
本篇主要说一下Koltin分支中的秘密的第一个:Koltin关键字(final/if/for)、运算符(+/-/?:)是如何被识别的?陆续后面还有会3-4篇来介绍其他秘密,文章中提到的代码和其他资料已开源到Android知识体系& Android-Body
人与人之间主要通过语言来进行沟通,那程序之间可以沟通吗?是靠什么进行沟通的?
答案是肯定的,人与人之间的沟通主要是靠语言,程序之间也是可以靠语言沟通的。语言大致分为中文、英文、日文等其目的是统一不同风格的文化进行交流。程序又有C、Python、JAVA、Kotlin等其目的也是不同风格的程序语言与人交流,但是最后都会转化成计算机指令供机器识别、执行。人的语言是多样的又是多变的,之所以多样和多变主要是人和人是不同的,每个人都有自己的思维方式和特点。理解一句话可能有不同的意思但是程序是固定的又是严谨的容不得一丝的错误和漏洞,这也就是程序容易出Bug的原因。比如:
小美:今晚我们约一下
人:约我干嘛?我是不是要穿个西服?做个发型?
程序:滚
程序就是这么高冷,因为他是严谨的你必须告诉他约会的时间、约会的地点、约会要干什么、几个人约会、需要带什么东西、要约会多久、需要带钱吗、今晚还用回家吗等等。我们知道JAVA、Kotlin都是可以运行在jvm之上的,又同时会把语言转化成字节码供机器识别,他们又有各自的特定和风格但是大致是符合语言组成的定义的:词法、语法、语义。Kotlin现在被谷歌主推的有许多官方库和gradle库也都改造成了Koltin的可见其重要性。今天我们就分析下kotlin的主要优势有哪些是如何转化成机器码的。相信大家常听到的话就是知其表不知其里。所有我们分析下Koltin的其里。
Koltin关键字(final/if/for)、运算符(+/-/?:)是如何被识别的?
其实这个问题可以理解为输入的每个字符如何被识别成单词的?简称:词法分析
词法分析:词法分析阶段是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号) -- 百科

可以看到在KtTokens中有我们常见的关键字和运算符还有标识符、访问权限修饰符等等。这里主要扮演的角色是Token流。其实这个就是将所有的Kotlin词法单元一一枚举出来并分组以后,再进行词法分析。可以看到他们并不是单纯的定义字符串,而是通过不同类型的KtToken来创建,但是他们都是继承与IElementType。
public class KtToken extends IElementType {
public KtToken(@NotNull @NonNls String debugName) {
super(debugName, KotlinLanguage.INSTANCE);
}
}
复制代码
IElementType是语法树(AST)节点类型,语法树是什么? 后面再介绍。比较有意思的是可以看到super中接收了两个参数,第一个debugName也就是我们定义的关键字运算符还有标识符之类的,第二个参数则是传入的KotlinLanguage类
public class KotlinLanguage extends Language {
@NotNull
public static final KotlinLanguage INSTANCE = new KotlinLanguage();
public static final String NAME = "Kotlin";
private KotlinLanguage() {
super("kotlin");
}
}
public class KotlinFileType extends LanguageFileType {
public static final String EXTENSION = "kt";
public static final KotlinFileType INSTANCE = new KotlinFileType();
private final NotNullLazyValue myIcon = new NotNullLazyValue() {
@NotNull
@Override
protected Icon compute() {
return KotlinIconProviderService.getInstance().getFileIcon();
}
};
@Override
@NotNull
public String getName() {
return KotlinLanguage.NAME;
}
@Override
public Icon getIcon() {
return myIcon.getValue();
}
}
复制代码
KotlinLanguage extends Language顾名思义是声明Koltin语言,KotlinFileType是定义Koltin文件以 .kt 结尾还有koltin的Icon之类的。在psi.idea目录下。脑洞可以大开一下,我们是不是可以定义自己的语言并且以自己想结尾的文件命名比如.wm ,答案是肯定的。感兴趣的可以实践下。
词法分析器
我们看到在KtTokens中有许多我们熟悉的关键字和运算符比如:null、false、&&、?:。都是我们常用的,在我们输入后他是由多个字符组成的,所以多个字符的组合是不是我们的关键字还是一组无意义的字符那,这时候就用到了词法分析器。
词法分析器:词法分析是将字符序列转换为单词(Token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(简称Lexer),也叫扫描器。 -- 百科
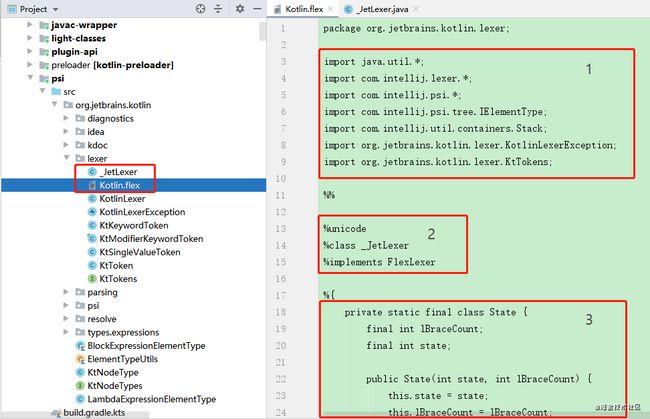
可以看到Koltin使用的开源的词法分析器:JFlex(https://github.com/jflex-de/jflex/)。首先定义一个可以添加词法规则以“.flex”** 结尾的文件。
1 表示用户代码段:这个段中的所有内容将被拷贝到生成的词法类的类声明之前。在这个段中,常见的是 package 和 import 语句。如图我们添加了import java.util.*;、import org.jetbrains.kotlin.lexer.KtTokens;等
2 表示参数设置和声明段:用来定制词法分析器,包括类名、父类、权限修饰符等等,以%开头作为标记。如:%class _JetLexer
3 表示词法规则:一组正则表达式和动作,也就是当正则表达式匹配成功后要执行的代码
定义完后JFlex会读取配置文件并生成一个词法分析器_JetLexer类,如果存在两个正则表达 式"no"和note",扫描器会匹配"note",因为它是最长的。如果两个正则表达式完全 相同,具有相同的长度,那么扫描器将匹配最先列在说明中的表达式。如果没有匹配的正规式,词法分析器将终止对输入流的分析并给出错误消息。
public class KotlinLexer extends FlexAdapter {
public KotlinLexer() {
super(new _JetLexer((Reader) null));
}
}
public class FlexAdapter extends LexerBase {
public void start(@NotNull CharSequence buffer, int startOffset,
int endOffset, int initialState) {
if (buffer == null) {
$$$reportNull$$$0(1);
}
this.myText = buffer;
this.myTokenStart = this.myTokenEnd = startOffset;
this.myBufferEnd = endOffset;
this.myFlex.reset(this.myText, startOffset, endOffset, initialState);
this.myTokenType = null;
}
复制代码
生成的_JetLexer最终被KotlinLexer引用。而KotlinLexer继承于LexerBase,Lexer中有个重要的方法就是start(buffer,startOffset,endOffset),他们分别代表的意思也就是输入的字符、字符开始的偏移量,字符的结束的偏移量。_JetLexer里面是处理各种字符的地方,主要实现的方法是 advance(),会根据输入的字符匹配到自己定义的一些关键字运算符,然后再输出。
总结
知其表也要知其里 综合上面的知识我们就可以得出Koltin关键字(final/if/for)、运算符(+/-/?:)是如何被识别的。大概分为4步输入源、扫描、分析、输出如下:
1、我们在Studio中输入if、final关键字等(简称:输入源)
2、Lexer中的start方法会拿到我们输入的字符串(简称:扫描)
3、_JetLexer的advance方法会根据输入匹配正则(简称:分析)
4、匹配到对应正则后会输出在KtTokens中定义的关键字和运算符等(简称:输出)