_csv("alg0.csv",index=False)
定义预测通用框架
#Define target and ID columns:
target = 'Item_Outlet_Sales'
IDcol = ['Item_Identifier','Outlet_Identifier']
from sklearn import model_selection, metrics
def modelfit(alg, dtrain, dtest, predictors, target, IDcol, filename):
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain[target])
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
#Perform cross-validation:
cv_score = model_selection.cross_val_score(alg, dtrain[predictors], dtrain[target], cv=20, scoring= 'neg_mean_squared_error')
cv_score = np.sqrt(np.abs(cv_score))
#Print model report:
print ("\nModel Report")
print ("RMSE : %.4g" % np.sqrt(metrics.mean_squared_error(dtrain[target].values, dtrain_predictions)))
print ("CV Score : Mean - %.4g | Std - %.4g | Min - %.4g | Max - %.4g" % (np.mean(cv_score),np.std(cv_score),np.min(cv_score),np.max(cv_score)))
#Predict on testing data:
dtest[target] = alg.predict(dtest[predictors])
#Export submission file:
IDcol.append(target)
submission = pd.DataFrame({ x: dtest[x] for x in IDcol})
submission.to_csv(filename, index=False)
线性回归模型
from sklearn.linear_model import LinearRegression, Ridge, Lasso
predictors = [x for x in train.columns if x not in [target]+IDcol]
# print predictors
alg1 = LinearRegression(normalize=True)
modelfit(alg1, train, test, predictors, target, IDcol, 'alg1.csv')
coef1 = pd.Series(alg1.coef_, predictors).sort_values()
coef1.plot(kind='bar', title='Model Coefficients')
岭回归模型
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg2 = Ridge(alpha=0.05,normalize=True)
modelfit(alg2, train, test, predictors, target, IDcol, 'alg2.csv')
coef2 = pd.Series(alg2.coef_, predictors).sort_values()
coef2.plot(kind='bar', title='Model Coefficients')
决策树模型
from sklearn.tree import DecisionTreeRegressor
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg3 = DecisionTreeRegressor(max_depth=15, min_samples_leaf=100)
modelfit(alg3, train, test, predictors, target, IDcol, 'alg3.csv')
coef3 = pd.Series(alg3.feature_importances_, predictors).sort_values(ascending=False)
coef3.plot(kind='bar', title='Feature Importances')
随机森林模型
from sklearn.ensemble import RandomForestRegressor
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg4 = RandomForestRegressor(n_estimators=200,max_depth=5, min_samples_leaf=100,n_jobs=4)
modelfit(alg4, train, test, predictors, target, IDcol, 'alg5.csv')
coef4 = pd.Series(alg4.feature_importances_, predictors).sort_values(ascending=False)
coef4.plot(kind='bar', title='Feature Importances')
格局模型的过拟合,欠拟合尝试对模型中的参数进行微调可以改进模型效果。